



Daily Papers
1.Mini-GPTs: Efficient Large Language Models through Contextual Pruning (paper)
This paper introduces a novel approach in AI research for optimizing Large Language Models (LLMs) through contextual pruning. Building on Professor Song Han's work at MIT, it effectively reduces LLM sizes like Phi-1.5 while maintaining core functionalities. Applied to diverse datasets, it demonstrates contextual pruning's practicality in creating efficient, domain-specific LLMs, paving the way for future advancements

2.StreamDiffusion: A Pipeline-level Solution for Real-time Interactive Generation ( paper | code )
StreamDiffusion revolutionizes interactive image generation with a real-time diffusion pipeline, enhancing existing models for high-throughput scenarios like the Metaverse and live streaming. It replaces sequential denoising with a batching process, enabling faster, fluid streams. A novel input-output queue and residual classifier-free guidance (RCFG) algorithm reduce computational steps and power use. StreamDiffusion achieves up to 91.07fps on an RTX4090, significantly outperforming existing models in speed and energy efficiency.
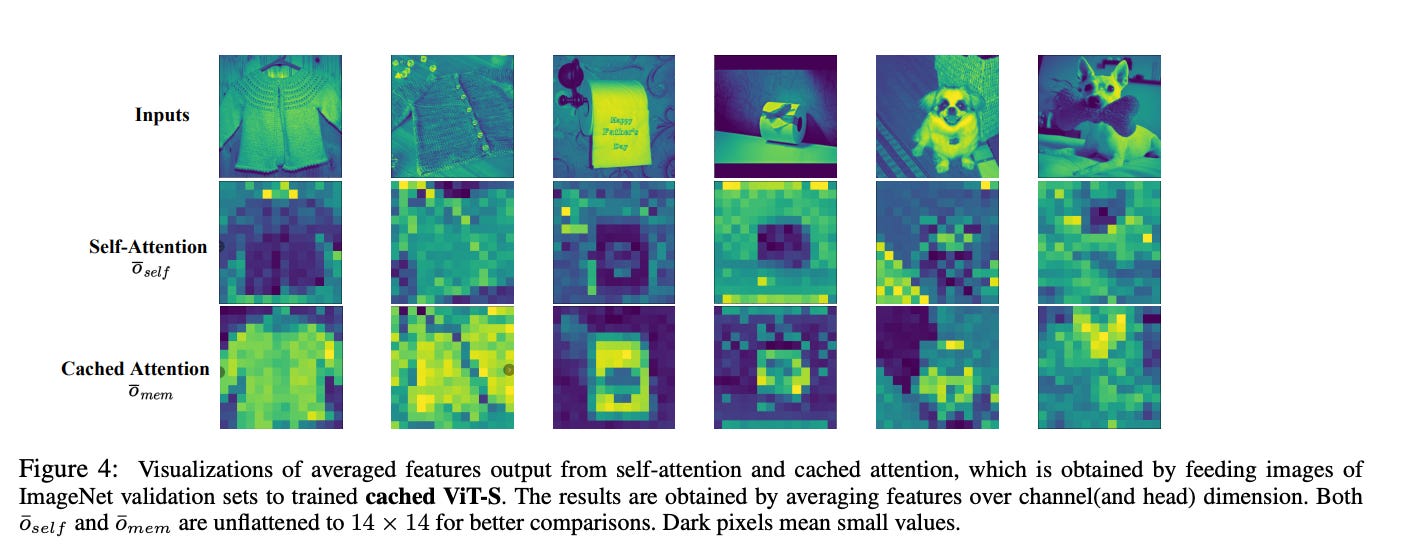
3.Cached Transformers: Improving Transformers with Differentiable Memory Cache ( paper )
The Cached Transformer, with its novel Gated Recurrent Cached (GRC) attention, enhances self-attention models by adding a differentiable memory cache for tokens. This expands its capacity to handle both past and current tokens, improving long-range dependency analysis. Demonstrating significant advancements in six varied tasks, including language modeling and image classification, it outperforms previous memory-based models, showcasing broad application potential.
4.InstructVideo: Instructing Video Diffusion Models with Human Feedback ( paper | webpage )
InstructVideo addresses the challenge of visually unappealing and misaligned outputs from text-to-video diffusion models by introducing human feedback through reward fine-tuning. It comprises two innovative approaches: 1) Editing-based reward fine-tuning, leveraging the diffusion process to corrupt sampled videos for partial DDIM chain inference, enhancing fine-tuning efficiency and reducing costs. 2) Using established image reward models, like HPSv2, for video through Segmental Video Reward and Temporally Attenuated Reward. These methods provide effective reward signals and prevent temporal modeling degradation during fine-tuning. Extensive tests confirm that InstructVideo significantly improves the visual quality of generated videos while maintaining generalization capabilities.
5.StarVector: Generating Scalable Vector Graphics Code from Images ( paper )
StarVector, a multimodal SVG generation model, effectively combines Code Generation Large Language Models (CodeLLMs) with vision models to overcome limitations in complex SVG generation. Utilizing a CLIP image encoder and an adapter module, it transforms pixel images into visual tokens, which are then aligned with SVG token embeddings using the StarCoder model. This approach enables unrestricted SVG generation that accurately represents pixel images. StarVector's performance is evaluated using SVG-Bench, a comprehensive benchmark including novel datasets like SVG-Stack. The results show significant improvements in visual quality and complexity handling, marking a major advancement in SVG generation technology.

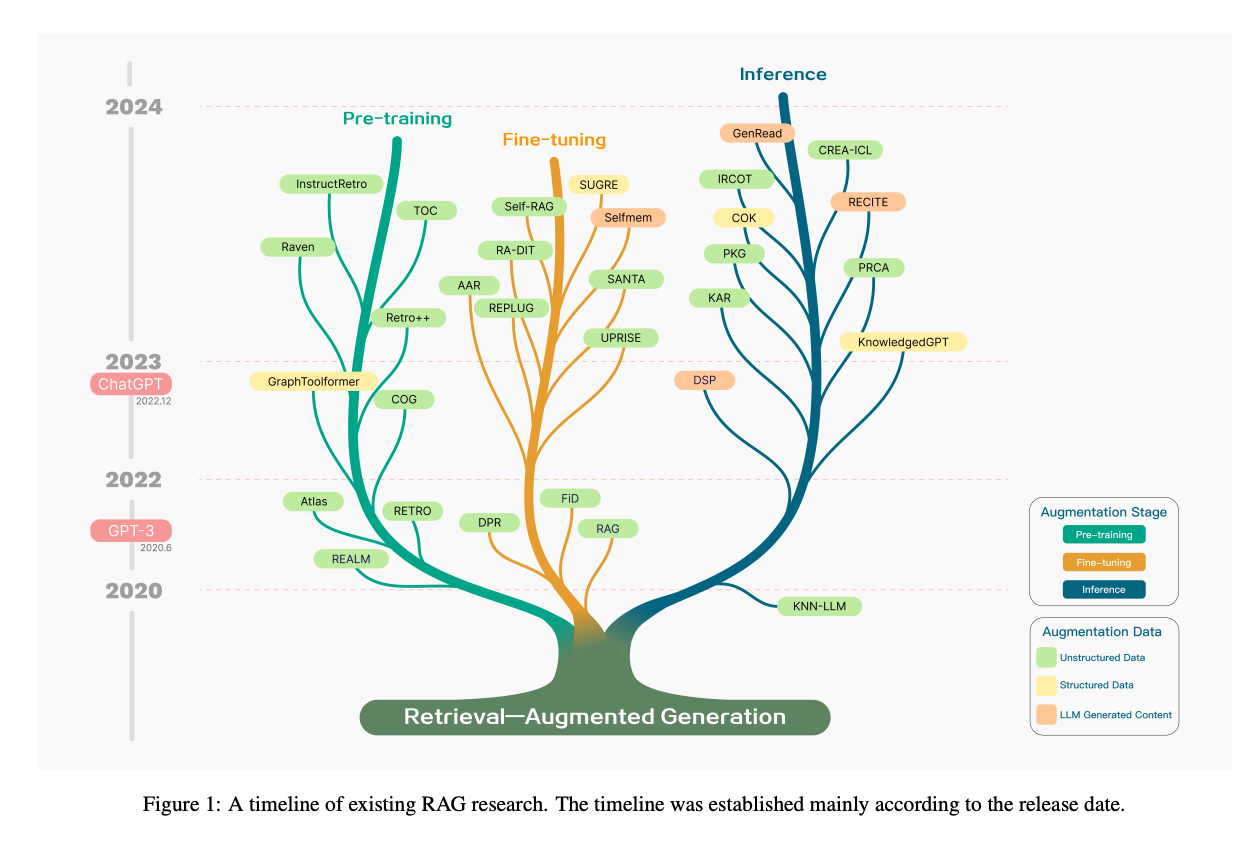
6.Retrieval-Augmented Generation for Large Language Models: A Survey ( paper )
This paper delves into Retrieval-Augmented Generation (RAG) in Large Language Models (LLMs), a method that enhances LLMs by retrieving information from external databases before responding to queries. RAG significantly improves answer accuracy and reduces hallucinations in LLMs, especially for knowledge-intensive tasks. By citing sources, RAG boosts user trust by allowing verification of model responses. It also aids in updating knowledge and introducing domain-specific information. The paper outlines three RAG paradigms: Naive RAG, Advanced RAG, and Modular RAG, and summarizes the key components and technologies of RAG: retriever, generator, and augmentation methods. It also discusses RAG model evaluation, introducing methods and key metrics, along with an automatic evaluation framework. The paper concludes with potential future research directions in RAG, focusing on vertical optimization, horizontal scalability, and the RAG technical stack and ecosystem.
AI News
1.Advanced RAG Techniques: an Illustrated Overview ( link )
2.The Dictionary.com Word of the Year is hallucinate.( link )
3.Google Gemini is not even as good as GPT-3.5 Turbo, researchers find ( link )
AI Repos
1.Minimal web UI for GeminiPro ( repo )
2.DreamCreature: Crafting Photorealistic Virtual Creatures from Imagination ( repo )
3.danswer: OpenSource Enterprise Question-Answering ( repo )