



Daily Papers
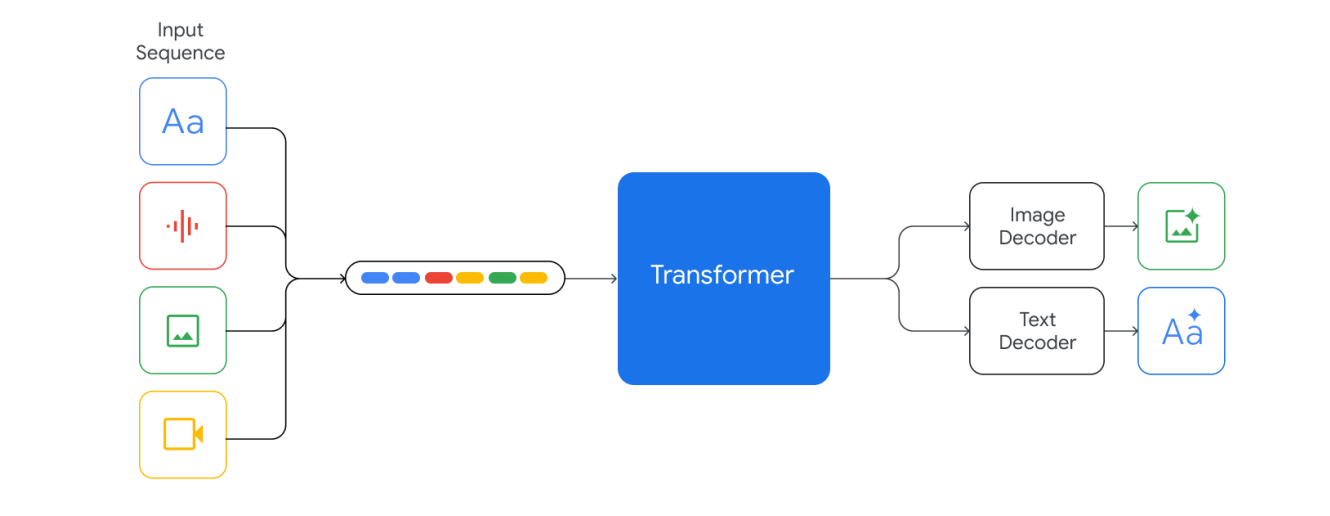
1.Gemini: A Family of Highly Capable Multimodal Models( google blog | gemini report)
Summary of Gemini's 60-page technical report:
1. Written in Jax and trained using TPUs. The architecture, while not explained in details, seems similar to Flamigo's.
2. Gemini Pro's performance is similar to GPT-3.5 and Gemini Ultra is reported to be better than GPT-4. Nano-1 (1.8B params) and Nano-2 (3.25B params) are designed to run on-device.
3. 32K context length.
4. Very good at understanding vision and speech.
5. Coding ability: the big jump in HumanEval compared to GPT-4 (74.4% vs. 67%), if true, is awesome. However, the Natural2Code benchmark (no leakage on the Internet) shows a much smaller gap (74.9% vs. 73.9%).
6. On MMLU: using COT@32 (32 samples) to show that Gemini is better than GPT-4 seems forced. In 5-shot setting, GPT-4 is better (86.4% vs. 83.7%).
7. No information at all on the training data, other than they ensured "all data enrichment workers are paid at least a local living wage."
2.Running cognitive evaluations on large language models: The do's and the don'ts (paper)
This paper outlines best practices for evaluating language models' cognitive abilities, highlighting common issues and providing guidelines. It covers aspects like prompt sensitivity, cultural diversity, using AI as research assistants, and testing on different types of language models, contributing to AI Psychology.

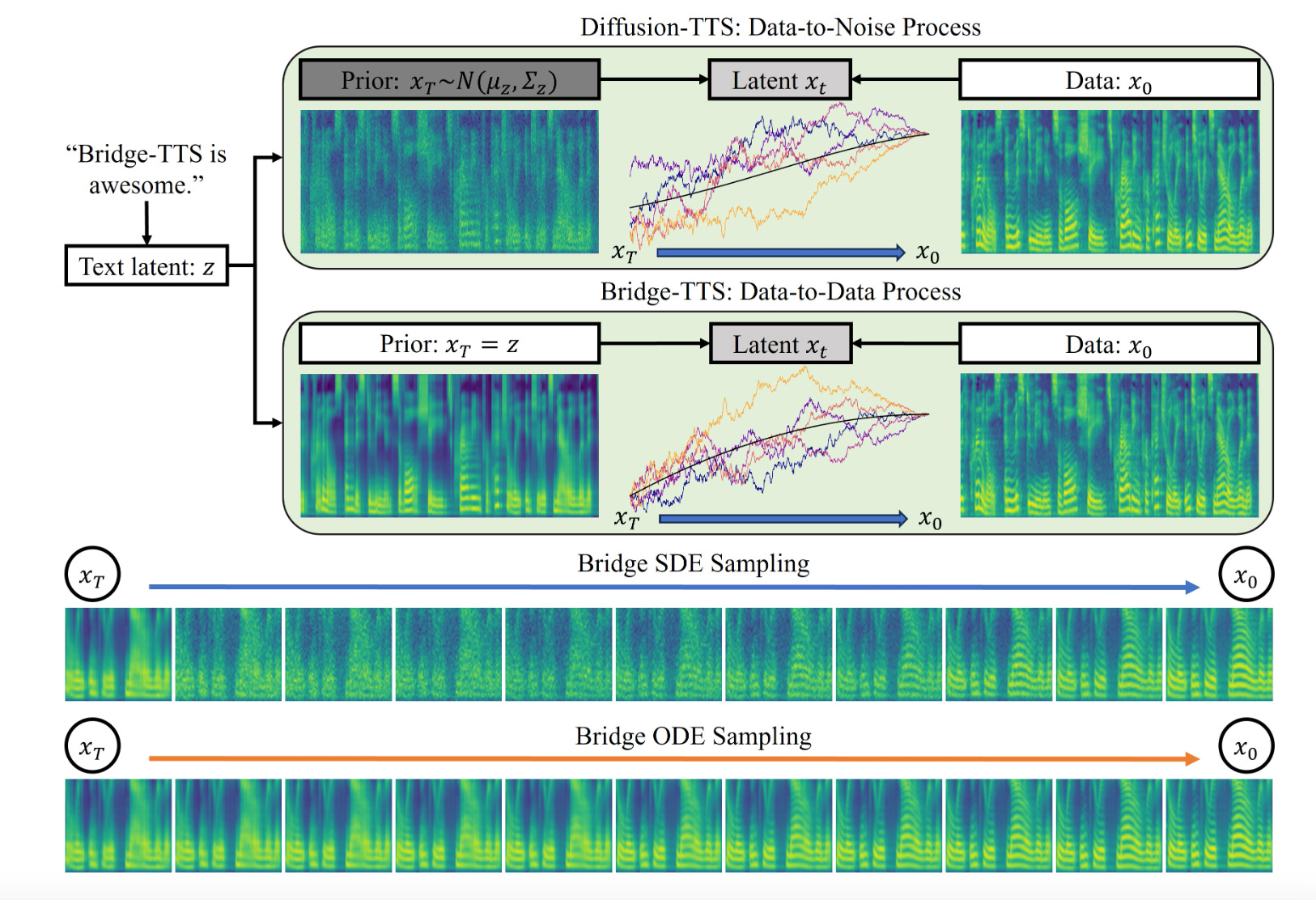
3.Schrodinger Bridges Beat Diffusion Models on Text-to-Speech Synthesis(paper | webpage)
Bridge-TTS introduces a novel TTS system replacing the noisy Gaussian prior in diffusion models with a clean, deterministic one derived from text input's latent representation. This method, leading to a data-to-data process, improves synthesis quality and efficiency, outperforming traditional models in various synthesis scenarios
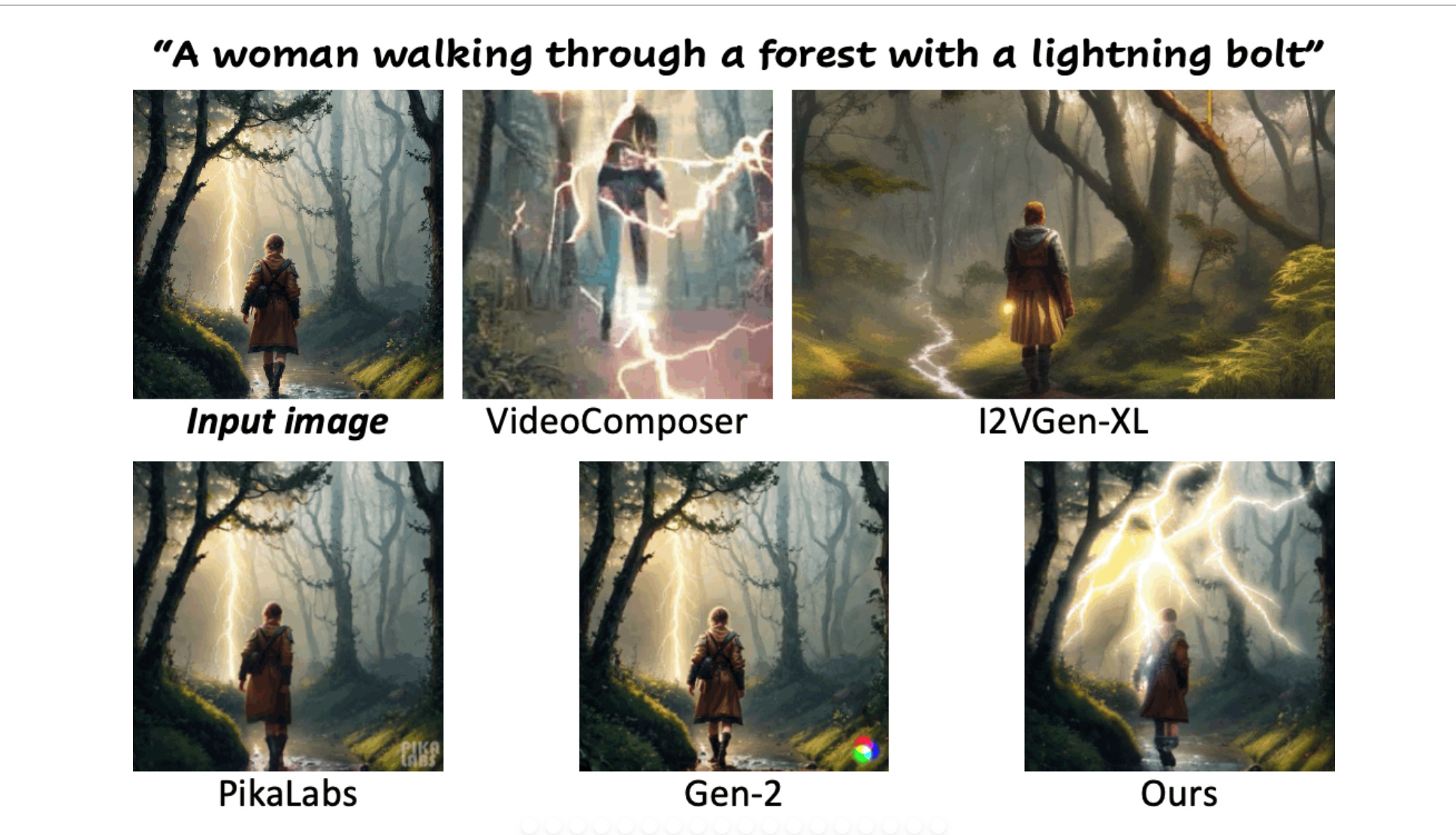
4.DynamiCrafter: Animating Open-domain Images with Video Diffusion Priors(paper | webpage)
This study enhances image animation by synthesizing dynamic content for open-domain images, converting them into animated videos using text-to-video diffusion models. It involves projecting the image into a text-aligned context for compatibility, then feeding it to the model for detail preservation. This method yields more natural and conforming animations, outperforming existing techniques.
5.TokenCompose : Grounding Diffusion with Token-level Supervision(paper | webpage)
TokenCompose, a Latent Diffusion Model for text-to-image generation, enhances the consistency between text prompts and generated images. It addresses the issue of unsatisfactory multi-category compositions in standard models by introducing token-wise consistency terms between image content and object segmentation maps during finetuning. This approach improves multi-category instance composition and photorealism without needing extra human labeling, and can be integrated into existing training pipelines.
AI News
1.A Guide on 12 Tuning Strategies for Production-Ready RAG Applications( link )
2.Goodbye cold boot - how we made LoRA Inference 300% faster( link )
3.Long context prompting for Claude 2.1(anthropic blog)
4.Meta will let you ‘reimagine’ your friends’ AI-generated images( link)
AI Repo
1.ArtSpew:An infinite number of monkeys randomly throwing paint at a canvas(repo)
2.Convert your videos to densepose and use it on MagicAnimate( repo )
3.supervision: reusable computer vision tools( repo )