


DeepSeek OpenSourceWeek Day 6: In-Depth Analysis of DeepSeek-V3/R1 Inference System Overview
deepseek's One More Thing

Today at 12 PM, DeepSeek brought a "One More Thing" to its open-source week, introducing some details and cost calculations about the DeepSeek-V3 / R1 inference system—something you're surely interested in.
Inference System Design Principles
DeepSeek first introduced the design principles of the inference system, with optimization goals focused on: greater throughput and lower latency.
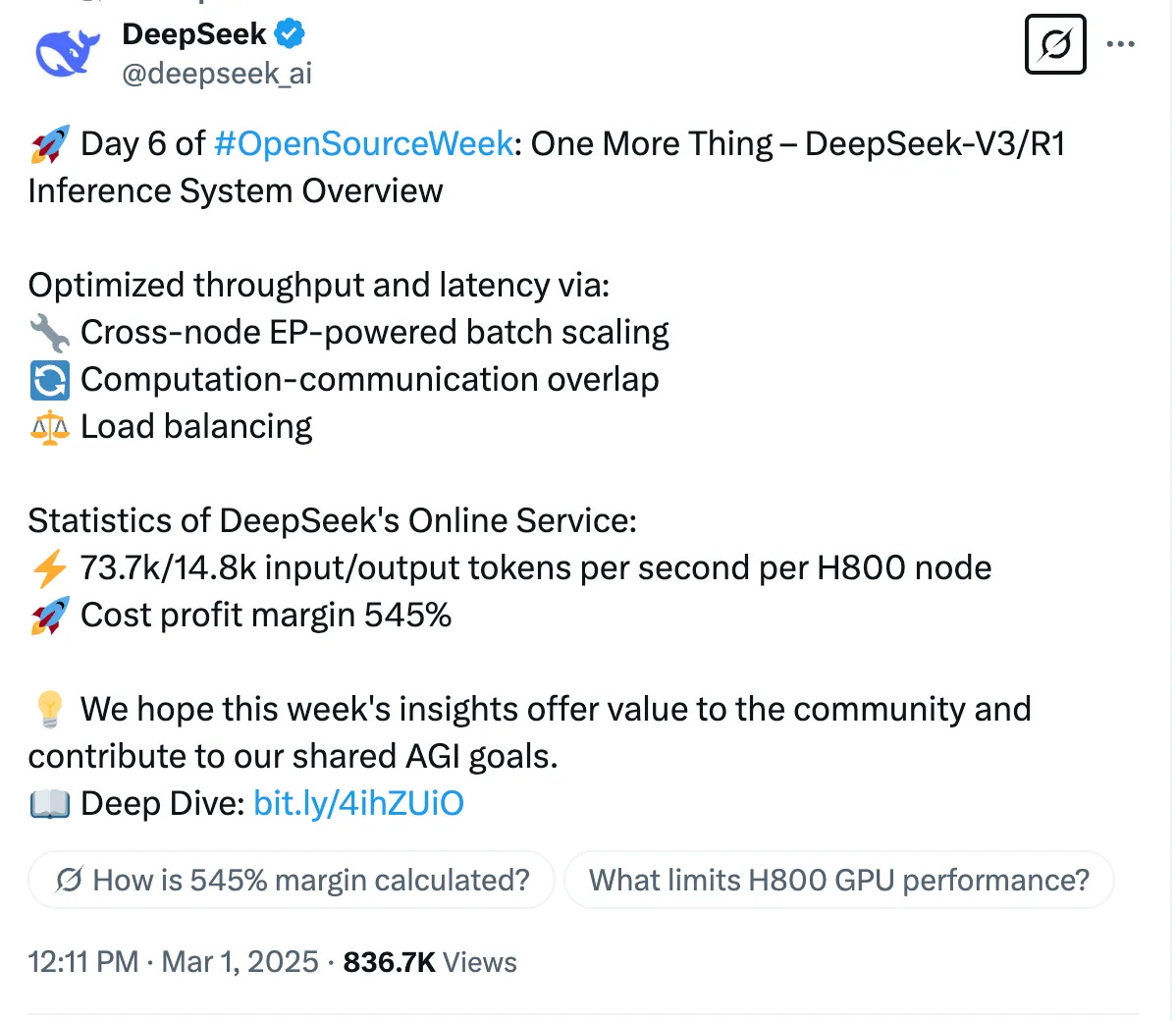
The solution currently adopted by DeepSeek: Large-Scale Node Expert Parallelism (EP)
EP significantly increases batch size, thereby improving the efficiency of GPU matrix multiplication and boosting throughput.
EP distributes experts across different GPUs, with each GPU only needing to compute a small number of experts (thus reducing memory access demands), lowering latency.
Introduced Complexity:
EP introduces cross-node transmission. To optimize throughput, a suitable computation workflow must be designed to allow transmission and computation to occur synchronously.
EP involves multiple nodes, naturally requiring Data Parallelism (DP), with load balancing needed between different DP instances.
Large-Scale Cross-Node Expert Parallelism
DeepSeek employs a multi-machine, multi-card expert parallelism strategy:
Prefill: Router Expert EP32, MLA, and Shared Expert DP32. One deployment unit consists of 4 nodes, 32 redundant router experts, with 9 router experts and 1 shared expert per card.
Decode: Router Expert EP144, MLA, and Shared Expert DP144. One deployment unit consists of 18 nodes, 32 redundant router experts, with 2 router experts and 1 shared expert per card.
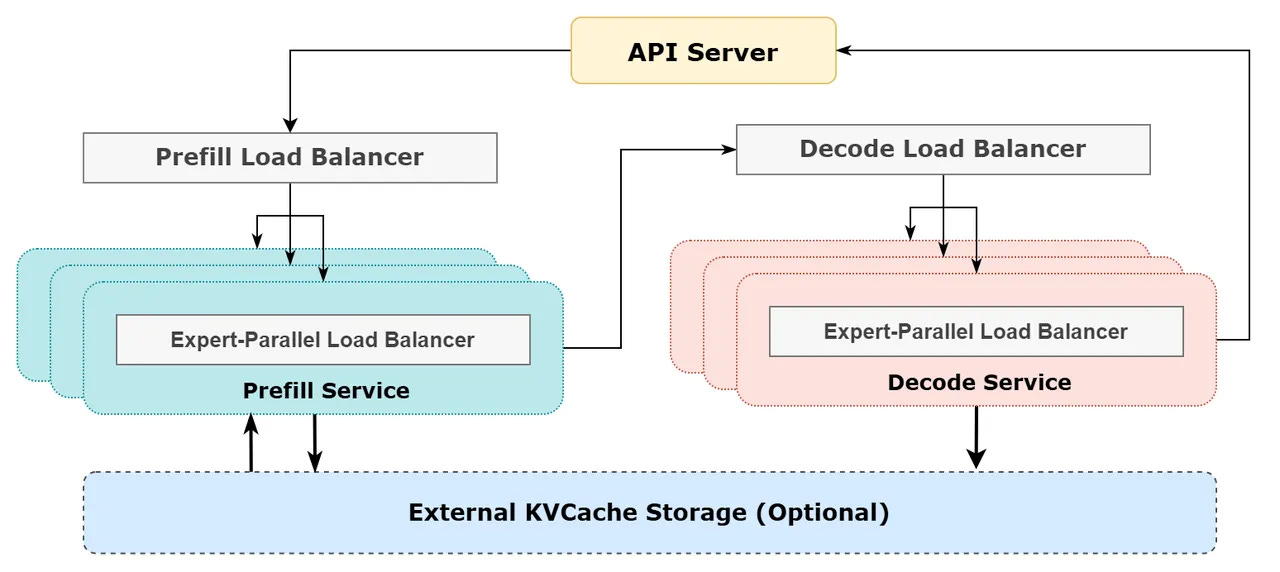
The multi-machine, multi-card expert parallelism introduces significant communication overhead, so dual-batch overlapping is used to mask communication costs and improve overall throughput.
In the prefill phase, computation and communication of two batches are interleaved—one batch’s computation can mask the communication overhead of the other.
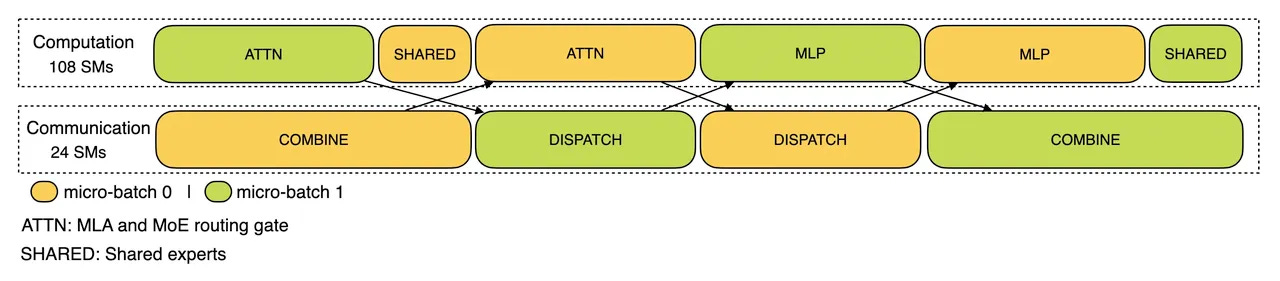
In the decode phase, execution times vary across stages, so the attention part is split into two stages, creating a 5-stage pipeline to overlap computation and communication.
Due to the use of large-scale parallelism (including expert parallelism and data parallelism), some GPUs may become overloaded, necessitating computational and communication load balancing.
Prefill Load Balancer
Core Issue: Variations in the number and length of requests across different Data Parallelism (DP) instances lead to differences in core-attention computation and dispatch transmission volumes.
Optimization Goal: Ensure roughly equal computation load across GPUs (core-attention load balancing) and similar token input volumes (dispatch transmission load balancing) to avoid prolonged processing times on some GPUs.
Decode Load Balancer
Core Issue: Variations in the number and length of requests across DP instances result in differences in core-attention computation (related to KVCache usage) and dispatch transmission volumes.
Optimization Goal: Ensure roughly equal KVCache usage across GPUs (core-attention load balancing) and similar request volumes (dispatch transmission load balancing).
Expert-Parallel Load Balancer
Core Issue: For a given MoE model, certain naturally high-load experts exist, leading to uneven expert computation loads across GPUs.
Optimization Goal: Balance expert computation across GPUs (i.e., minimize the maximum dispatch reception volume across all GPUs).
Real-World Statistics of the Online Inference System
All DeepSeek R1/V3 services use H800 GPUs. Matrix computations and dispatch transmissions use FP8 format consistent with training, while core-attention computations and combine transmissions use BF16 consistent with training, maximizing service performance.
Since service loads are high during the day and low at night, all servers handle inference during peak load times, while some machines are freed up for research and training during low-load periods.
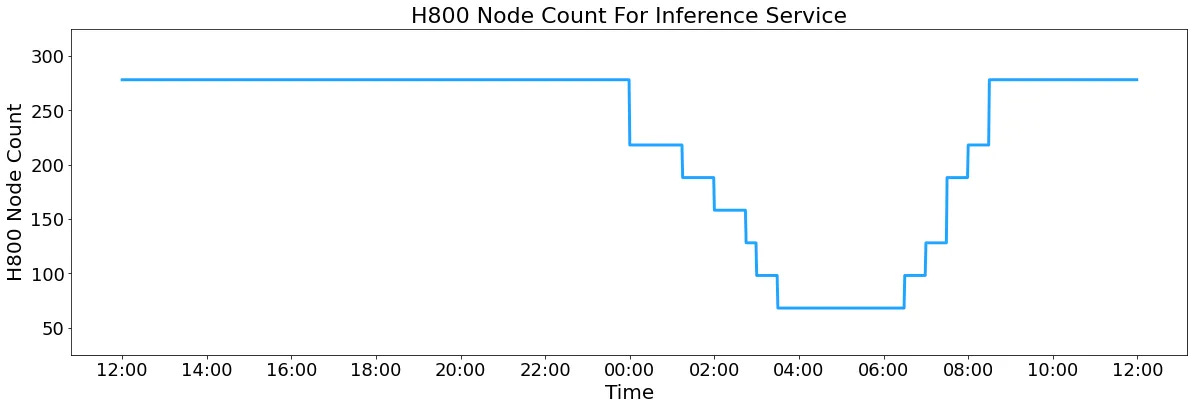
Over the past 24 hours (Beijing time, 2025/02/27 12:00 to 2025/02/28 12:00), the total node usage for DeepSeek V3 and R1 inference services peaked at 278 nodes and averaged 226.75 nodes (each node with 8 H800 GPUs). Assuming a GPU rental cost of $2/hour, the total daily cost is $87,072.
Within this 24-hour statistical period, DeepSeek V3 and R1 recorded:
Total input tokens: 608 billion, of which 342 billion tokens (56.3%) hit the KVCache disk cache.
Total output tokens: 168 billion. The average output rate was 20–22 tokens per second (tps), with an average KVCache length of 4,989 per output token.
Average throughput per H800 GPU:
For prefill tasks: ~73.7k tokens/s input throughput (including cache hits).
For decode tasks: ~14.8k tokens/s output throughput.
These statistics encompass all loads from web, app, and API usage. If all tokens were priced according to DeepSeek R1’s rates, the theoretical daily revenue would be $562,027, yielding a cost-profit margin of 545%.
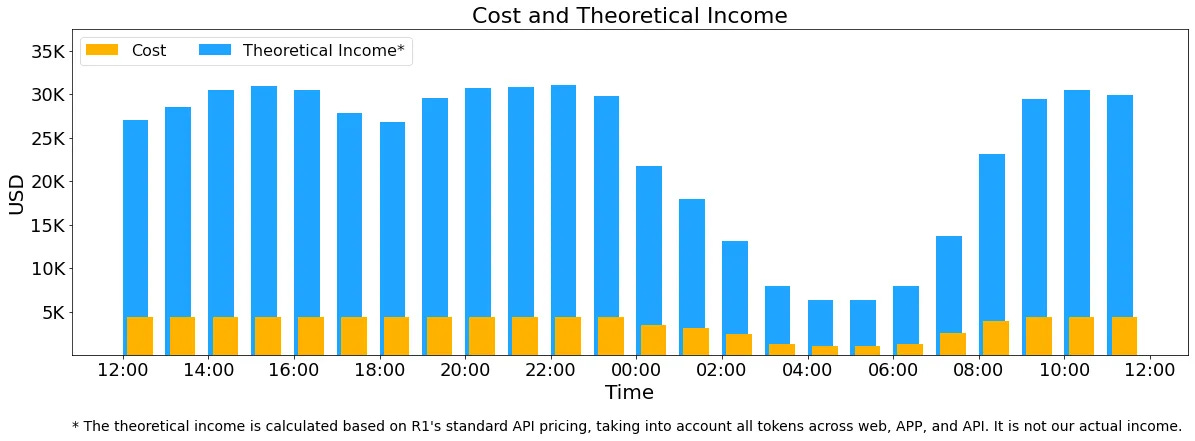
In reality, DeepSeek doesn’t generate this much revenue because V3’s pricing is lower, paid services only account for a portion of usage, and discounts are offered at night.
What Can We Infer?
Rumors previously suggested that DeepSeek’s official deployment consisted of a 320-H800 inference cluster. Now, it appears to be 278 nodes—2,224 H800s. Officially, DeepSeek acknowledges owning at least 10,000 H800s, meaning the GPUs used for inference are relatively few.
Cost: Average of 226.75 nodes (1,814 GPUs), at $2/hour per GPU, yields a daily cost of $87,072.
Revenue: Input: 608B tokens; Output: 168B tokens, resulting in a daily revenue of $562,027.
Gross Daily Profit: $474,955 = ~3,457,672.4 RMB/day.
However, the above calculation has flaws. Even if the 6x profit margin is halved to 3x, the profit margin remains very high. Many domestic vendors deploying DeepSeek have shut down API services due to losses, raising questions about where the problem lies.
In an interview, Liang Wenfeng said: “We just do things at our own pace, then calculate costs and set prices. Our principle is not to lose money.”
This suggests DeepSeek is currently profitable, with earnings likely reinvested into R&D. We look forward to R2’s release soon.