



Daily Papers
1.LLaMA Pro: Progressive LLaMA with Block Expansion ( paper | code )
Key Points:
The paper proposes a block expansion method for post-pretraining of Large Language Models (LLMs), which enhances domain-specific knowledge without catastrophic forgetting.
Experiments with code and math corpora yield LLAMA PRO-8.3B, a versatile model excelling in general tasks, programming, and mathematics.
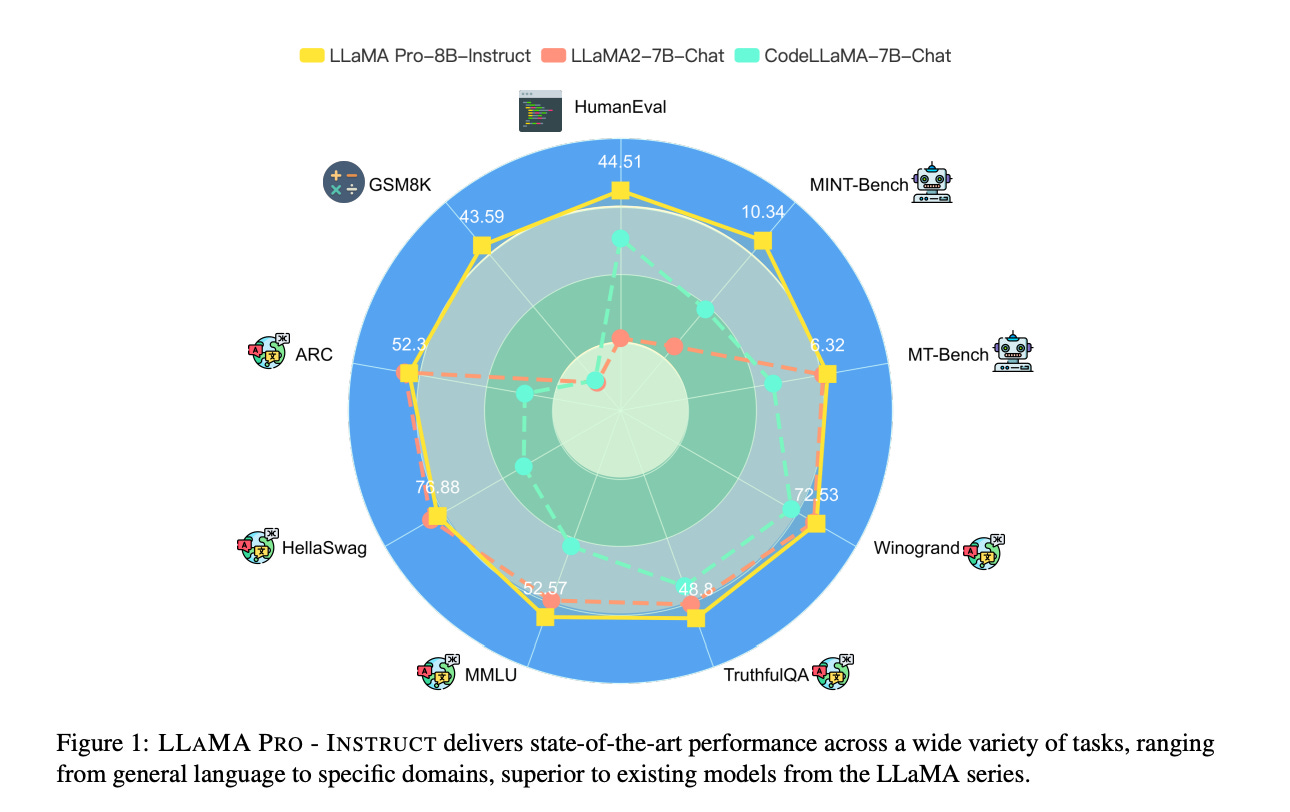
LLAMA PRO and its instruction-following version (LLAMA PRO - INSTRUCT) achieve state-of-the-art performance across various benchmarks, outperforming existing models in the LLaMA family.
The findings contribute to the integration of natural and programming languages, providing a foundation for advanced language agents.
The block expansion method is compatible with subsequent supervised fine-tuning techniques without requiring specific modifications.
Advantages:
The block expansion method enables efficient and effective enhancement of the model's knowledge without compromising its general abilities.
LLAMA PRO demonstrates a balance between natural language processing and coding capabilities, surpassing specialized models in both domains.
The model's performance is robust across a broad range of tasks, from general language to specific domains such as code and math.
The method scales well, with consistent training loss reduction as more blocks are added.
The block expansion approach shows superior adaptability compared to other strategies like sequential fine-tuning and LoRA, as evidenced by the TRACE benchmark.
Summary :
The paper introduces a block expansion technique for Large Language Models that enables the acquisition of domain-specific knowledge without forgetting general abilities, leading to improved performance across a diverse set of tasks and benchmarks.
2.Open-Vocabulary SAM: Segment and Recognize Twenty-thousand Classes Interactively ( paper | webpage )
Key Points:
The paper introduces Open-Vocabulary SAM (OV-SAM), a model that combines the strengths of the Segment Anything Model (SAM) and CLIP for interactive segmentation and recognition of a large number of classes.
OV-SAM leverages two unique knowledge transfer modules, SAM2CLIP and CLIP2SAM, to adapt SAM's knowledge into CLIP and vice versa, enabling the model to recognize and segment approximately 22,000 classes.
The model achieves significant improvements in Intersection over Union (IoU) and mean Average Precision (mAP) compared to baseline methods, particularly for recognizing small objects.
OV-SAM is designed to be compatible with various detectors, making it suitable for both closed-set and open-set environments.
The paper demonstrates the effectiveness of OV-SAM through extensive experiments on COCO and LVIS datasets, as well as its capability to serve as an interactive annotation tool for over 22,000 classes.
Advantages:
OV-SAM significantly reduces computational costs compared to SAM while maintaining or improving performance, making it more efficient for real-world applications.
The model's ability to handle a diverse range of classes and objects, including those with subtle distinctions, enhances its versatility and practical utility.
The integration of SAM2CLIP and CLIP2SAM modules allows for a more nuanced understanding of visual scenes, leading to better segmentation and recognition.
OV-SAM's compatibility with different detectors makes it a flexible tool that can be easily adapted to various vision tasks.
The model's interactive nature, where users can provide visual prompts like points or boxes, simplifies the segmentation and recognition process, making it user-friendly.
summary:
The paper presents Open-Vocabulary SAM, a unified model that combines SAM and CLIP to enable interactive segmentation and recognition of a large vocabulary of classes, offering improved performance, efficiency, and versatility for vision tasks.

3.Infinite-LLM: Efficient LLM Service for Long Context with DistAttention and Distributed KVCache ( paper )
Key Points:
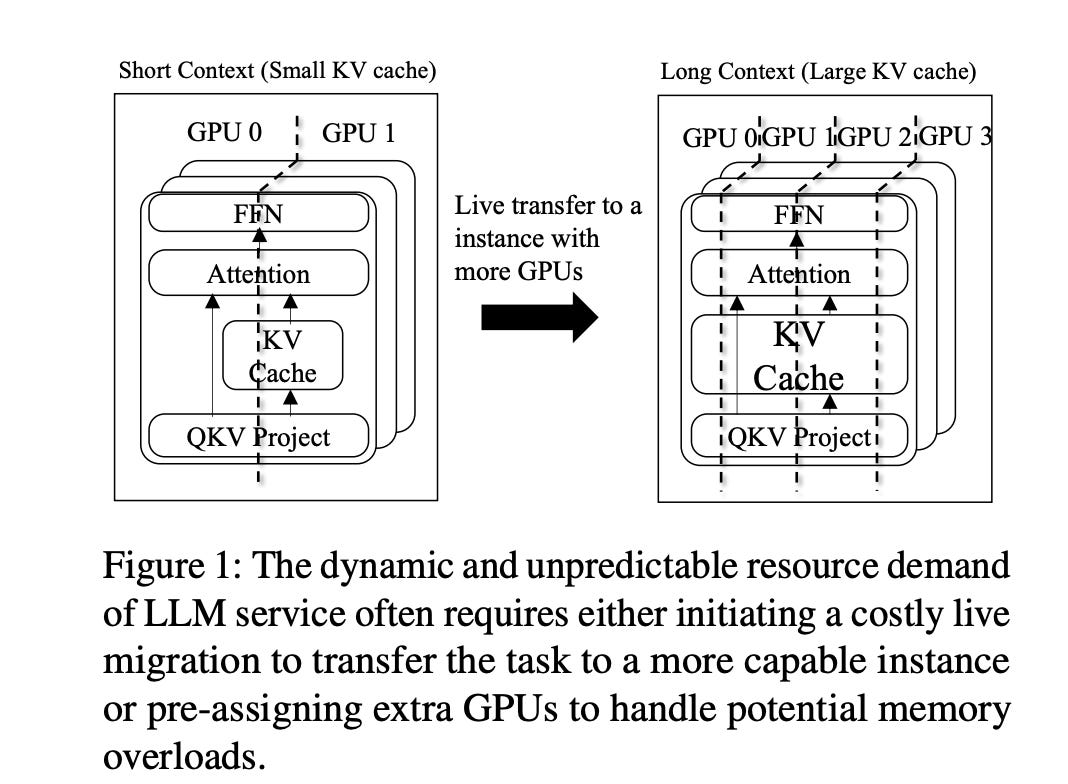
The paper introduces DistAttention, a novel distributed attention algorithm that segments the KV Cache into smaller, manageable units, enabling distributed processing and storage of the attention module.
Based on DistAttention, the authors propose DistKV-LLM, a distributed LLM serving system that dynamically manages KV Cache and effectively orchestrates all accessible GPU and CPU memories across the data center.
DistKV-LLM is designed to support a broad range of context lengths, overcoming the limitations of current LLM service systems.
The system is validated in a cloud environment with 32 NVIDIA A100 GPUs, demonstrating end-to-end throughput improvements and supporting context lengths significantly longer than current state-of-the-art LLM service systems.
DistKV-LLM integrates DistAttention with a distributed LLM service engine, providing a robust and scalable solution to the challenges of long-context LLM serving on the cloud.
Advantages:
DistAttention allows for efficient resource utilization by enabling the attention module to operate independently of other layers within the Transformer block, facilitating adaptive memory and computational resource allocation.
DistKV-LLM's distributed architecture ensures high performance and scalability, capable of handling exceptionally long context lengths without performance degradation.
The system's ability to dynamically allocate and release memory resources in response to the auto-regressive nature of LLMs prevents resource wastage and improves efficiency.
DistKV-LLM's integration with DistAttention provides a robust solution to the unique challenges posed by long-context LLM serving on the cloud.
The proposed system optimizes memory locality and communication overhead, crucial for addressing performance challenges associated with the distributed storage of the KV Cache.
summary:
The paper presents DistKV-LLM, a distributed LLM service engine that integrates DistAttention to efficiently manage KV Caches and memory resources across the data center, enabling high-performance LLM services adaptable to a broad range of context lengths.
DeepSeek LLM: Scaling Open-Source Language Models with Longtermism ( paper )
Progressive Knowledge Distillation Of Stable Diffusion XL Using Layer Level Loss ( paper )
AI News
1.ML Research Release Toolkit ( link )
2.What LLM to use? A perspective from the DevAI space ( link )
3.Experiments with Midjourney and DALL-E 3 show a copyright minefield( link )
AI Repos
1.DLRover: An Automatic Distributed Deep Learning System( repo )
2.ahxt/LiteLlama-460M-1T ( huggingface )
3.C(UDA) accelerated language model inference ( repo )