



February 28th, the last day of February, also marks the final day of DeepSeek's Open Source Week. On this day, DeepSeek open-sourced two projects: 3FS and Smallpond.
According to the official introduction, the Fire-Flyer File System (3FS) is a parallel file system designed to fully utilize the bandwidth of modern SSDs and RDMA networks.
Achieves an aggregate read throughput of 6.6 TiB/s in a 180-node cluster.
Delivers 3.66 TiB/minute throughput in the GraySort benchmark on a 25-node cluster.
Provides peak throughput of over 40 GiB/s per client node in KVCache lookups.
Features a distributed architecture with strong consistency semantics.
Used for training data preprocessing, dataset loading, checkpoint saving/reloading, embedding vector search, and KVCache lookups in inference for V3/R1.
Smallpond, on the other hand, is a data processing framework built on top of 3FS.
Fire-Flyer File System (3FS)
3FS is part of the Fire-Flyer AI-HPC developed by DeepSeek. It is detailed in the paper Fire-Flyer AI-HPC: A Cost-Effective Software-Hardware Co-Design for Deep Learning.
Fire-Flyer AI-HPC consists of three components: the HAI Platform (open-sourced two years ago), 3FS (open-sourced today), and HaiScale (yet to be open-sourced).

In summary, 3FS has several key features:
High-Performance Design: 3FS is tailored to leverage the high IOPS (input/output operations per second) and throughput of NVMe SSDs, as well as RDMA networks. This design enables it to efficiently handle large-scale data requests, meeting the demands of deep learning and large-scale computing.
System Architecture: The 3FS system comprises four roles: cluster manager, metadata service, storage service, and client. The metadata and storage services periodically send heartbeat signals to the cluster manager to ensure system stability and efficiency. Multiple cluster managers ensure high availability.
Request Control Mechanism: 3FS implements a request transmission control mechanism to alleviate network congestion. Upon receiving a read request, the storage service asks the client for permission to transfer data. This limits the number of concurrent senders, maintaining good performance under high load.
Strong Consistency with Chain Replication: 3FS adopts the Chain Replication and Allocate Query (CRAQ) approach to provide strong consistency. File contents are split into blocks and replicated across a series of storage targets, fully unleashing the throughput and IOPS of all SSDs.
High Throughput: By optimizing batch write and read operations, 3FS achieves write speeds exceeding 10 GiB/s per node, accelerating checkpoint saving and loading, and reducing latency during training.
3FS-KV System: 3FS also supports 3FS-KV, a shared-storage distributed data processing system built on 3FS. It supports key-value storage, message queues, and object storage models, further enhancing system flexibility and performance.
3FS provides robust storage support for deep learning and large-scale computing, effectively meeting demands for high throughput and low latency.
Description from the Paper:



Performance
Peak Throughput
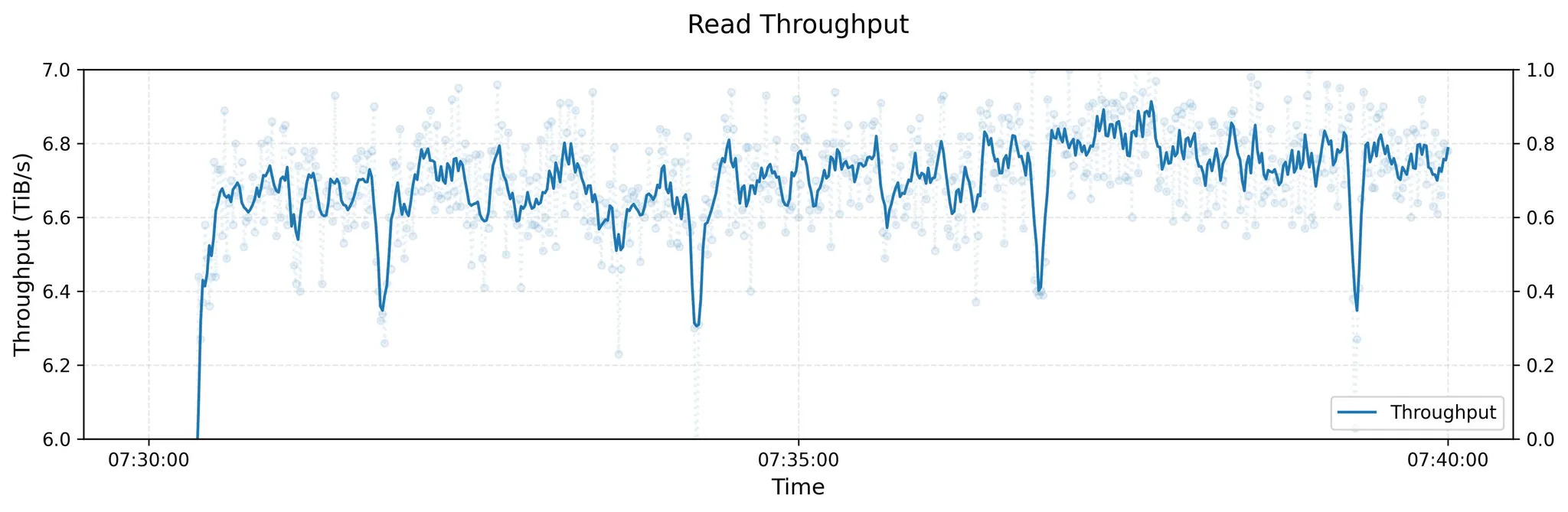
Read throughput test results for a 3FS cluster: The cluster consists of 180 storage nodes, each equipped with 2×200Gbps InfiniBand NICs and 16×14TiB NVMe SSDs. Over 500+ client nodes, each with a 1×200Gbps InfiniBand NIC, were used for the read stress test. Under background traffic from training jobs, the aggregate read throughput reached approximately 6.6 TiB/s.
Sorting Performance
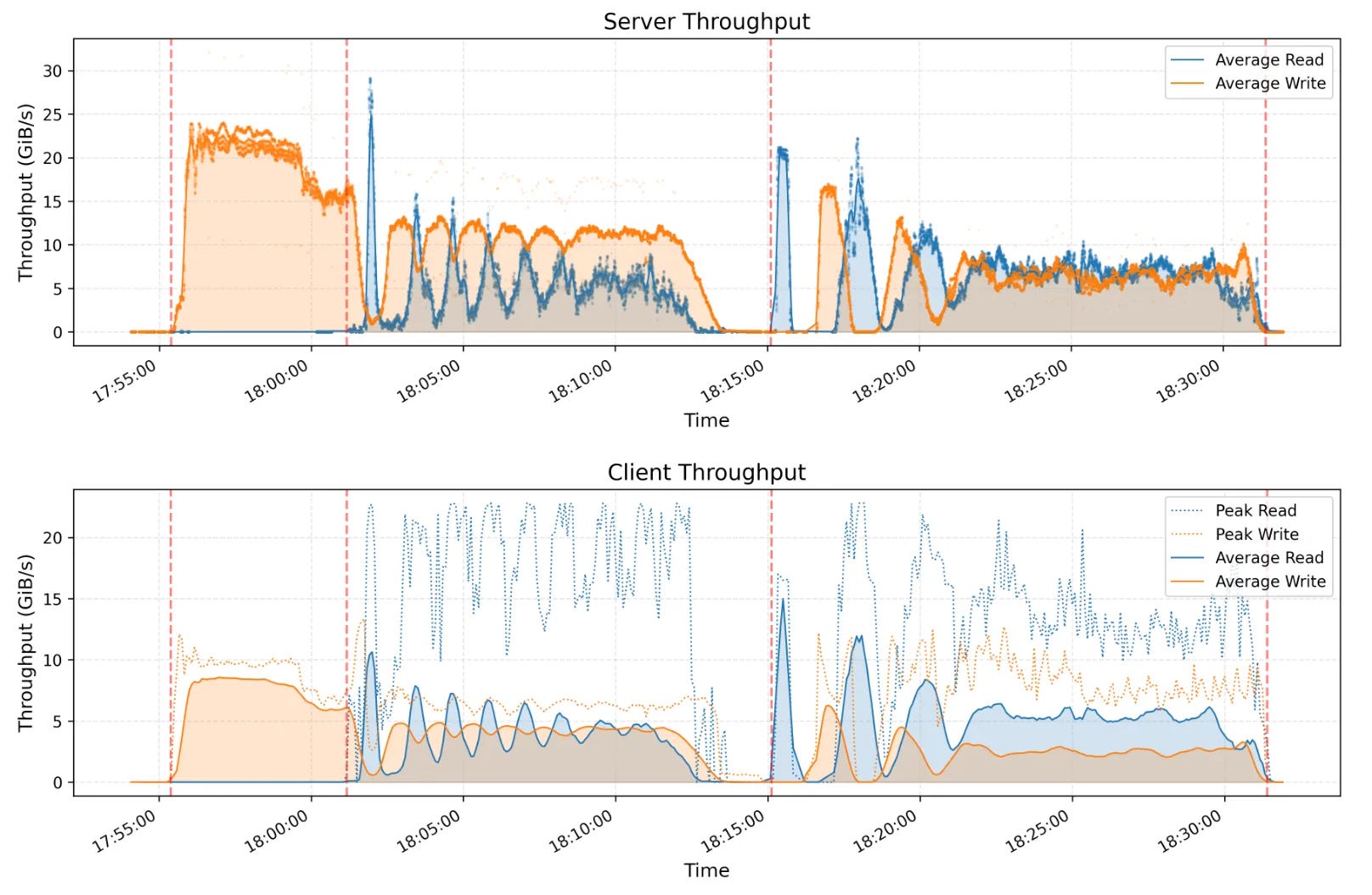
The test cluster consists of 25 storage nodes (2 NUMA domains per node, 1 storage service per NUMA, 2×400Gbps NICs per node) and 50 compute nodes (2 NUMA domains, 192 physical cores, 2.2 TiB RAM, and 1×200Gbps NIC per node). Sorting 110.5 TiB of data across 8192 partitions took 30 minutes and 14 seconds, achieving an average throughput of 3.66 TiB/minute.
KVCache
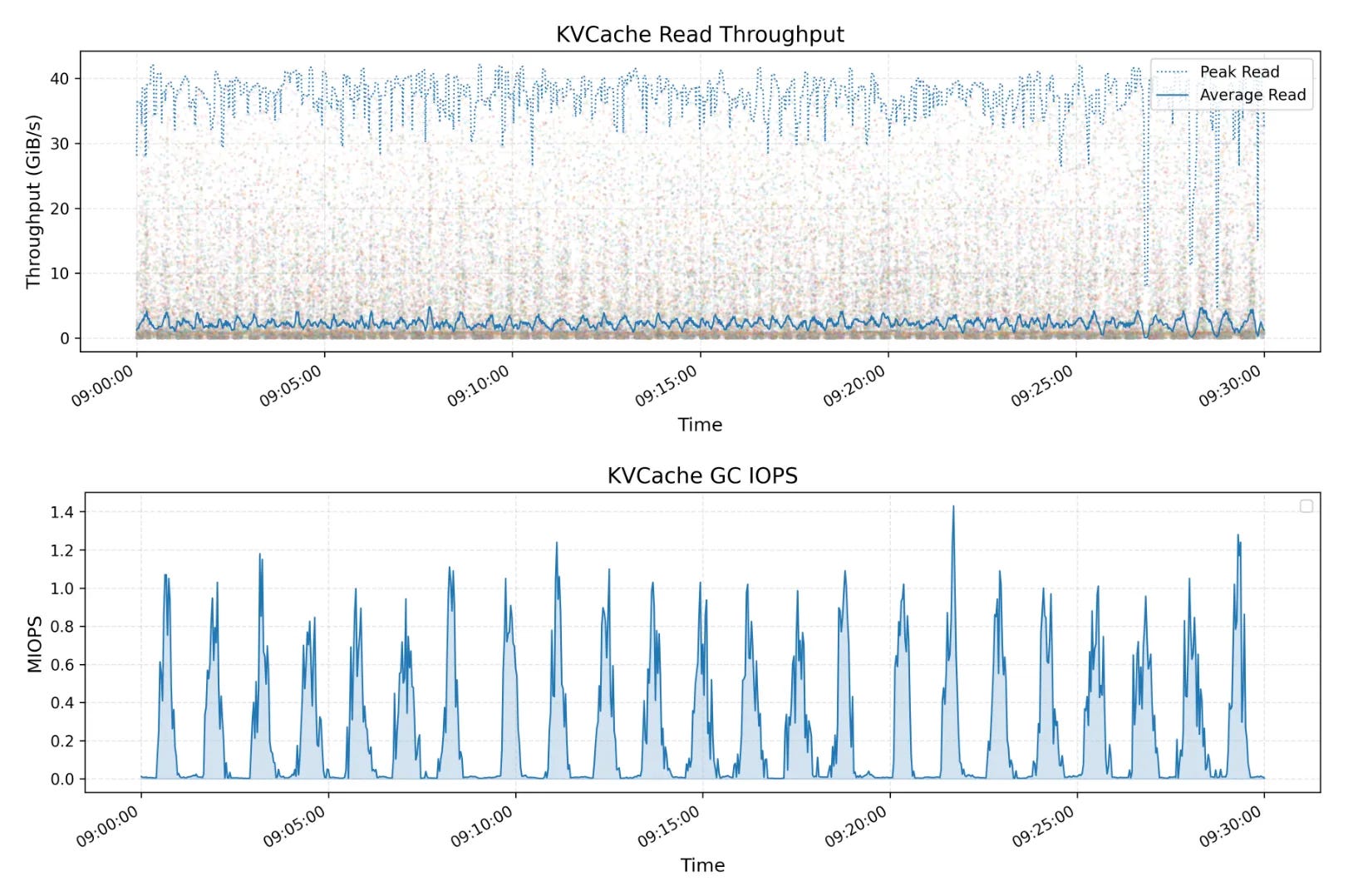
KVCache is designed to optimize the LLM inference process by caching keys and value vectors from previous tokens in the decoder layers, avoiding redundant computation. The figure above shows the read throughput for all KVCache clients, highlighting peak and average values, with a peak throughput of up to 40 GiB/s. The figure below shows the IOPS of delete operations during garbage collection (GC) over the same period.
Why is a Specialized File System Like 3FS Needed?
In LLM scenarios, there’s a need for highly concurrent, high-throughput, and scalable distributed file systems that also demand strong consistency, intelligent routing, and cache management. Systems like 3FS, which offer high-performance solutions tailored for RDMA and SSDs, flexible metadata design, and asynchronous zero-copy I/O, become highly valuable.
Code Analysis
One notable aspect of 3FS’s implementation is that DeepSeek used Rust to develop the chunk_engine.
The chunk_engine is a core module at the bottom layer of the 3FS storage service, responsible for managing, allocating, and reclaiming physical disk blocks. The upper layers can read and write block data through this engine. It primarily uses cxx to automatically generate C++ bindings, allowing C++ code to directly call Rust code.
In recent years, Rust has gained popularity in the MLSys (Machine Learning Systems) field. For example, Hugging Face’s tokenizers are also implemented in Rust. The DeepSeek team likely chose Rust for the chunk_engine due to its maintainability, memory safety, and excellent performance.
The DeepSeek team may also have used the Rust framework Tokio in backend services, as I found several Rust open-source projects, including Tokio, in Quant AI’s open-source initiatives. I sincerely hope more teams adopt Rust for developing machine learning systems.
Smallpond
Smallpond is a lightweight data processing framework built on top of DuckDB and 3FS. It supports lightweight, high-performance data processing and scales to petabyte-scale datasets.
Installation and usage are straightforward, with a minimal API offering two types: one for dynamically building dataflow graphs and another for static construction.
Installation:
pip install smallpondUsage Example:
# Download example data
wget https://duckdb.org/data/prices.parquet
import smallpond
# Initialize session
sp = smallpond.init()
# Load data
df = sp.read_parquet("prices.parquet")
# Process data
df = df.repartition(3, hash_by="ticker")
df = sp.partial_sql("SELECT ticker, min(price), max(price) FROM {0} GROUP BY ticker", df)
# Save results
df.write_parquet("output/")
# Show results
print(df.to_pandas())For performance, refer to the sorting performance of 3FS.
Conclusion of DeepSeek Open Source Week
DeepSeek Open Source Week concludes today. Thank you, DeepSeek, for sharing valuable resources for everyone to learn and use.
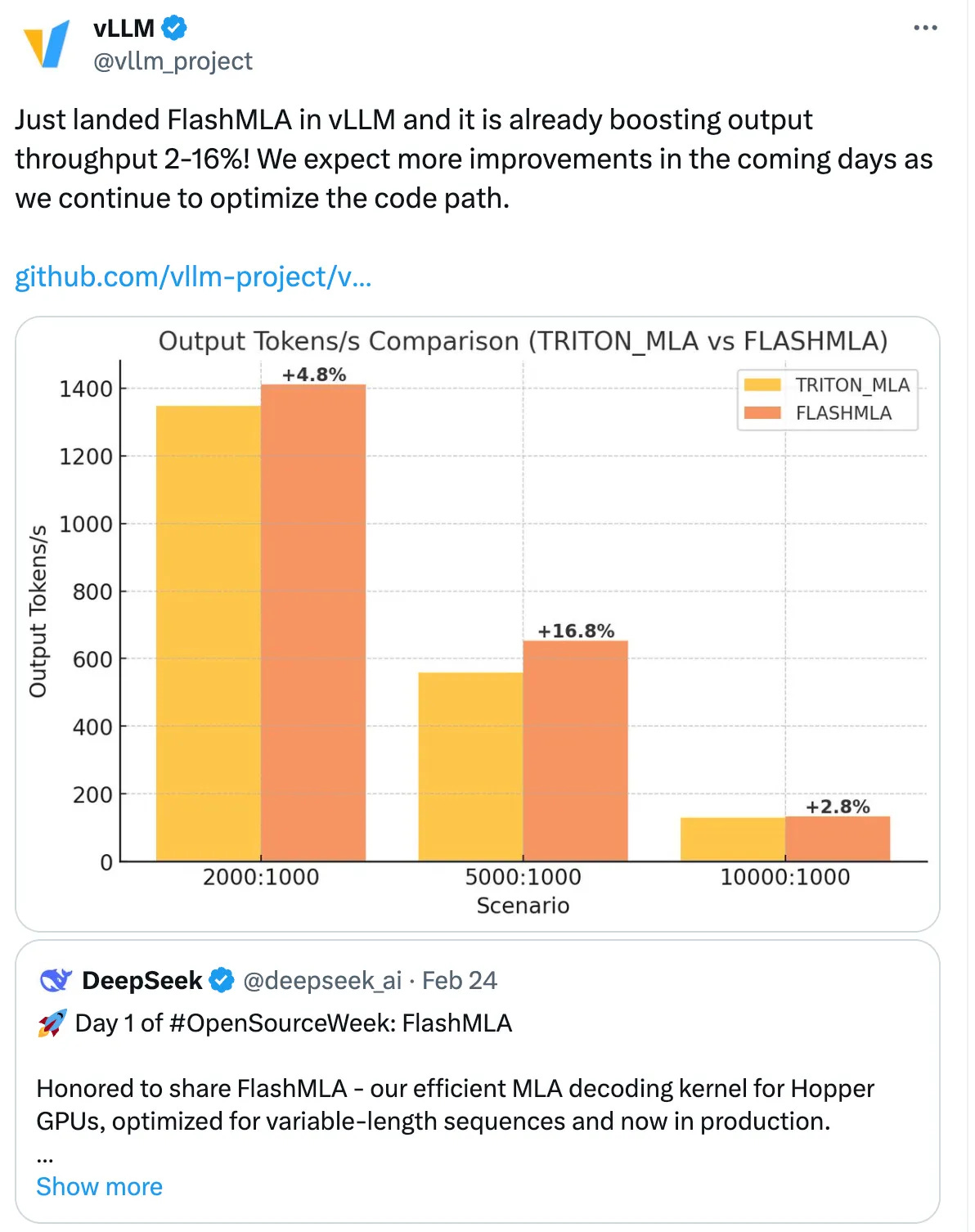
Many teams have already taken action and achieved tangible performance improvements. For instance, the vLLM team replaced TRITON_MLA with FLASHMLA, boosting throughput by 2-16%, delivering real results.
These projects open-sourced by DeepSeek will continue to influence us. Our journey of intense learning continues.
more
day0: https://aigc.openbot.ai/p/deepseek-opensourceweek-is-coming
day1: https://aigc.openbot.ai/p/deepseek-open-source-week-day-1-in
day2:https://aigc.openbot.ai/p/day-2-of-deepseek-opensourceweek
day3:https://aigc.openbot.ai/p/deepseek-opensourceweek-day-3-deepgemm
day4:https://aigc.openbot.ai/p/deepseek-opensourceweek-day-4-in