



Daily Papers
1.Label Words are Anchors: An Information Flow Perspective for Understanding In-Context Learning ( paper | code )
Our study delves into the workings of in-context learning (ICL) in large language models (LLMs) by examining how they utilize provided examples. We find that label words in examples act as anchors, aggregating semantic information in early computation layers and guiding LLMs' final predictions. Leveraging these insights, we introduce an anchor re-weighting method to boost ICL performance, a demonstration compression technique for faster inference, and a framework for diagnosing ICL errors in GPT2-XL. These applications confirm our understanding of ICL and open avenues for further research.

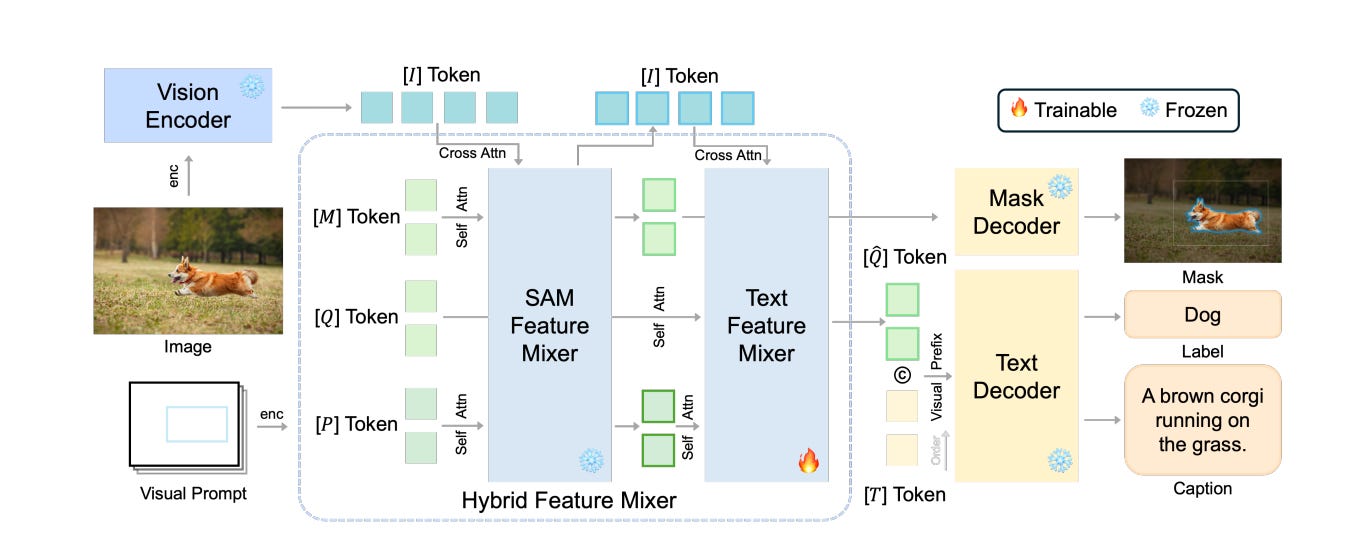
2.Segment and Caption Anything( paper | webpage)
We enhance SAM to generate regional captions using a lightweight, efficient query-based feature mixer, aligning region-specific features with language model embeddings for efficient caption generation. With few trainable parameters, it's fast and scalable. We initially pre-train on object detection with weak supervision, using category names, and validate our approach through extensive experiments. This innovation marks progress in regional captioning and semantic augmentation of SAM.
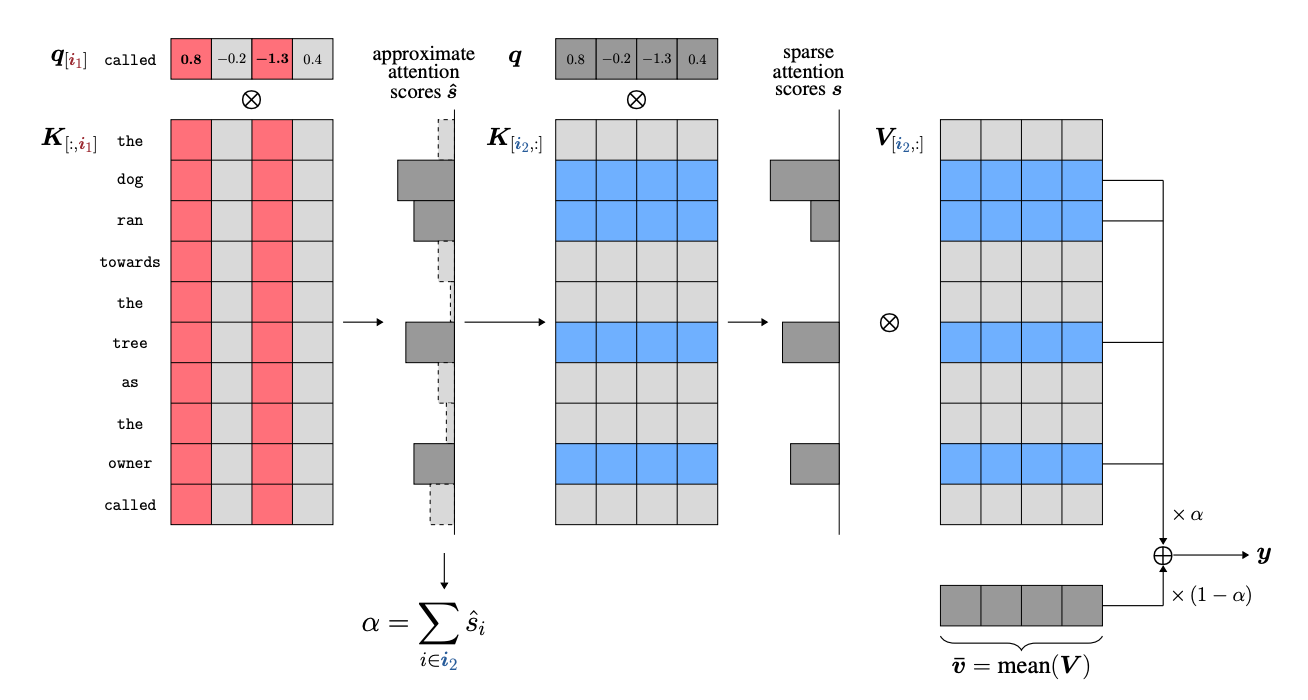
3.SparQ Attention: Bandwidth-Efficient LLM Inference( paper )
Generative large language models (LLMs) offer exciting prospects but face challenges in widespread use due to high computational demands. Key applications involving processing numerous samples and long contexts increase the memory load significantly. To address this, we introduce SparQ Attention, a method that enhances LLMs' inference efficiency by reducing memory bandwidth in attention blocks. This is achieved by selectively fetching only necessary parts of the cached history. SparQ Attention can be seamlessly integrated with existing LLMs during inference without altering their pre-training or requiring additional fine-tuning. We demonstrate that SparQ Attention can reduce attention memory bandwidth requirements by up to eight times, maintaining accuracy. This efficiency is validated on Llama 2 and Pythia models across various tasks
4.Text-to-3D Generation with Bidirectional Diffusion using both 2D and 3D priors(paper | webpage)
Current 3D generation research primarily upgrades 2D models to 3D, using methods like 2D Score Distillation Sampling or multi-view dataset fine-tuning. However, these techniques often result in geometric inaccuracies and inconsistencies in different views due to the lack of 3D priors. Some researchers are now training directly on 3D datasets to improve realism, but this often leads to poor texture quality due to limited diversity in these datasets. Addressing these challenges, we introduce Bidirectional Diffusion (BiDiff), a framework combining 3D and 2D diffusion processes to maintain both 3D structural integrity and 2D texture detail. To overcome potential inconsistencies from this combination, we apply novel bidirectional guidance. Additionally, BiDiff serves as an efficient initialization step for optimization-based models, significantly reducing generation time from 3.4 hours to 20 minutes. Tests demonstrate that our model achieves high-quality, diverse, and scalable 3D generation.

5.Customizing Motion in Text-to-Video Diffusion Models (paper | webpage)
We present a method to augment text-to-video models with custom motions, using a few video samples for input. This approach learns and applies these motions in various text-specified scenarios. It involves fine-tuning a model with new tokens representing custom motions, regularizing to prevent overfitting, and leveraging motion priors to create videos with multiple characters performing combined motions. It also supports multimodal customization of motion and appearance. Our method's effectiveness is validated through quantitative evaluation and an ablation study, showing superior performance over previous methods.

AI News
1.Mixtral of experts: A high quality Sparse Mixture-of-Experts.( mistralAI news)

2.Google at NeurIPS 2023( google blog )
3.Towards 100x Speedup: Full Stack Transformer Inference Optimization ( link )
4.What LLMs cannot do(link )
AI Repo
1.HyperAttention: Triton Implementation of HyperAttention Algorithm( repo )
2.AgentLego: an open-source library of versatile tool APIs to extend and enhance large language model (LLM) based agents. ( repo )
3.knowledge_graph: Convert any text to a graph of knowledge. This can be used for Graph Augmented Generation or Knowledge Graph based QnA ( repo )
4.WikiChat: WikiChat improves the factuality of large language models by retrieving data from Wikipedia.( repo )