



Daily Papers
1.LLM Augmented LLMs: Expanding Capabilities through Composition( paper )
Key Points:
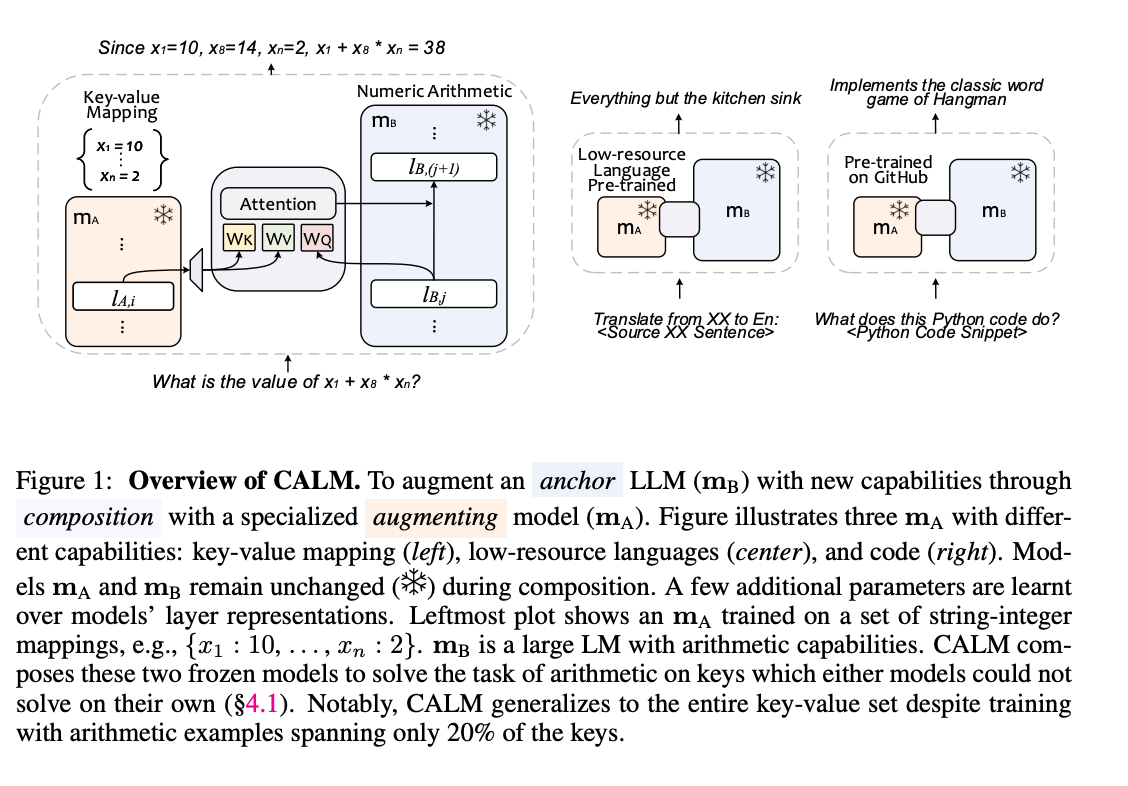
Composition Framework: The paper introduces CALM (Composition to Augment Language Models), a framework for augmenting large language models (LLMs) with specialized models to enable new capabilities without modifying the original models' weights.
Cross-Attention Mechanism: CALM utilizes cross-attention between models to compose their representations, allowing for the combination of skills from an anchor LLM and an augmenting model.
Practical Application: The framework is applied to improve translation and arithmetic reasoning for low-resource languages, as well as code generation and explanation tasks.
Efficiency and Scalability: CALM scales up LLMs on new tasks with minimal additional parameters and data, preserving existing capabilities and being applicable to diverse domains.
Performance Improvements: Experiments demonstrate significant improvements over base models, with CALM outperforming both the anchor and augmenting models in various tasks.
Advantages:
Efficient Composition: CALM enables the augmentation of LLMs with new skills in an efficient manner, requiring only a small amount of additional data and parameters.
Preservation of Existing Capabilities: The framework keeps the weights of the original models intact, ensuring that the LLM's existing capabilities are preserved.
Applicability Across Domains: CALM is not limited to specific domains and can be applied to a wide range of settings, making it a versatile solution for model augmentation.
Performance Gains: The composed models show substantial performance improvements over the base models, indicating the effectiveness of CALM in combining complementary skills.
Minimal Training Overhead: CALM requires less training data and computational resources compared to fine-tuning the entire anchor model, making it a cost-effective approach.
Summary:
CALM is an innovative framework that efficiently augments large language models by composing them with specialized models, enabling new capabilities while preserving existing ones, and is applicable across diverse domains with minimal overhead.
2.Instruct-Imagen: Image Generation with Multi-modal Instruction ( paper )
Key Points:
Multi-modal Instruction: The paper introduces multi-modal instruction for image generation, which articulates a range of generation intents with precision using natural language to amalgamate disparate modalities (e.g., text, edge, style, subject, etc.).
Instruct-Imagen Model: The authors build Instruct-Imagen, a unified model that tackles heterogeneous image generation tasks and surpasses several state-of-the-arts in their domains.
Two-Stage Training: Instruct-Imagen is trained in two stages: first, it is adapted using retrieval-augmented training to enhance its capabilities to ground its generation on external multi-modal context, and then fine-tuned on diverse image generation tasks paired with multi-modal instructions.
Generalization Capability: Instruct-Imagen demonstrates promising generalization to unseen and more complex tasks without any ad hoc design.
Human Evaluation: Human evaluation on various image generation datasets reveals that Instruct-Imagen matches or surpasses prior task-specific models in-domain and shows strong generalization to novel tasks.
Advantages:
Universal Representation: Multi-modal instruction provides a universal format for representing instructions from multiple modalities, enhancing the precision of generation tasks.
Efficient Adaptation: The two-stage training approach allows Instruct-Imagen to efficiently adapt to new tasks and modalities without extensive re-training.
Performance Improvement: Instruct-Imagen matches or exceeds the performance of specialized models in their respective domains, indicating the effectiveness of the proposed framework.
Zero-Shot Generalization: The model shows strong zero-shot generalization capabilities, being able to generate images for unseen tasks without additional training.
Unified Model: Instruct-Imagen serves as a unified solution for diverse image generation tasks, reducing the need for multiple specialized models.
Summary:
Instruct-Imagen is a novel image generation model that leverages multi-modal instructions to tackle a variety of tasks, demonstrating strong performance and generalization capabilities across domains, and is trained efficiently through a two-stage process that enhances its adaptability.

3.Personalized Restoration via Dual-Pivot Tuning( paper | webpage )
Key Points:
Multi-modal Instruction: The paper introduces multi-modal instruction for image generation, which articulates a range of generation intents with precision using natural language to amalgamate disparate modalities (e.g., text, edge, style, subject, etc.).
Instruct-Imagen Model: The authors build Instruct-Imagen, a unified model that tackles heterogeneous image generation tasks and surpasses several state-of-the-arts in their domains.
Two-Stage Training: Instruct-Imagen is trained in two stages: first, it is adapted using retrieval-augmented training to enhance its capabilities to ground its generation on external multi-modal context, and then fine-tuned on diverse image generation tasks paired with multi-modal instructions.
Generalization Capability: Instruct-Imagen demonstrates promising generalization to unseen and more complex tasks without any ad hoc design.
Human Evaluation: Human evaluation on various image generation datasets reveals that Instruct-Imagen matches or surpasses prior task-specific models in-domain and shows strong generalization to novel tasks.
Advantages:
Universal Representation: Multi-modal instruction provides a universal format for representing instructions from multiple modalities, enhancing the precision of generation tasks.
Efficient Adaptation: The two-stage training approach allows Instruct-Imagen to efficiently adapt to new tasks and modalities without extensive re-training.
Performance Improvement: Instruct-Imagen matches or exceeds the performance of specialized models in their respective domains, indicating the effectiveness of the proposed framework.
Zero-Shot Generalization: The model shows strong zero-shot generalization capabilities, being able to generate images for unseen tasks without additional training.
Unified Model: Instruct-Imagen serves as a unified solution for diverse image generation tasks, reducing the need for multiple specialized models.
Summary:
Instruct-Imagen is a novel image generation model that leverages multi-modal instructions to tackle a variety of tasks, demonstrating strong performance and generalization capabilities across domains, and is trained efficiently through a two-stage process that enhances its adaptability.

4.Improving Diffusion-Based Image Synthesis with Context Prediction( paper )
5.Understanding LLMs: A Comprehensive Overview from Training to Inference ( paper )
AI News
1.OpenAI’s GPT Store launching next week( link )
2.GPT Builder: What is the GPT Builder for in ChatGPT and why did we make it? ( link )
3.AI-powered search engine Perplexity AI, now valued at $520M, raises $73.6M ( link )
AI Repos
1.Can It Edit? Evaluating the Ability of Large Language Models to Follow Code Editing Instructions ( repo )
2.Question and Answer based on Anything ( repo )
3.Awesome-llm-role-playing-with-persona: a curated list of resources for large language models for role-playing with assigned personas( repo )