Today marks the third day of DeepSeek's Open Source Week, with the release of DeepGEMM right on schedule at 9 AM.
As of now, the project has garnered 3.3k stars since its release.
The official introduction describes DeepGEMM as an FP8-supporting GEMM library compatible with both dense and MoE (Mixture of Experts) GEMM operations, designed for training and inference of V3/R1 models.
A Brief Introduction to GEMM
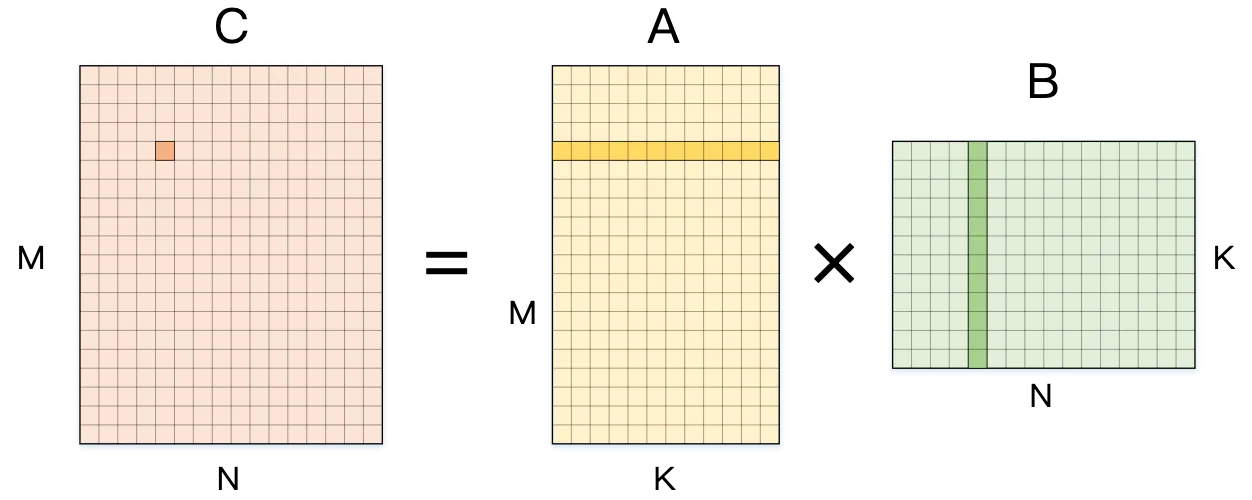
General Matrix Multiplication (GEMM) is one of the most fundamental and critical operations in deep learning and scientific computing. GEMM refers to the multiplication of two matrices, A and B, to produce a result matrix C, typically expressed as C = A × B.
In deep learning, GEMM underpins core components such as fully connected layers, convolutional layers, and attention mechanisms. For instance, in Transformer architectures, both self-attention and feedforward network layers heavily rely on matrix multiplication. As model sizes grow, GEMM operations dominate the computational time in training and inference, making their performance a key factor in the efficiency of deep learning systems.
Modern GPU architectures, like NVIDIA’s Tensor Core technology, are specifically designed to accelerate matrix multiplication. With the ever-increasing scale of models, the demand for high-performance GEMM implementations continues to rise, especially in large language models (LLMs) and MoE frameworks, where efficient GEMM is critical for real-time inference and cost-effective training.
In the paper DeepSeek LLM: Scaling Open-Source Language Models with Longtermism, DeepSeek mentions GEMM, though it ties into their work in another paper, Fire-Flyer AI-HPC: A Cost-Effective Software-Hardware Co-Design for Deep Learning, which introduces the HAI-LLM training system. For those interested, I recommend checking out the Fire-Flyer AI-HPC paper.

Today’s open-sourced DeepGEMM supports FP8 and is tailored for training and inference of DeepSeek’s V3/R1 models. In the V3 paper, DeepSeek details several optimizations for FP8 training.

The main challenges of FP8 training lie in precision and error handling. To tackle these, DeepSeek implemented the following optimizations:
Fine-Grained Quantization: Data is split into smaller groups, each with a specific multiplier to maintain high precision.
Online Quantization: Weights are computed online for each 1x128 activation block or 128x128 weight block, with scaling factors inferred on-the-fly, and activations converted to FP8 in real time.
Improved Accumulation Precision: FP8 accumulation can introduce random errors, so intermediate results are stored in FP32, then converted back after accumulation.
Low-Precision/Mixed-Precision Storage and Communication: For MoE model training, FP8 is mixed with BF16/FP32 to ensure dynamic model stability.
For a detailed look at these optimizations, check out the DeepSeek V3 paper.
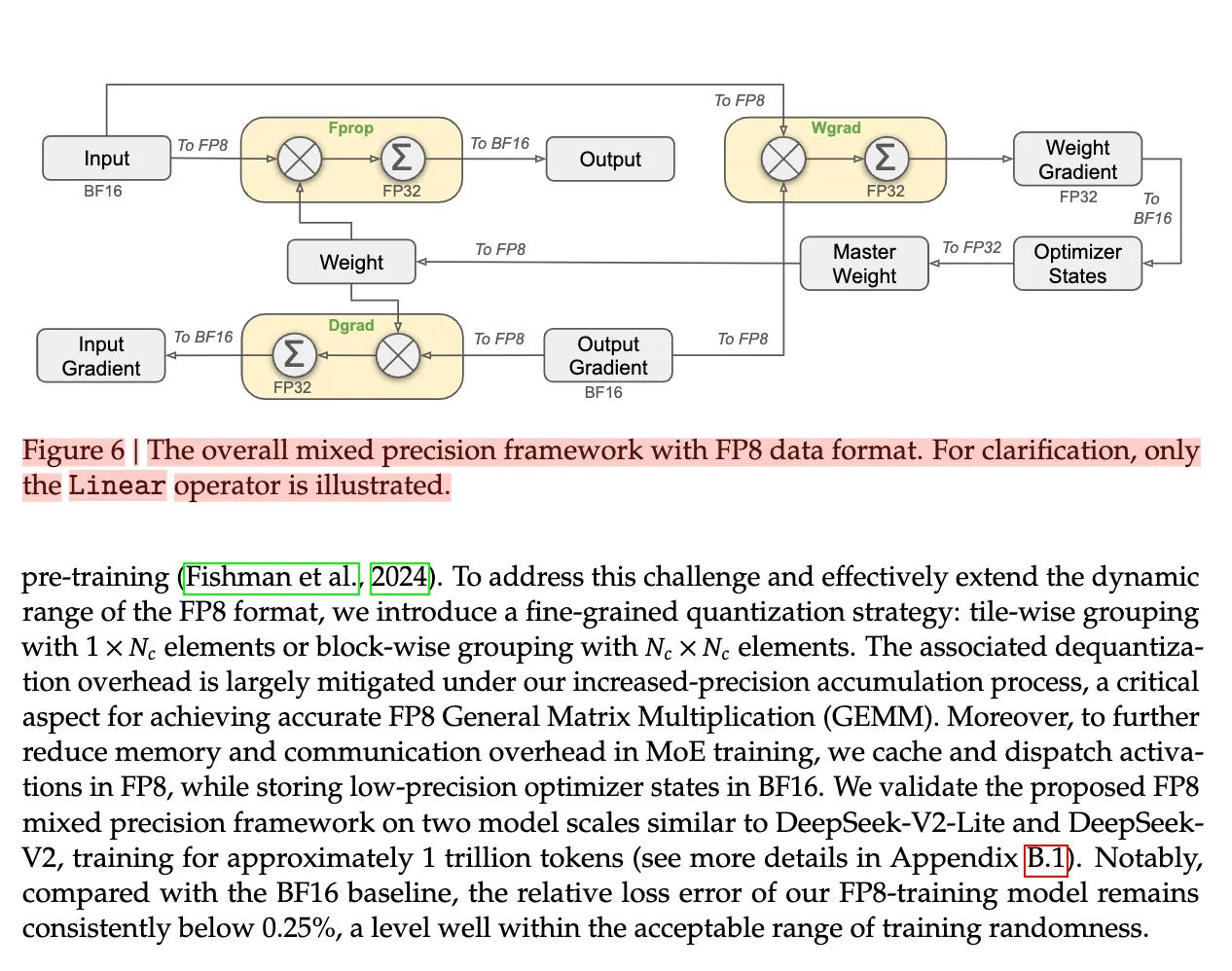
DeepGEMM Overview
Here’s a summary of its key features:
FP8 Support: DeepGEMM uses CUDA’s two-stage accumulation to address precision issues.
Grouped GEMM Support: It improves on CUTLASS’s grouped GEMM, with targeted optimizations for MoE models.
Just-In-Time Compilation: Through JIT technology, code is dynamically generated and optimized at runtime, boosting performance and flexibility.
FFMA SASS Interleaving: DeepSeek analyzed SASS compilation results in depth, tweaking FFMA/FADD instructions to enhance fine-grained FP8 GEMM efficiency.
Performance
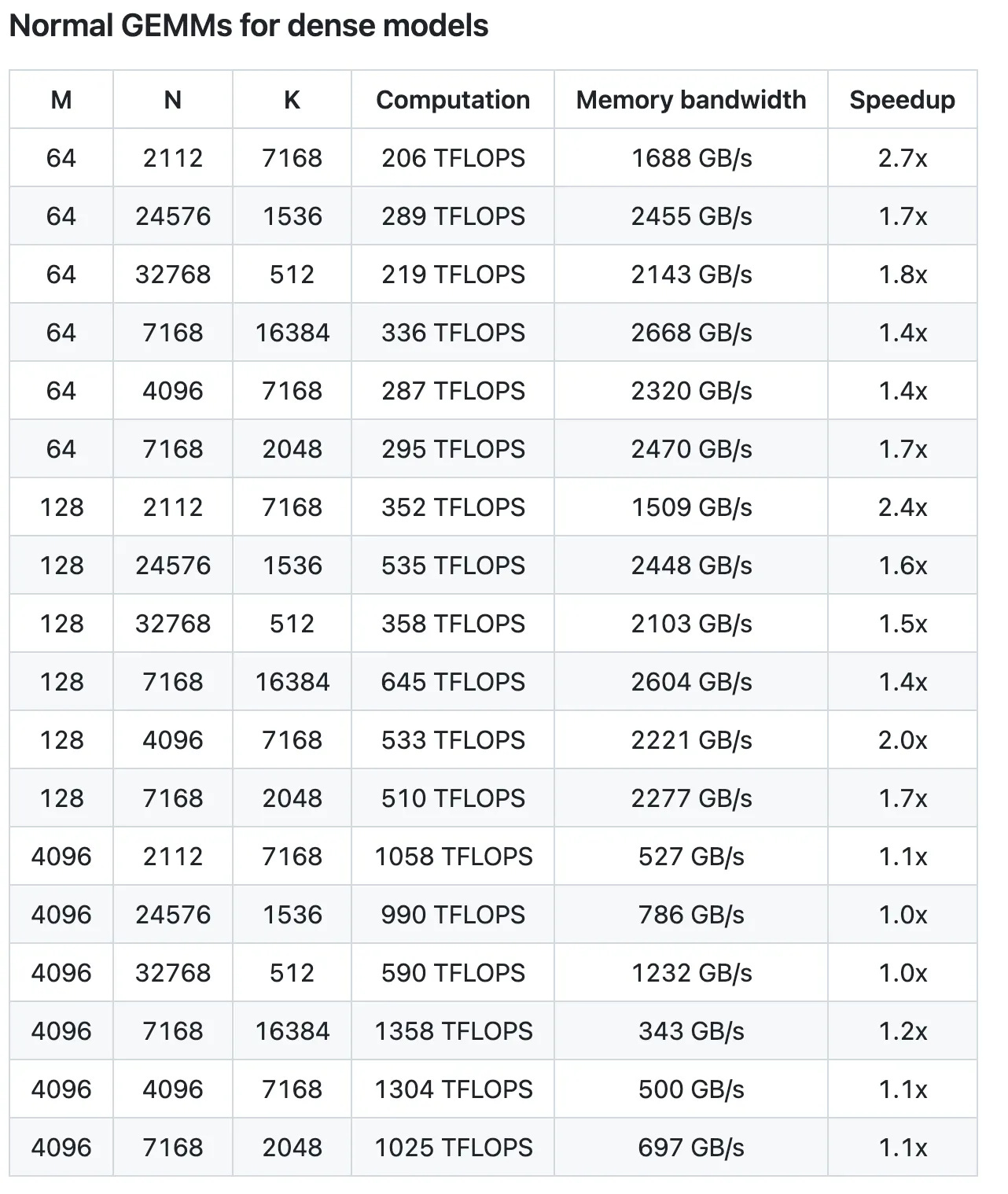
All metrics show improvement, with the highest gain reaching a 2.7x speedup. DeepSeek notes that performance isn’t optimal in some areas and welcomes PRs from those interested in further optimization.
In the DeepGEMM project’s README, the DeepSeek team provides a detailed breakdown of the optimizations. For those interested, it’s worth diving into the code alongside the documentation for a hands-on exploration.
Spotlight: The interleave_ffma.py File
Today, let’s focus on a specific file in the project: interleave_ffma.py under the jit directory. It contains some clever tricks worth exploring.
Here’s the code:
import argparse
import mmap
import os
import re
import subprocess
from torch.utils.cpp_extension import CUDA_HOME
def run_cuobjdump(file_path):
command = [f'{CUDA_HOME}/bin/cuobjdump', '-sass', file_path]
result = subprocess.run(command, stdout=subprocess.PIPE, stderr=subprocess.PIPE, text=True)
assert result.returncode == 0
return result.stdout
def extract_ffma(sass):
lines = sass.splitlines()
collected = []
current = []
arch_name, func_name = 'N/A', 'N/A'
skip_next_line = False
for line in lines:
if 'code for' in line:
arch_name = line.lstrip().lstrip('code for ').rstrip()
elif 'Function :' in line:
func_name = line.lstrip().lstrip('Function :').rstrip()
elif 'FFMA' in line:
current.append(line)
skip_next_line = True
elif skip_next_line:
current.append(line)
skip_next_line = False
else:
if len(current) >= 16:
assert len(current) % 2 == 0
collected.append((f'{arch_name}::{func_name}', current))
current = []
if os.getenv('DG_PRINT_REG_REUSE', None):
print(f"Found {len(collected)} FFMA segments")
return collected
def extract_hex_from_line(line):
match = re.search(r'/\*\s*(0x[0-9a-fA-F]+)\s*\*/', line)
assert match
return int(match.group(1), 16)
def validate(m, offset, le_bytes, num_lines):
assert len(le_bytes) == num_lines // 2
assert m[offset:offset + 16] == le_bytes[0]
for i in range(1, num_lines // 2):
if m[offset + i * 16:offset + i * 16 + 16] != le_bytes[i]:
return False
return True
def parse_registers(line):
import re
line = re.sub(r'/\*.*?\*/', '', line)
line = line.replace(';', '')
tokens = line.strip().split(',')
registers = []
for token in tokens:
token = token.strip()
words = token.split()
for word in words:
if word.startswith('R'):
reg = word.split('.')[0]
registers.append(reg)
return registers
def modify_segment(m, name, ffma_lines):
num_lines = len(ffma_lines)
assert num_lines % 2 == 0
le_bytes, new_le_bytes = [], []
reused_list = []
dst_reg_set = set()
last_reused, last_dst_reg = False, ''
num_changed = 0
for i in range(num_lines // 2):
dst_reg = parse_registers(ffma_lines[i * 2])[-2]
low_line, high_line = ffma_lines[i * 2], ffma_lines[i * 2 + 1]
low_hex, high_hex = extract_hex_from_line(low_line), extract_hex_from_line(high_line)
le_bytes.append(low_hex.to_bytes(8, 'little') + high_hex.to_bytes(8, 'little'))
reused = (high_hex & 0x0800000000000000) != 0
if reused:
is_first_occurred = dst_reg not in dst_reg_set
if is_first_occurred or (last_reused and dst_reg == last_dst_reg):
assert high_hex & 0x0800200000000000, f"{hex(high_hex)}"
high_hex ^= 0x0800200000000000
reused = False
num_changed += 1
else:
reused_list.append(i)
dst_reg_set.add(dst_reg)
new_le_bytes.append(low_hex.to_bytes(8, 'little') + high_hex.to_bytes(8, 'little'))
last_reused, last_dst_reg = reused, dst_reg
if os.getenv('DG_PRINT_REG_REUSE', None):
print(f" > segment `{name}` new reused list ({num_changed} changed): {reused_list}")
offsets = []
offset = m.find(le_bytes[0])
while offset != -1:
offsets.append(offset)
offset = m.find(le_bytes[0], offset + 1)
offsets = list(filter(lambda x: validate(m, x, le_bytes, num_lines), offsets))
for offset in offsets:
for i in range(num_lines // 2):
m[offset + i * 16:offset + i * 16 + 16] = new_le_bytes[i]
def process(path):
if os.getenv('DG_PRINT_REG_REUSE', None):
print(f'Processing {path}')
output = run_cuobjdump(path)
segments = extract_ffma(output)
with open(path, 'r+b') as f:
mm = mmap.mmap(f.fileno(), 0, access=mmap.ACCESS_WRITE)
for segment in segments:
modify_segment(mm, *segment)
mm.close()
if __name__ == "__main__":
parser = argparse.ArgumentParser(description='Interleave FFMA reg reuse')
parser.add_argument('--so', help='Path to the SO file')
args = parser.parse_args()
process(args.so)This file is designed to optimize the register reuse patterns of FFMA (Fused Floating-point Multiply-Add) instructions in CUDA-compiled assembly code by modifying the binary file, ultimately improving GPU instruction execution efficiency.
Key Function Breakdown:
SASS Code Extraction
def run_cuobjdump(file_path):
command = [f'{CUDA_HOME}/bin/cuobjdump', '-sass', file_path]Uses NVIDIA’s cuobjdump tool to extract SASS (assembly) code from the binary.
FFMA Instruction Analysis
def extract_ffma(sass):Extracts segments of SASS code containing FFMA instructions, collecting architecture and function names along with the instruction sequences.
Register Usage Analysis
def parse_registers(line):Parses the registers used in each instruction, identifying those starting with 'R'.
Binary Modification
def modify_segment(m, name, ffma_lines):Modifies the reuse and yield bits of FFMA instructions by tweaking specific bit patterns (e.g., 0x0800200000000000) to optimize register reuse.
Workflow:
Reads a compiled CUDA shared library (.so file).
Extracts SASS code using cuobjdump.
Identifies and collects all FFMA instruction sequences.
Analyzes register usage patterns in each FFMA instruction.
Modifies the reuse flags based on specific rules.
Writes the optimized instructions back to the original file.
Optimization Strategy:
The tool targets:
First-time register usage.
Consecutive reuse of the same destination register.
By tweaking the reuse and yield bits, it optimizes instruction scheduling.
Usage:
python interleave_ffma.py --so path/to/cuda_lib.soAnalysis:
This tool acts as a post-processing optimizer, running after CUDA compilation to enhance GPU instruction efficiency by tweaking the binary. Its focus on FFMA instruction register reuse is particularly impactful for compute-intensive applications like deep learning.
A regex in the file often stumps readers:
def extract_hex_from_line(line):
match = re.search(r'/\*\s*(0x[0-9a-fA-F]+)\s*\*/', line)
assert match
return int(match.group(1), 16)In CUDA SASS assembly, instructions often appear like this:
FFMA R8, R8, R6, R4; /* 0x5c98078000870808 */This regex extracts 0x5c98078000870808, the hexadecimal machine instruction encoding. The function:
Extracts the hex code from the assembly line.
Converts it to an integer for subsequent modification.
This step is crucial for locating instructions, modifying specific bits (e.g., reuse and yield flags), and writing them back.
Honestly, DeepSeek’s engineers seem to outshine even some NVIDIA folks when it comes to CUDA mastery! Oh, and they’ve slashed their API prices again.