





This morning at 9:34, DeepSeek announced the first project of Open Source Week on X: FlashMLA. This article provides an in-depth analysis of FlashMLA.
The FlashMLA project has gained significant popularity, with its code already reaching 6.8k stars.
Brief Introduction to MLA
MLA (Multi-Head Latent Attention) is an optimization method for Multi-Head Attention (MHA) proposed by DeepSeek in their paper DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model.
In Transformer models, MHA is one of the most computationally intensive modules. To maintain high efficiency in large-scale scenarios, further optimization is necessary.
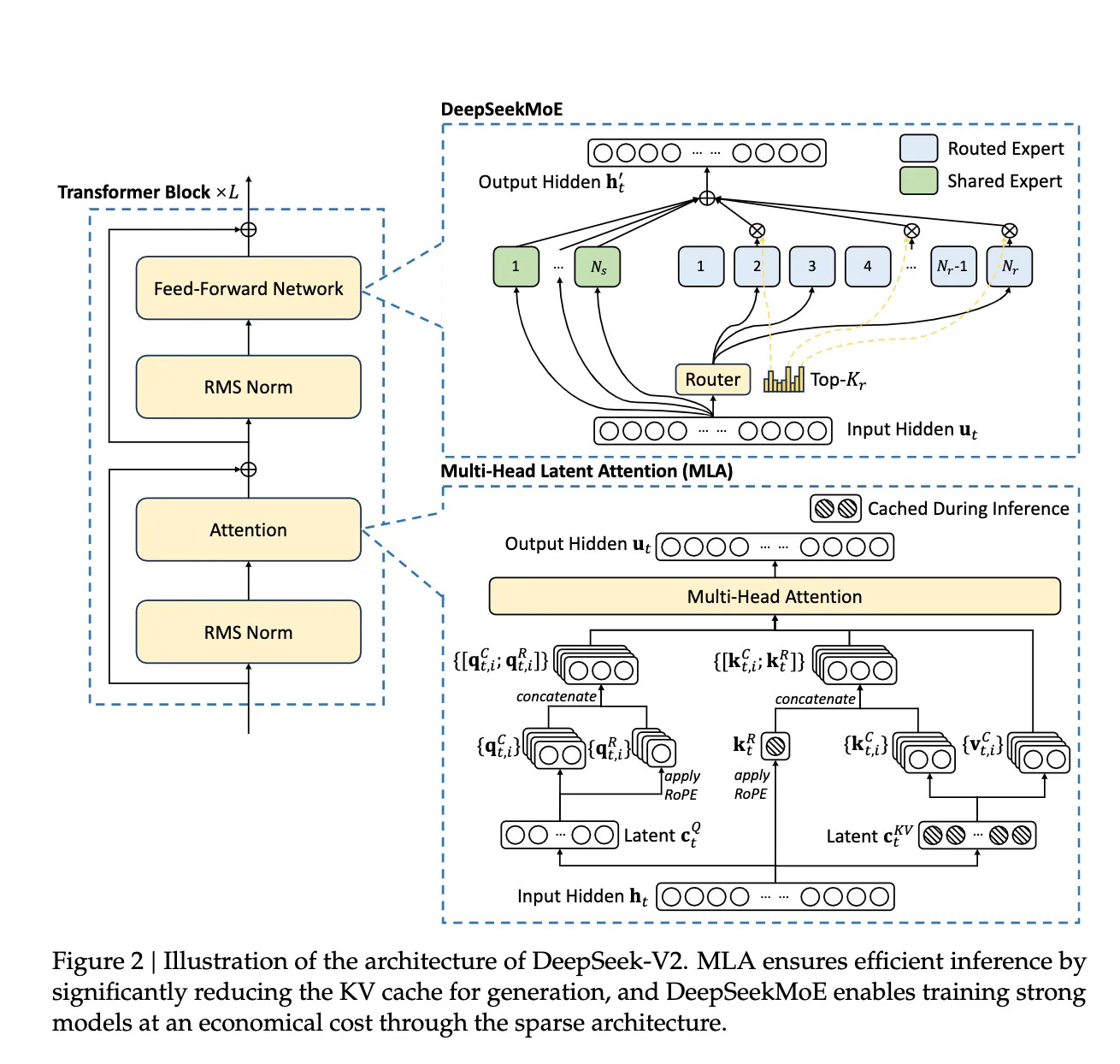
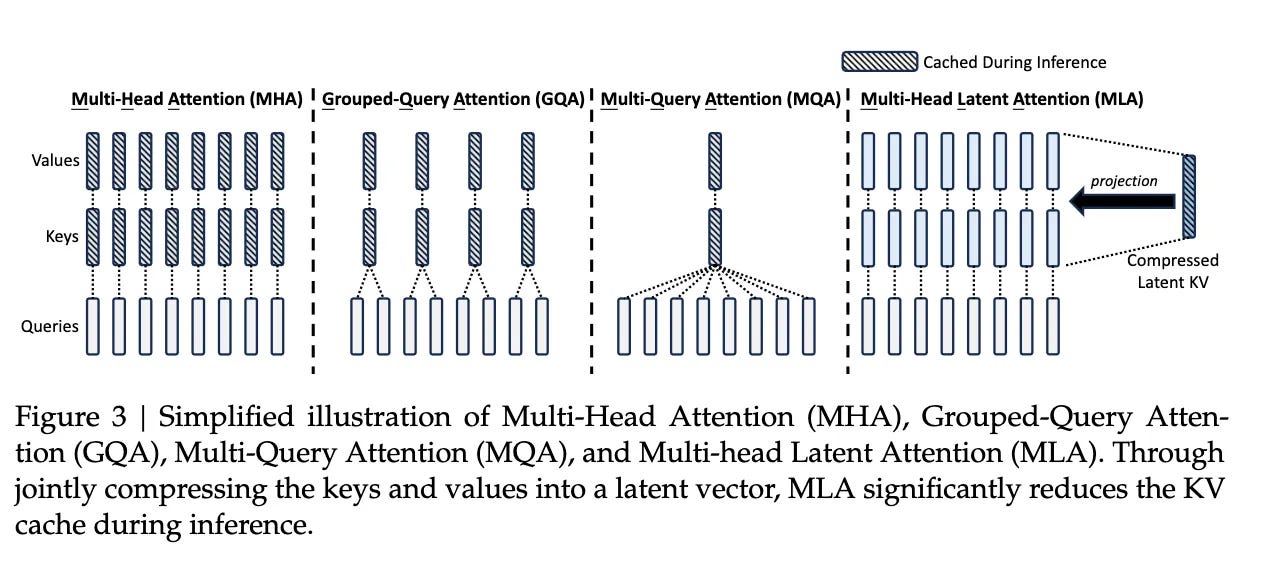
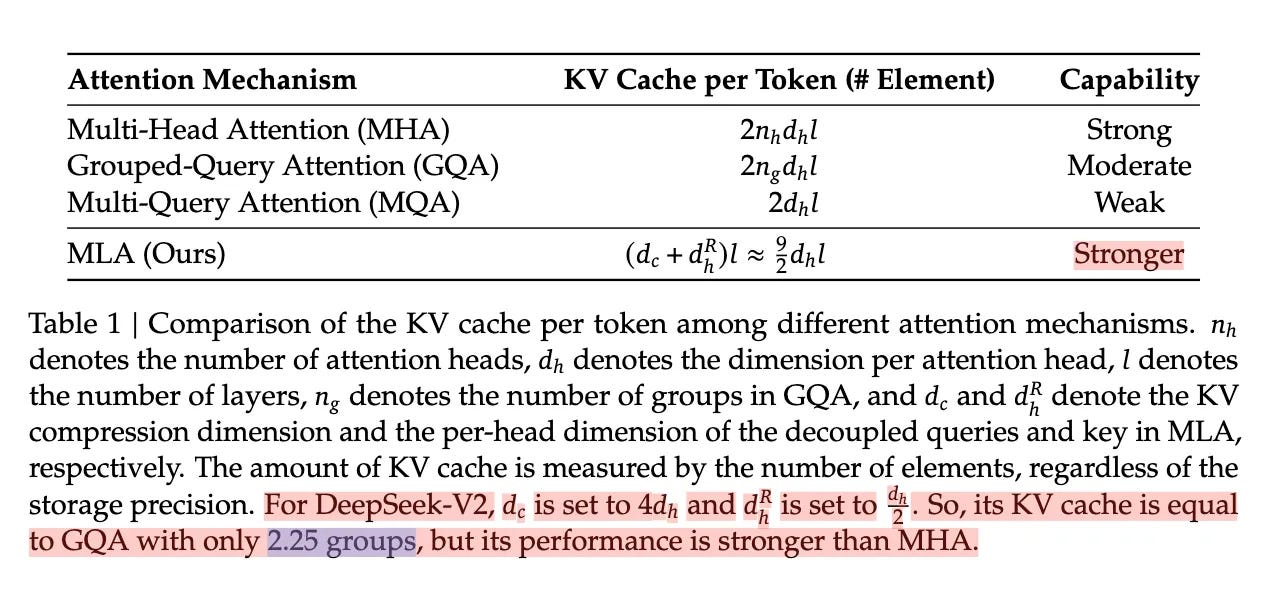
MLA can be considered a variant of MHA. In its implementation, it borrows some concepts from FlashAttention. The DeepSeek-V2 paper primarily compares it with MHA, GQA, and MQA, with optimization results shown in the figure below:
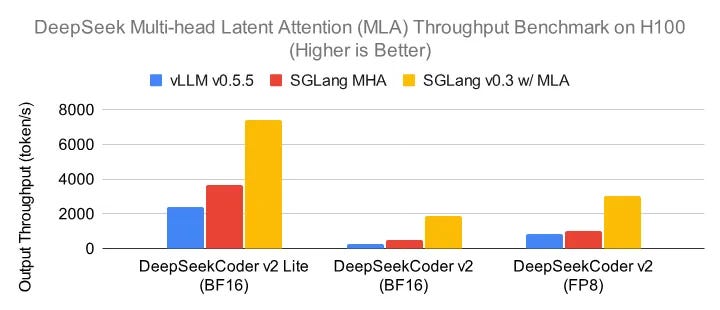
In some inference frameworks, MLA has also been implemented. As shown below, after integrating MLA into SGLang, throughput increased by 2-3 times.
Using FlashMLA
Environment Requirements:
Hopper GPUs
Minimum CUDA 12.3
Minimum PyTorch 2.0
Installation:
git clone https://github.com/deepseek-ai/FlashMLA
python setup.py install 
Performance:
The repository provides a Benchmark file that can be run directly. Official results show that on an H800 SXM5 with CUDA 12.6, it achieves speeds of up to 3000 GB/s under memory-bound configurations and 580 TFLOPS under compute-bound configurations.
Code Analysis
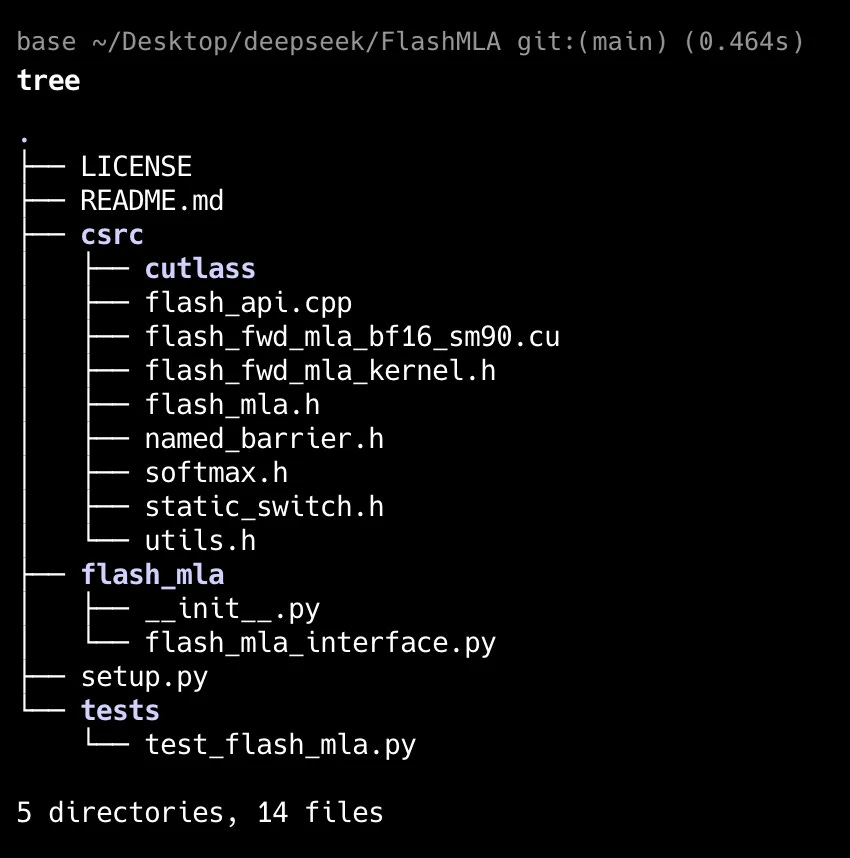
FlashMLA’s codebase is relatively small with minimal dependencies.
The primary optimization techniques are as follows:
1. Computation Chunking and Scheduling Optimization
template<int kHeadDim_, int kBlockM_, int kBlockN_, int kNWarps_>
struct Flash_fwd_kernel_traits_mla {
// Fixed block size of 64x64
static constexpr int kBlockM = kBlockM_;
static constexpr int kBlockN = kBlockN_;
// Each block uses 8 warps in parallel
static constexpr int kNWarps = kNWarps_;
static constexpr int kNThreads = kNWarps * 32;
// Shared memory optimization
static constexpr int kBlockKSmem = kHeadDim % 64 == 0 ? 64 : 32;
};Key Points:
Improves computational efficiency through chunking (block size of 64), paged KV caching, and multi-warp parallelism.
2. Memory Access Optimization
struct Flash_fwd_mla_params {
using index_t = int64_t;
int b, seqlen_q, d, d_v;
int h, h_h_k_ratio, ngroups;
bool is_causal;
float scale_softmax, scale_softmax_log2;
int *__restrict__ cu_seqlens_k;
void *__restrict__ q_ptr;
void *__restrict__ k_ptr;
void *__restrict__ v_ptr;
void *__restrict__ o_ptr;
void *__restrict__ softmax_lse_ptr;
index_t q_batch_stride;
index_t k_batch_stride;
index_t v_batch_stride;
index_t o_batch_stride;
index_t q_row_stride;
index_t k_row_stride;
index_t v_row_stride;
index_t o_row_stride;
index_t q_head_stride;
index_t k_head_stride;
index_t v_head_stride;
index_t o_head_stride;
int *__restrict__ block_table;
index_t block_table_batch_stride;
int page_block_size;
int *__restrict__ tile_scheduler_metadata_ptr;
int num_sm_parts;
int *__restrict__ num_splits_ptr;
void *__restrict__ softmax_lseaccum_ptr;
void *__restrict__ oaccum_ptr;
};Key Points:
Uses paged KV caching (block_table, page_block_size).
Optimized memory layout and access strides (stride).
Scheduling with tile_scheduler_metadata.
3. Softmax Computation Optimization
for (int mi = 0; mi < size<0>(tensor); ++mi) {
MaxOp<float> max_op;
max(mi) = zero_init ? tensor(mi, 0) : max_op(max(mi), tensor(mi, 0));
#pragma unroll
for (int ni = 1; ni < size<1>(tensor); ni++) {
max(mi) = max_op(max(mi), tensor(mi, ni));
}
max(mi) = Allreduce<4>::run(max(mi), max_op);
const float max_scaled = max(mi) == -INFINITY ? 0.f : max(mi) * scale;
sum(mi) = 0;
#pragma unroll
for (int ni = 0; ni < size<1>(tensor); ++ni) {
tensor(mi, ni) = exp2f(tensor(mi, ni) * scale - max_scaled);
sum(mi) += tensor(mi, ni);
}
SumOp<float> sum_op;
sum(mi) = Allreduce<4>::run(sum(mi), sum_op);
}Key Points:
Uses log2/exp2 instead of log/exp.
Optimizes with FFMA instructions.
Warp-level reduction for summation optimization.
4. Double Buffering Optimization
struct SharedStorageMLA {
union {
struct {
// Double buffering for K matrix
cute::array_aligned<Element, cosize_v<SmemLayoutQ>> smem_q;
cute::array_aligned<Element, cosize_v<SmemLayoutK> * 2> smem_k; // Double buffer
cute::array_aligned<Element, cosize_v<SmemLayoutP>> smem_p;
cute::array_aligned<ElementAccum, cosize_v<SmemLayoutRow>> smem_scale;
};
};
};Key Points:
Hides memory latency with double buffering to improve hardware utilization.
Summary of FlashMLA
FlashMLA is essentially a customized version of FlashAttention. Its current applicable scenarios include:
Environments requiring CUDA 11+ and SM90+ Hopper architecture.
Inference or training of multi-head attention with BF16 (Q=576, V=512).
Large-sequence scenarios requiring integration with split-K schemes to boost throughput.
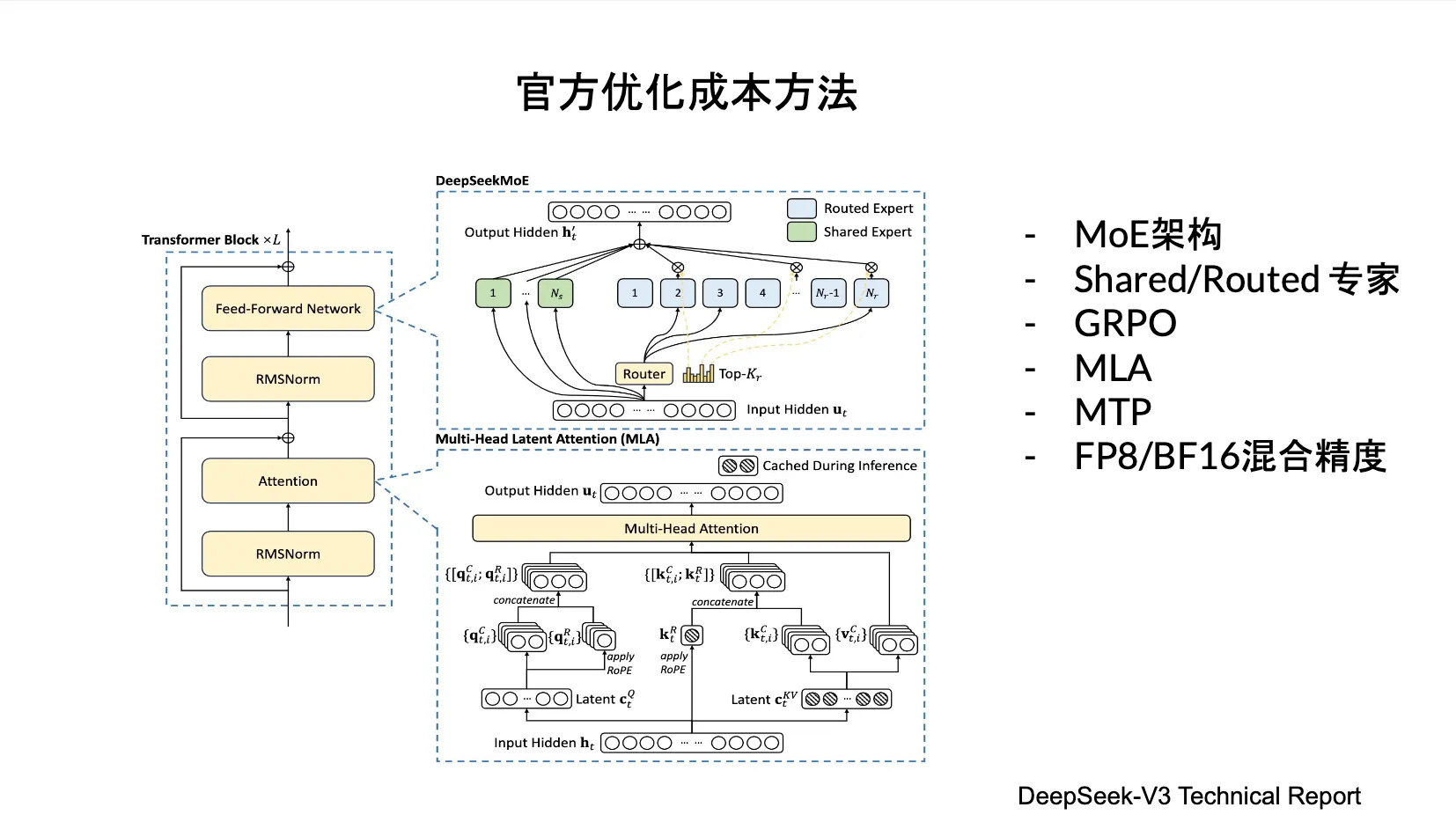
As shown above, there are still many optimization methods from the official team. Looking forward to tomorrow’s project—could it be infra-related? Perhaps something as challenging as MTP?