



Daily Papers
1.Mixtral of Experts ( paper )
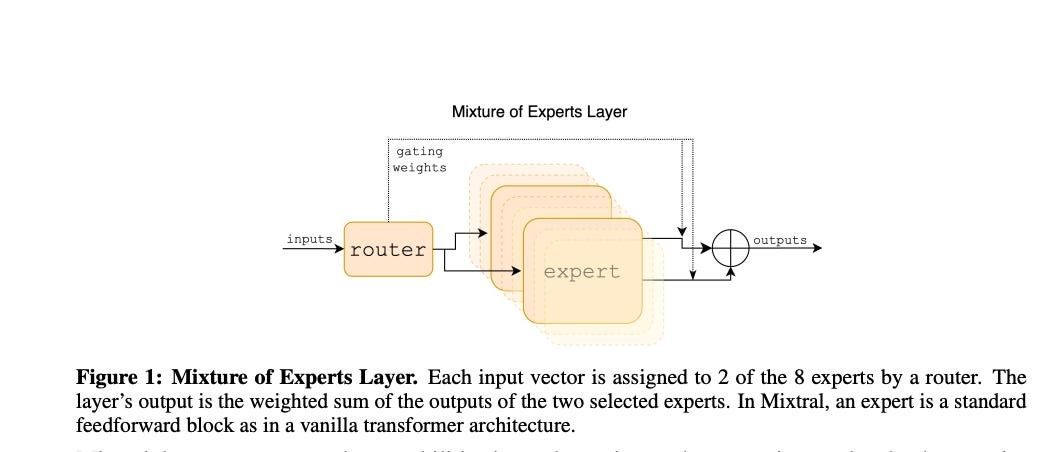
We introduce Mixtral 8x7B, a Sparse Mixture of Experts (SMoE) language model. Mixtral has the same architecture as Mistral 7B, with the difference that each layer is composed of 8 feedforward blocks (i.e. experts). For every token, at each layer, a router network selects two experts to process the current state and combine their outputs. Even though each token only sees two experts, the selected experts can be different at each timestep. As a result, each token has access to 47B parameters, but only uses 13B active parameters during inference. Mixtral was trained with a context size of 32k tokens and it outperforms or matches Llama 2 70B and GPT-3.5 across all evaluated benchmarks. In particular, Mixtral vastly outperforms Llama 2 70B on mathematics, code generation, and multilingual benchmarks. We also provide a model fine-tuned to follow instructions, Mixtral 8x7B - Instruct, that surpasses GPT-3.5 Turbo, Claude-2.1, Gemini Pro, and Llama 2 70B - chat model on human benchmarks. Both the base and instruct models are released under the Apache 2.0 license.
2.Blending Is All You Need: Cheaper, Better Alternative to Trillion-Parameters LLM ( paper )
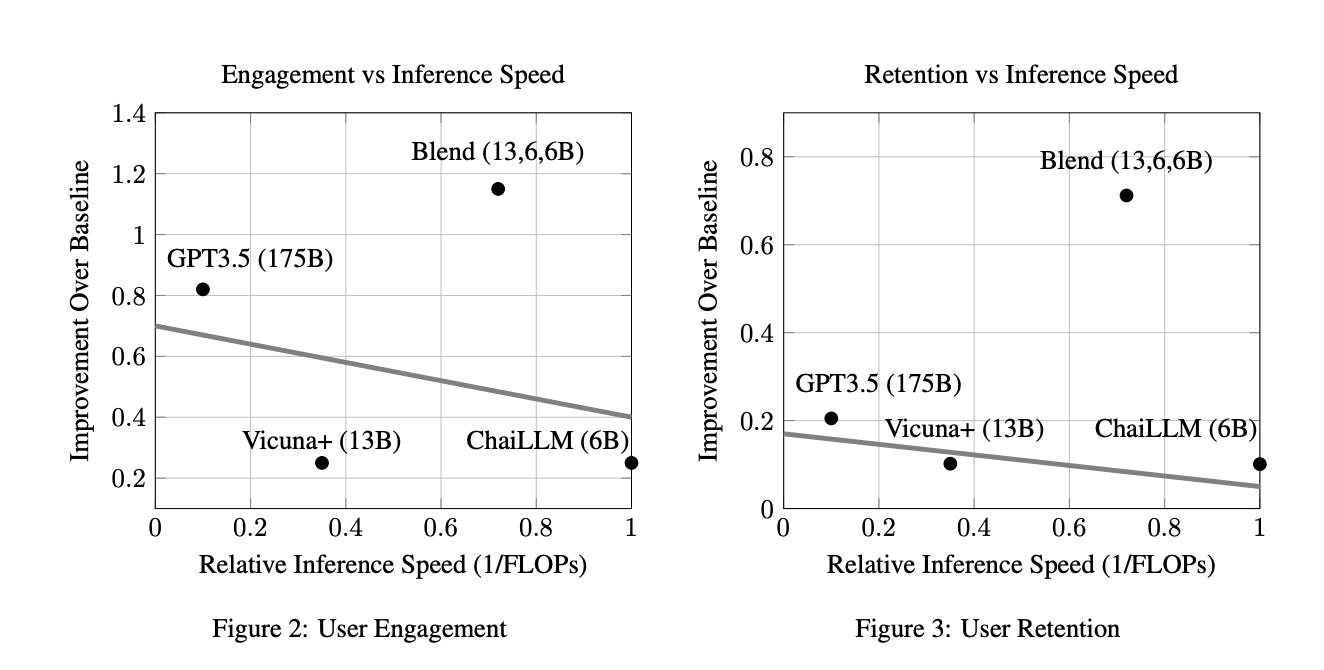
In conversational AI research, there's a noticeable trend towards developing models with a larger number of parameters, exemplified by models like ChatGPT. While these expansive models tend to generate increasingly better chat responses, they demand significant computational resources and memory. This study explores a pertinent question: Can a combination of smaller models collaboratively achieve comparable or enhanced performance relative to a singular large model? We introduce an approach termed "blending", a straightforward yet effective method of integrating multiple chat AIs. Our empirical evidence suggests that when specific smaller models are synergistically blended, they can potentially outperform or match the capabilities of much larger counterparts. For instance, integrating just three models of moderate size (6B/13B paramaeters) can rival or even surpass the performance metrics of a substantially larger model like ChatGPT (175B+ paramaters). This hypothesis is rigorously tested using A/B testing methodologies with a large user base on the Chai research platform over a span of thirty days. The findings underscore the potential of the "blending" strategy as a viable approach for enhancing chat AI efficacy without a corresponding surge in computational demands.
3.TeleChat Technical Report ( paper )
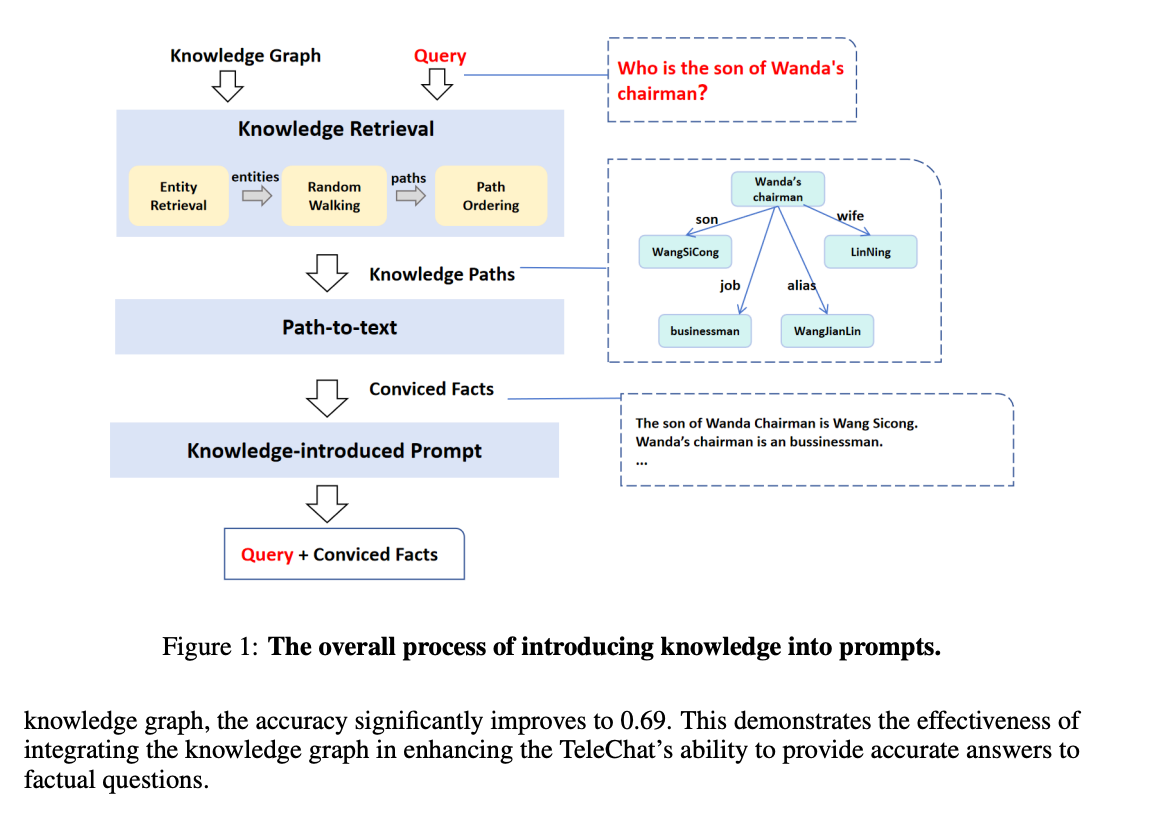
In this technical report, we present TeleChat, a collection of large language models (LLMs) with parameters of 3 billion, 7 billion and 12 billion. It includes pretrained language models as well as fine-tuned chat models that is aligned with human preferences. TeleChat is initially pretrained on an extensive corpus containing a diverse collection of texts from both English and Chinese languages, including trillions of tokens. Subsequently, the model undergoes fine-tuning to align with human preferences, following a detailed methodology that we describe. We evaluate the performance of TeleChat on various tasks, including language understanding, mathematics, reasoning, code generation, and knowledge-based question answering. Our findings indicate that TeleChat achieves comparable performance to other open-source models of similar size across a wide range of public benchmarks. To support future research and applications utilizing LLMs, we release the fine-tuned model checkpoints of TeleChat's 7B and 12B variant, along with code and a portion of our pretraining data, to the public community.
4.FaceChain-FACT:Face Adapter for Human AIGC ( webpage)
5.AGG: Amortized Generative 3D Gaussians for Single Image to 3D ( webpage)
AI News
1.OpenAI fires back at NYT copyright lawsuit( link )
2.Volkswagen and Cerence Collaborate to Bring New, Generative AI-Powered Interaction to Drivers( link )
3.AI study suggests famous Raphael painting was not entirely his own work ( paper )
AI Repos
1. AvatarVerse: High-quality & Stable 3D Avatar Creation from Text and Pose ( repo )
2.BakedAvatar: Baking Neural Fields for Real-Time Head Avatar Synthesis ( repo )
3.DragNUWA: Fine-grained Control in Video Generation by Integrating Text, Image, and Trajectory ( repo )