




Daily Papers
1.Upscale-A-Video: Temporal-Consistent Diffusion Model for Real-World Video Super-Resolution( paper | webpage)
Text-based diffusion models excel in content generation and editing, but video super-resolution remains tough due to output fidelity and temporal consistency demands. "Upscale-A-Video," a new text-guided latent diffusion framework, addresses this by integrating temporal layers into U-Net and VAE-Decoder for short sequence coherence and using a flow-guided latent propagation module for overall stability. It allows text-driven texture creation and noise adjustment, balancing restoration and generation. This model outperforms others in benchmarks, showing high visual realism and temporal consistency.
2.Animate124: Animating One Image to 4D Dynamic Scene(paper | webpage | code)
"Animate124" is a groundbreaking method that animates a single in-the-wild image into 3D video using textual motion descriptions, a largely unexplored area with vast potential applications. It employs an advanced 4D grid dynamic Neural Radiance Field (NeRF) model, optimized through three stages with multiple diffusion priors. The process starts with optimizing a static model using the reference image and 2D/3D diffusion priors, setting the stage for the dynamic NeRF. Then, a video diffusion model learns motion specific to the subject. However, challenges arise as the 3D video object tends to drift from the reference image, mainly due to misalignment between the text prompt and image. To combat this, a personalized diffusion prior is introduced in the final stage, addressing semantic drift. This image-text-to-4D generation framework marks a significant advancement over current methods, proven by extensive quantitative and qualitative evaluations.
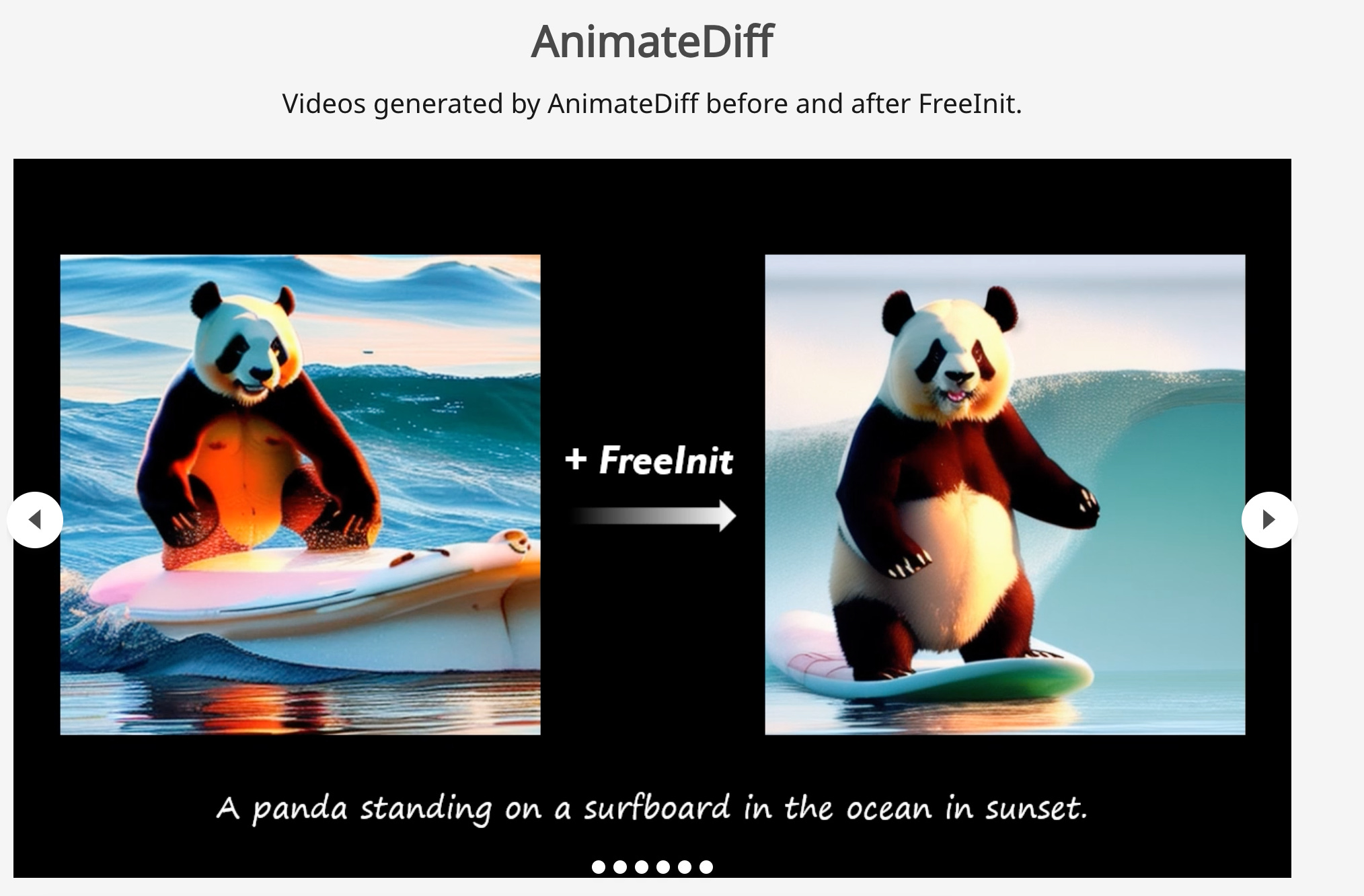
3.FreeInit: Bridging Initialization Gap in Video Diffusion Models( paper | webpage | code )
Diffusion-based video generation models struggle with temporal consistency and dynamics due to a training-inference gap. Our study reveals differences in the spatial-temporal frequency of initial latents and the impact of low-frequency noise on denoising. We introduce "FreeInit," a strategy improving temporal consistency by refining the initial latent's low-frequency component during inference, effectively bridging the training-inference gap and enhancing generation results without extra training
4.DiffMorpher: Unleashing the Capability of Diffusion Models for Image Morphing( paper | webpage )
Diffusion models surpass other generative models in image quality but lag behind GANs in smooth interpolation between images due to unstructured latent spaces, crucial for image morphing applications. "DiffMorpher" addresses this by enabling smooth image interpolation with diffusion models. It fits two LoRAs to the images, interpolating between LoRA parameters and latent noises for seamless semantic transitions without annotations. We also introduce attention interpolation, adaptive normalization adjustment, and a new sampling schedule for enhanced smoothness in consecutive images. Extensive tests show DiffMorpher's superior image morphing capabilities over previous methods, filling a vital gap in diffusion models compared to GANs.

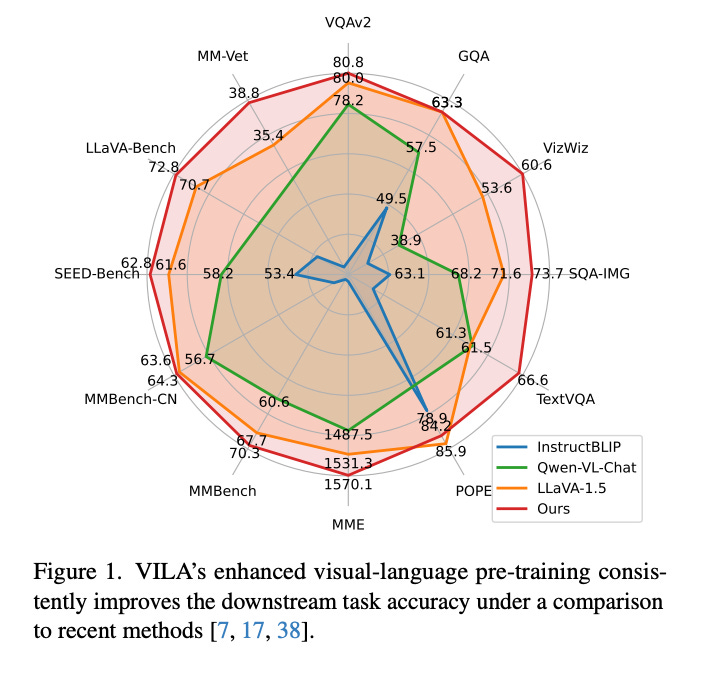
5.VILA: On Pre-training for Visual Language Models ( paper )
As visual language models (VLMs) evolve alongside large language models (LLMs), the study of their pre-training process, crucial for joint modeling of visual and textual data, has been underexplored. Our research augments LLMs to VLMs with controlled comparisons, revealing three key insights: 1) Freezing LLMs during pre-training yields good zero-shot performance but limits in-context learning, which requires unfreezing the LLM; 2) Using interleaved pre-training data is more effective than relying solely on image-text pairs; 3) Re-integrating text-only instruction data with image-text data during fine-tuning not only improves performance on text-only tasks but also enhances VLM task accuracy. Leveraging these findings, we developed VILA, a superior VLM family that surpasses state-of-the-art models like LLaVA-1.5 in main benchmarks. VILA's multi-modal pre-training reveals enhanced capabilities in multi-image reasoning, in-context learning, and world knowledge understanding.
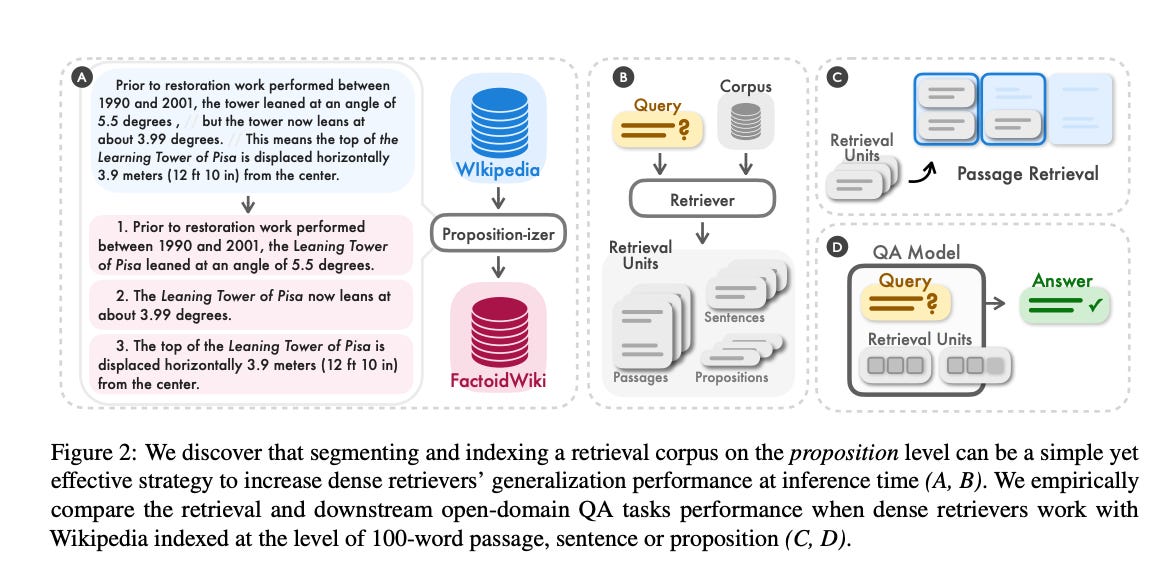
6.Dense X Retrieval: What Retrieval Granularity Should We Use? ( paper )
In open-domain NLP tasks, dense retrieval is crucial for accessing context or world knowledge. A key, often overlooked aspect is the choice of retrieval unit (e.g., document, passage, sentence) for indexing the corpus. Our study finds this choice greatly influences retrieval and downstream task performance. We propose a new retrieval unit, the 'proposition,' defined as atomic text expressions, each containing a distinct factoid in a concise, self-contained format. An empirical comparison shows proposition-based retrieval outperforms traditional passage or sentence methods. This approach also improves downstream QA tasks' performance by providing more focused, relevant information, reducing lengthy inputs and irrelevant data.
AI News
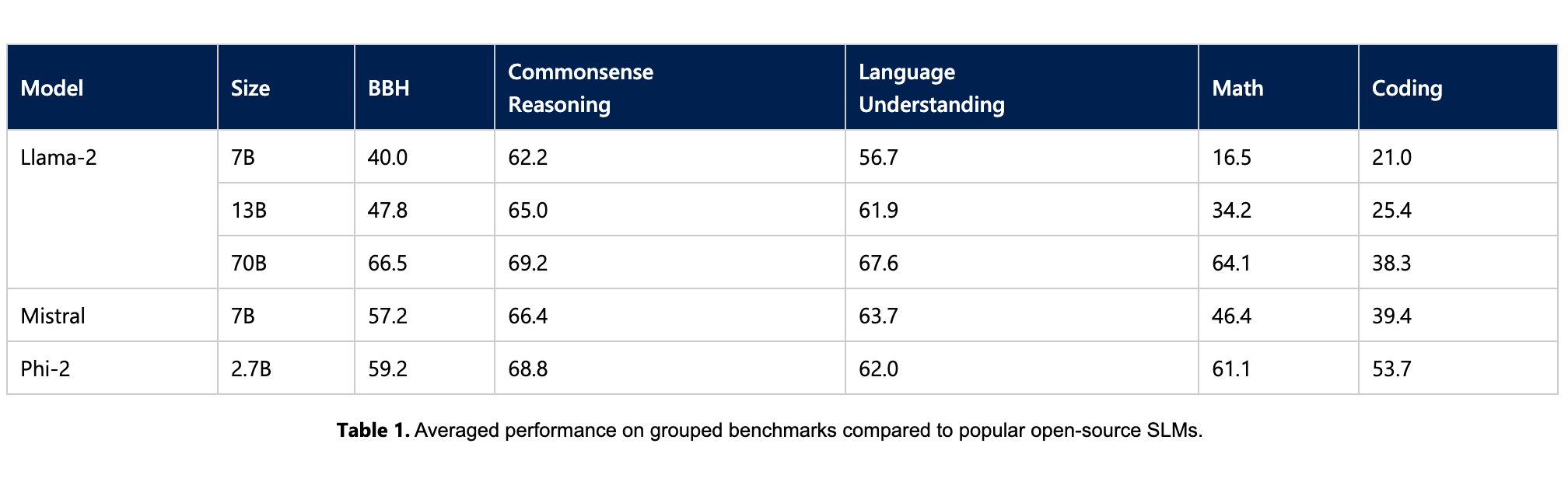
1.Microsoft’sPhi-2: The surprising power of small language models ( Microsoft Research Blog | paper )
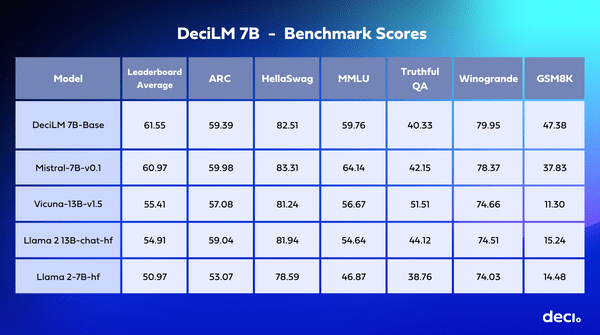
2.Introducing DeciLM-7B: The Fastest and Most Accurate 7 Billion-Parameter LLM to Date ( deciAI blog)
3.Tesla’s Faster Yet Lighter Humaoid Robot( twitter )
Tesla has unveiled its Optimus Gen-2, its next generation of humanoid robot (with a very enaging video demo).
4.Essential AI Raises $56.5M Series A to Build the Enterprise Brain ( news )
5.Claude for Google Sheets ( anthropic docs)
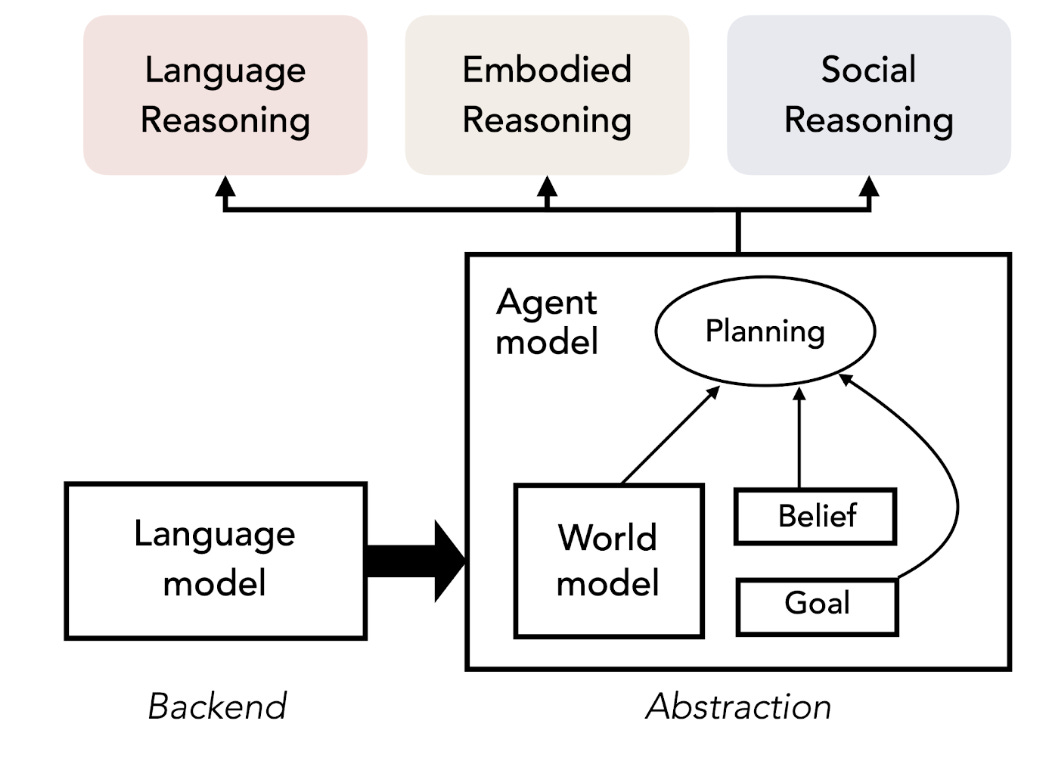
6.NeurIPS 2023 tutorial: Language Models meet World Models( link )
AI Repo
1.Run the Mixtral 8x7B mixture-of-experts (MoE) model in MLX on Apple silicon ( repo )
2.Knowledge-Augmented Language Model Verification ( repo )
3.SQL-GPT:Use ChatGPT to generate SQL and perform execution. Optimization and error correction of SQL is also possible.( repo )