On the second day of OpenSourceWeek, the official DeepSeek X account posted an article at 10:24, introducing the second open-source project of Open Source Week: DeepEP.
Since the code was released, it has already garnered 4.3K stars.
Many people are not very familiar with MoE models, so this article will first briefly introduce MoE and some of DeepSeek's work on MoE.
MoE Introduction
The Mixture-of-Experts (MoE) model is a simple extension of the Transformer architecture, rapidly becoming the preferred architecture for medium-to-large-scale language models (2 billion to 600 billion parameters).
Key Advantages:
Faster pre-training speed compared to dense models
Faster inference speed compared to models with the same number of parameters
Challenges:
It requires significant memory since all expert systems need to be loaded into memory. Additionally, as it is typically used for medium-to-large models, it often requires parallel processing across multiple GPUs, and communication must be highly efficient.
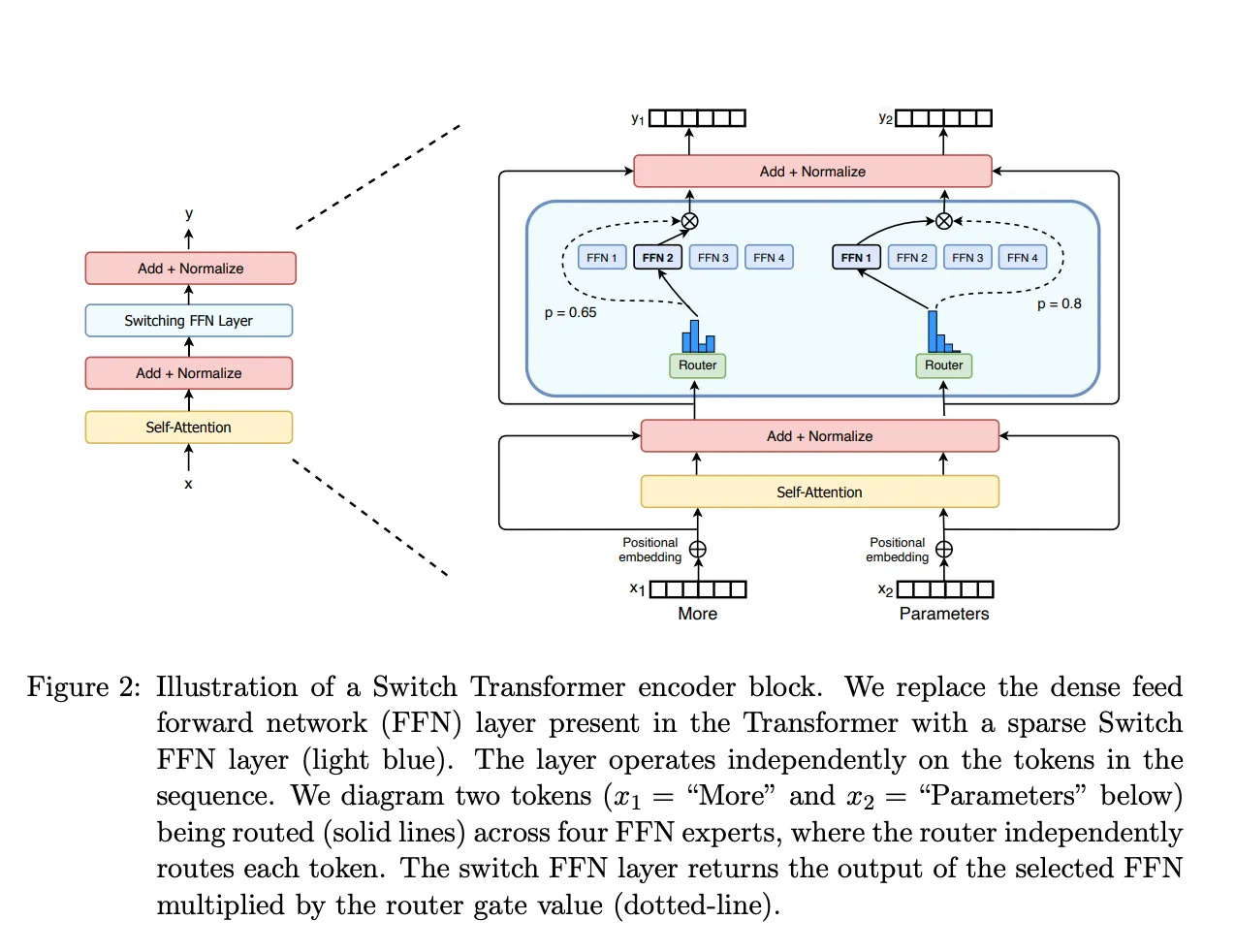
MoE models primarily consist of two key components:
Sparse MoE Layers
These layers replace the feed-forward network (FFN) layers in traditional Transformer models. An MoE layer contains several "experts" (e.g., 8), each of which is an independent neural network.Gating Network or Router
This component determines which tokens are sent to which experts. Sometimes, a token may even be routed to multiple experts.
Summary:
A notable advantage of Mixture-of-Experts (MoE) models is their ability to perform effective pre-training with far fewer computational resources than dense models. This means that, under the same computational budget, you can significantly scale up the model or dataset size. Especially during pre-training, MoE models typically reach the same quality level faster than dense models.
DeepSeek MoE
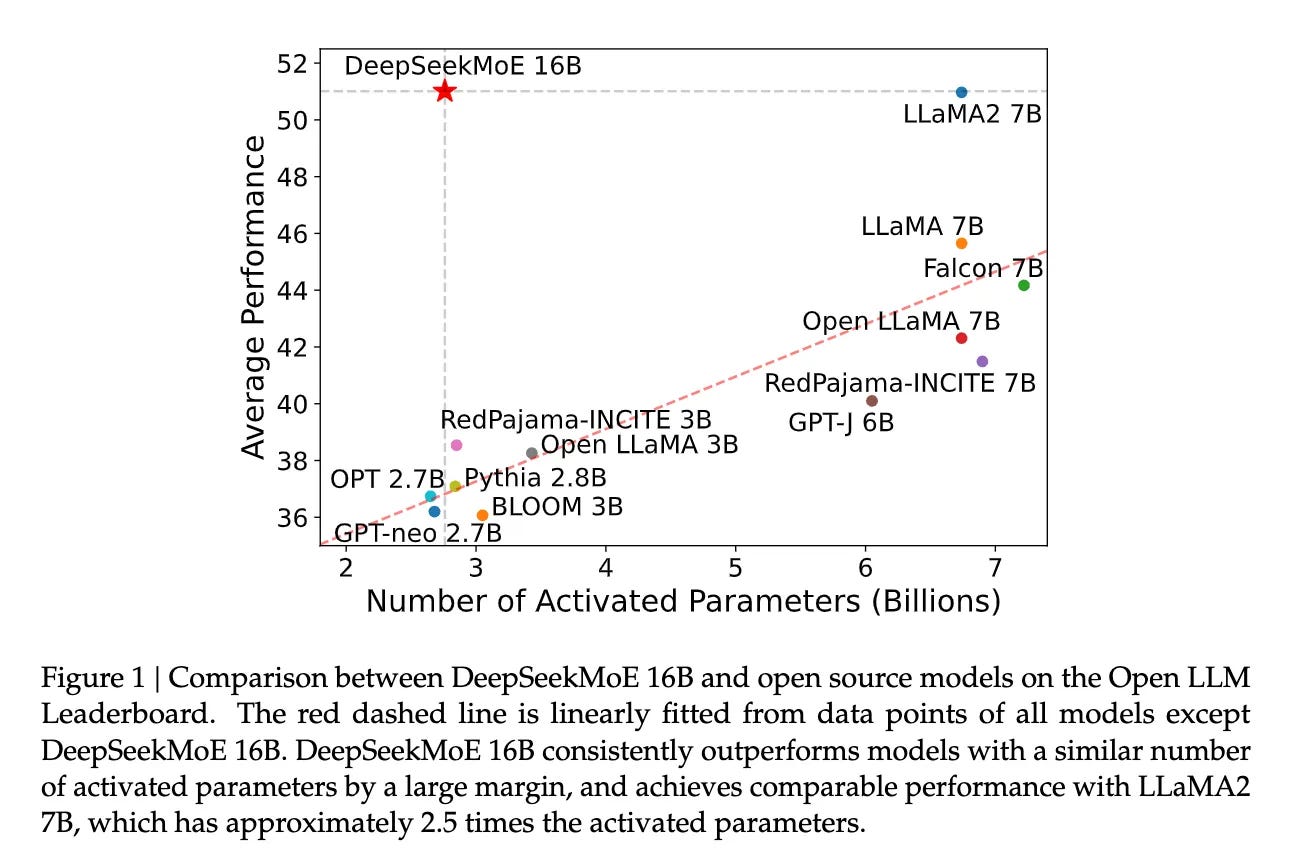
On January 11, 2024, DeepSeek released the paper DeepSeekMoE: Towards Ultimate Expert Specialization in Mixture-of-Experts Language Models, making it one of the earliest companies to research MoE models.
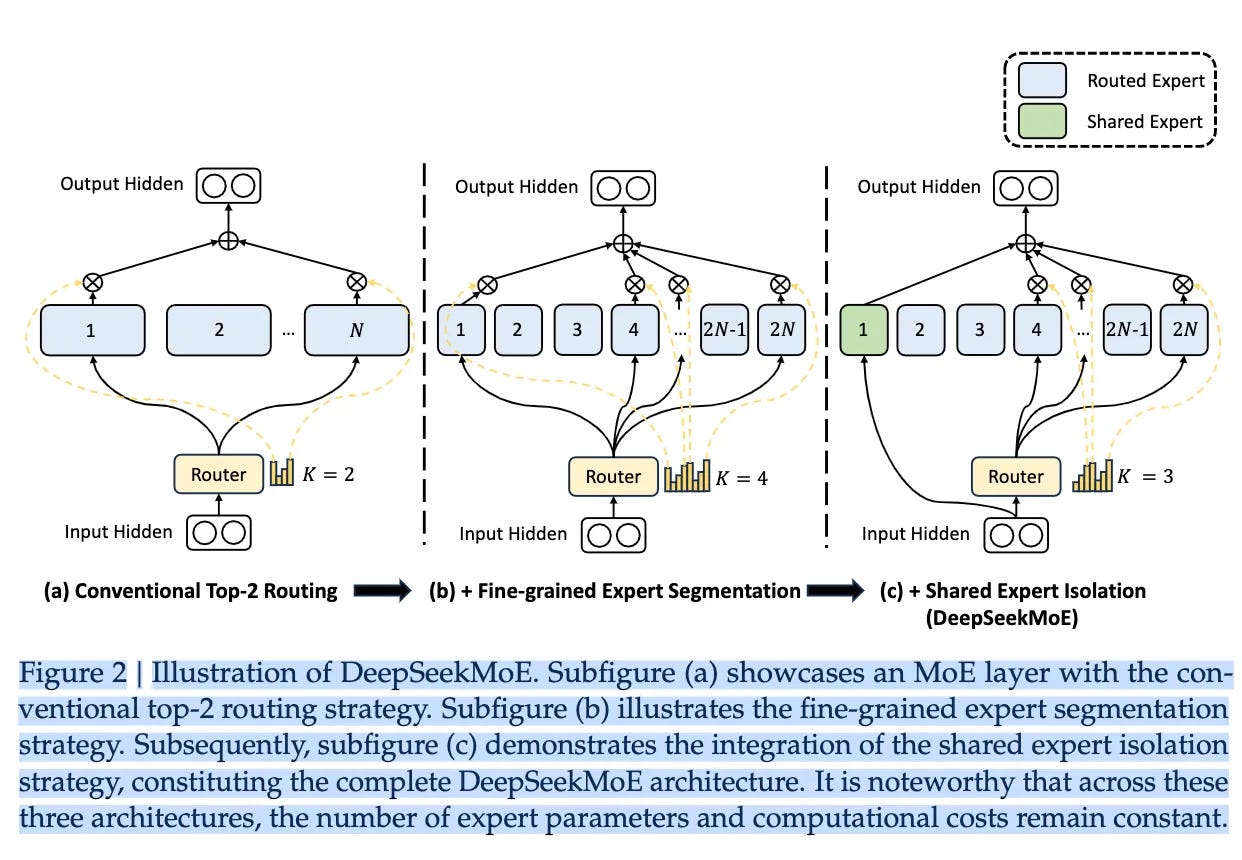
In the DeepSeekMoE paper, the concepts of Router Expert and Shared Expert were introduced, and experiments were conducted on increasing fine-grained experts.
In the paper, DeepSeekMoE 16B has 2 shared experts and 64 router experts per layer, with each token activating 2 shared experts and 6 router experts. The 145B version, on the other hand, has 4 shared experts and 128 router experts, with each token activating 4 shared experts and 12 router experts.

The DeepSeekMoE paper also mentions today’s topic: Expert Parallelism.

In the DeepSeek V3 paper, two paragraphs provide more detailed data. DeepSeek R1 was trained based on V3, and although no further details are provided, it is largely consistent with V3.
DeepEP Introduction
DeepEP is a communication library designed for MoE models and Expert Parallelism (EP). It provides high-throughput and low-latency all-to-all GPU kernels, also known as MoE data dispatch and combine. Additionally, the library supports low-precision operations, including FP8.
To align with the group-limited gating algorithm proposed in the DeepSeek-V3 paper, DeepEP offers a set of kernels optimized for asymmetric domain bandwidth forwarding (e.g., from NVLink domain to RDMA domain). These kernels deliver high throughput, making them ideal for training and inference prefetching tasks. They also support control over the number of Streaming Multiprocessors (SM).
For latency-sensitive inference decoding tasks, DeepEP includes a set of low-latency kernels using pure RDMA to minimize latency. The library also introduces a hook-based method for overlapping communication and computation without occupying any SM resources.
Note: The implementation of this library may slightly differ from the DeepSeek-V3 paper.
Performance
NVLink and RDMA Forwarding Test for General Kernels
We tested general kernels on H800 (NVLink max bandwidth ~160 GB/s), with each device connected to a CX7 InfiniBand 400 Gb/s RDMA NIC (max bandwidth ~50 GB/s). The test followed the pre-training setup of DeepSeek-V3/R1: 4096 tokens per batch, hidden dimension of 7168, top-4 grouping, top-8 experts, FP8 dispatch, and BF16 combine.

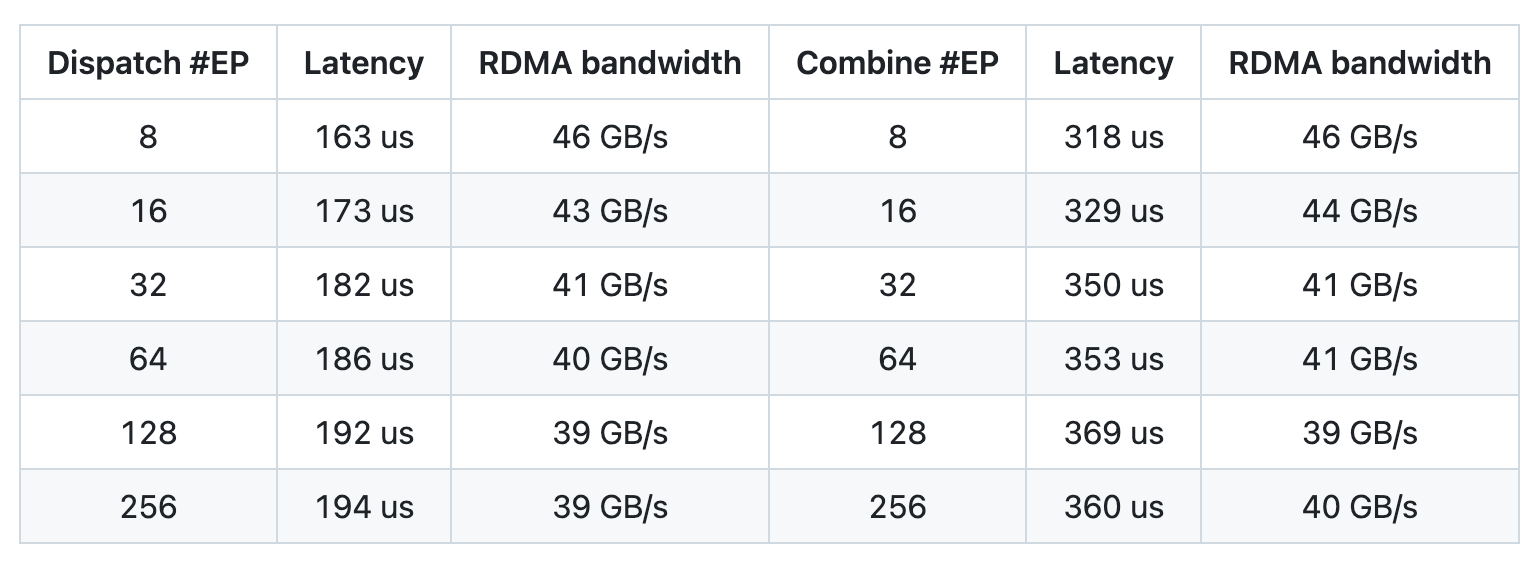
Low-Latency Kernel Test with Pure RDMA
We tested low-latency kernels on H800, with each device connected to a CX7 InfiniBand 400 Gb/s RDMA NIC (max bandwidth ~50 GB/s). The test followed a typical DeepSeek-V3/R1 production environment setup: 128 tokens per batch, hidden dimension of 7168, top-8 experts, FP8 dispatch, and BF16 combine.
Code Analysis
The optimization strategy focuses heavily on low-latency communication. Here, we’ll highlight this aspect, while other features like dynamic scheduling, asynchronous communication, and stream management can be explored in the relevant documentation and code.
Double Buffering
auto buffer = layout.buffers[low_latency_buffer_idx];
auto next_buffer = layout.buffers[low_latency_buffer_idx ^= 1];Alternates between two buffers: one for the current operation, another for the next.
Uses the bitwise operation ^= 1 to efficiently switch buffer indices.
TMA (Tensor Memory Access) Optimization
Leverages the Hopper architecture’s TMA instructions to accelerate data transfer.
Supports low-precision formats like FP8 to reduce communication bandwidth requirements.
IBGDA Direct Communication
// Initialize recv queues for low-latency mode AR
ibgda_initialize_recv_queue<<<num_ranks, 128>>>(rank);Uses NVSHMEM’s IBGDA technology for GPU-direct RDMA communication.
Bypasses CPU involvement entirely to reduce latency.
Expert-Level QP Allocation
_buffer = Buffer(group, 0, num_rdma_bytes, low_latency_mode=True,
num_qps_per_rank=num_experts // group.size())Assigns independent Queue Pairs (QPs) to each local expert, eliminating resource contention.
DeepEP Use Cases
Large-scale MoE model training (e.g., models with hundreds of billions of parameters)
High-concurrency, low-latency real-time inference services
Heterogeneous computing tasks such as multimodal applications and scientific computing
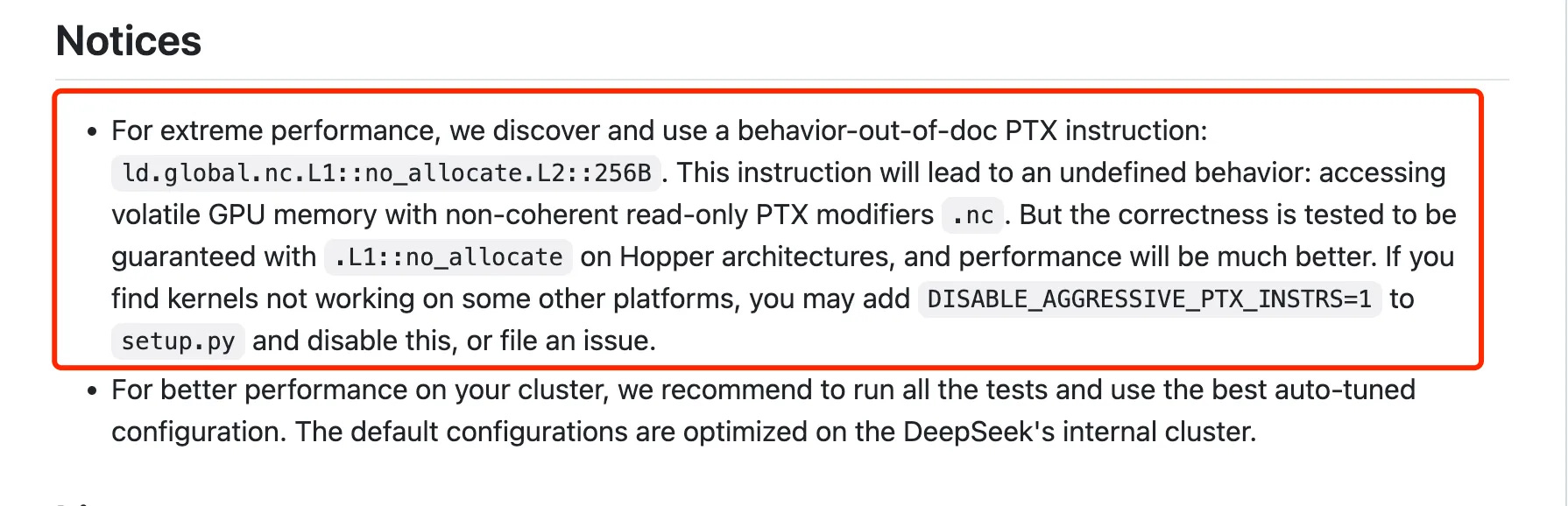
Notably, at the end of the repository, DeepSeek mentions using an undocumented NVIDIA instruction for optimization—a true hacker spirit worth learning from!