



Daily Papers
1.LivePhoto: Real Image Animation with Text-guided Motion Control(paper | webpage)
LivePhoto, a novel system presented in this work, addresses the challenge in text-to-video generation where temporal motions aren't text-controlled. It enhances a text-to-image generator (like Stable Diffusion) with a motion module for temporal modeling and a training pipeline linking texts to motions. The system includes a motion intensity estimation module and a text re-weighting module to clarify text-to-motion mapping, decoding motion-related textual instructions into videos effectively. Additionally, it offers users control over motion intensity for video customization, a unique feature in this field.
2.FaceStudio: Put Your Face Everywhere in Seconds(paper | webpage)
This study explores identity-preserving image synthesis, focusing on maintaining a subject's identity with stylistic alterations. Traditional methods like Textual Inversion and DreamBooth have shown promise but require extensive resources and multiple reference images. To address these limitations, the research introduces a novel approach, particularly for human images, using a direct feed-forward mechanism for efficient image generation. A hybrid guidance framework, combining stylized and facial images with textual prompts, guides the process. This enables applications like artistic portraits and identity-blended images. The experimental results showcase this method's efficiency and superior ability to preserve identity compared to existing models.

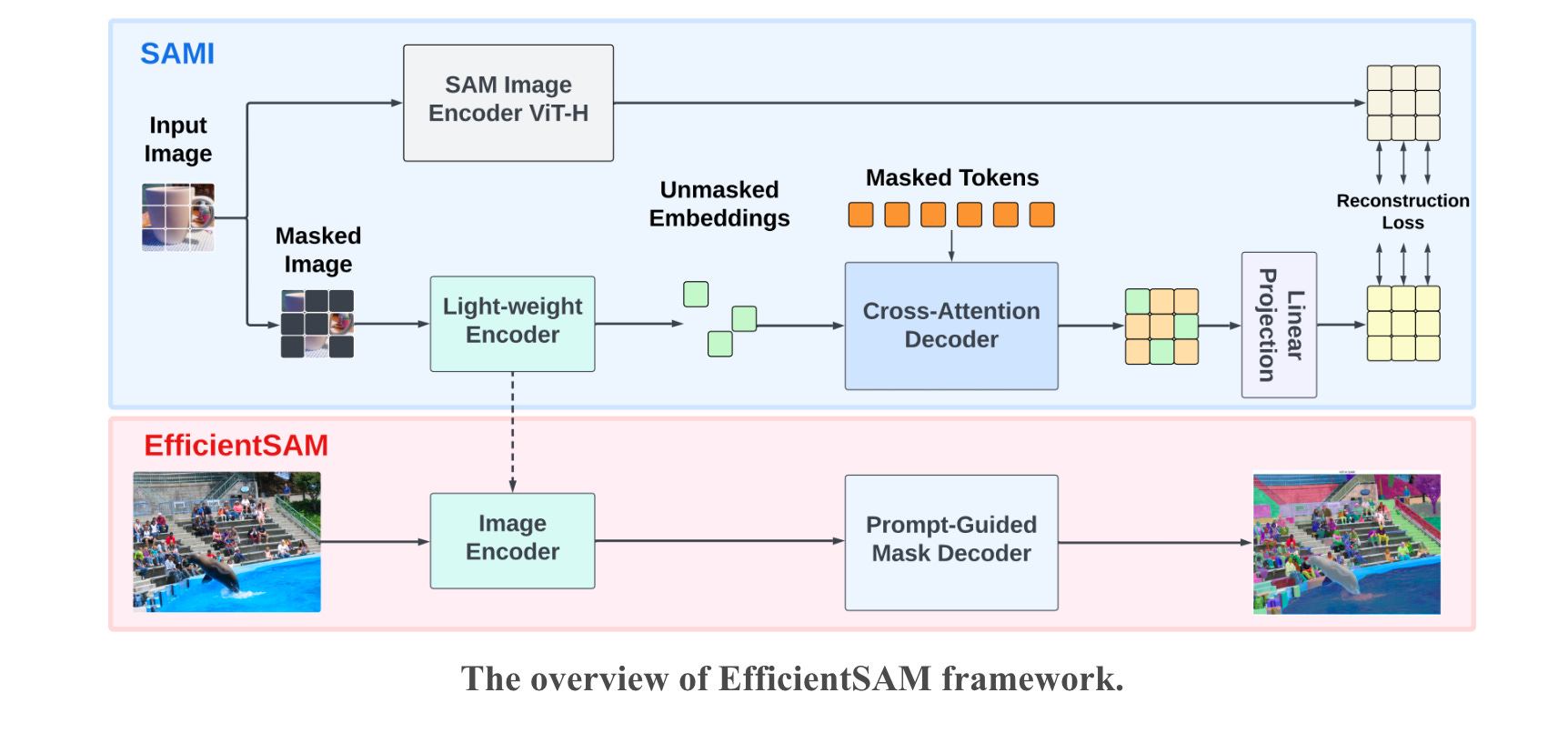
3.EfficientSAM:Leveraged Masked Image Pretraining for Efficient Segment Anything(paper | webpage)
The Segment Anything Model (SAM) excels in various vision tasks, mainly due to a super large Transformer model trained on the SA-1B dataset. However, its computational cost limits broader application. This study introduces EfficientSAMs, lighter versions of SAM that maintain good performance with reduced complexity. These models use masked image pretraining (SAMI), which reconstructs features from SAM's image encoder for effective visual representation. EfficientSAMs are built with SAMI-pretrained lightweight image encoders and mask decoder, then finetuned on SA-1B for versatile segmentation tasks. Evaluations across tasks like image classification and instance segmentation show that SAMI outperforms other pretraining methods. EfficientSAMs, particularly in zero-shot instance segmentation, significantly outperform faster SAM models, demonstrating their efficiency and effectiveness.
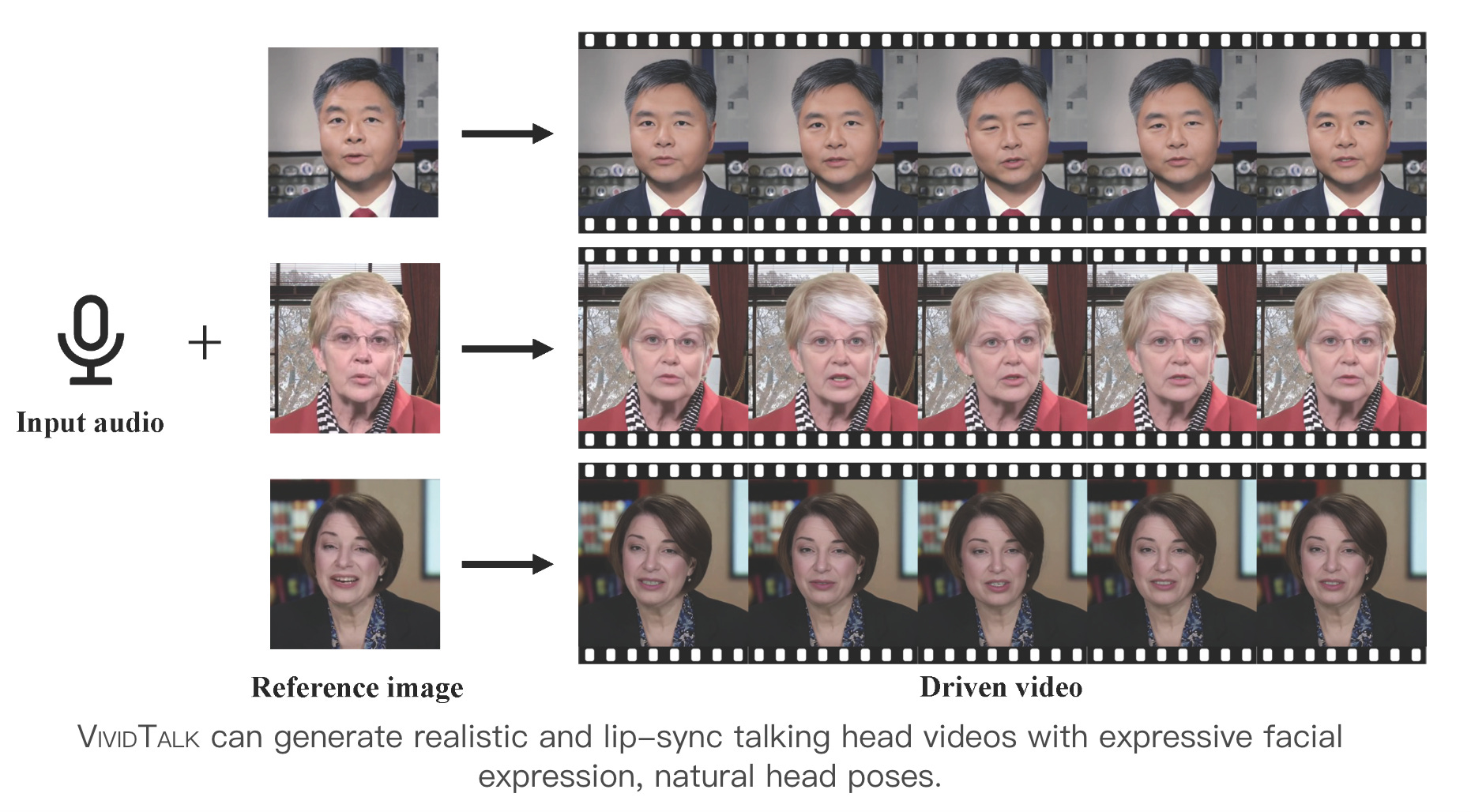
4.VividTalk: One-Shot Audio-Driven Talking Head Generation Based on 3D Hybrid Prior(paper | webpage)
VividTalk, a new two-stage framework, addresses the challenge in audio-driven talking head generation by excelling in lip-sync, facial expressions, head pose, and video quality. The first stage maps audio to mesh, learning non-rigid expression and rigid head motions. It uses blendshape and vertex representations for expressions, and a novel learnable head pose codebook with a two-phase training mechanism for head motion. The second stage involves a dual-branch motion-VAE and a generator, transforming meshes into dense motion and synthesizing high-quality video frames. Extensive experiments demonstrate that VividTalk significantly enhances visual quality, lip-sync, and realism, outperforming state-of-the-art models in objective and subjective assessments. The code will be available publicly upon publication.
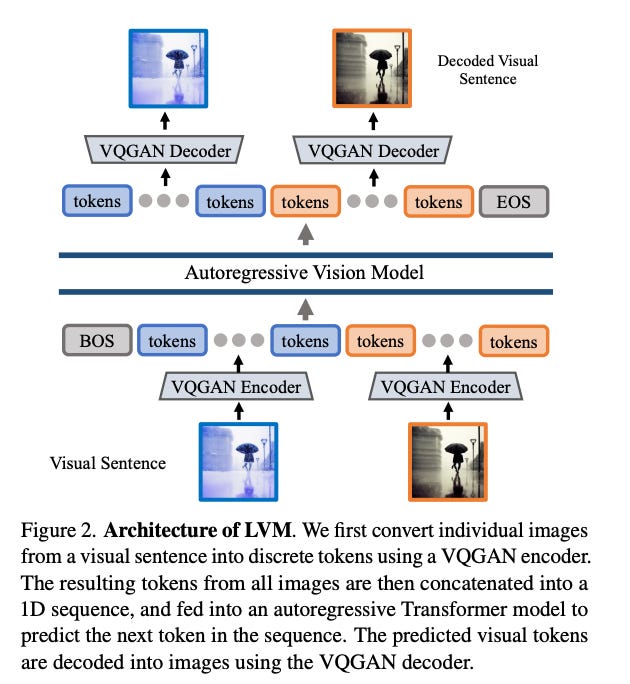
5.Sequential Modeling Enables Scalable Learning for Large Vision Models(paper)
The paper introduces a unique sequential modeling approach for training a Large Vision Model (LVM) without linguistic data. It employs "visual sentences," a universal format that represents raw images, videos, and annotated data like semantic segmentations and depth reconstructions, solely based on pixel information. This approach transforms diverse visual data (420 billion tokens) into sequences, allowing the model to learn through cross-entropy loss minimization for next token prediction. The effectiveness of this method is demonstrated through training with various scales of model architecture and data diversity. The versatility of the model is highlighted by its ability to solve different vision tasks using appropriately designed visual prompts during testing.
6.DragVideo: Interactive Drag-style Video Editing(paper)
7.Tree of Attacks: Jailbreaking Black-Box LLMs Automatically(paper)
8.Object Recognition as Next Token Prediction(paper)
AI News
1.Good old-fashioned AI remains viable in spite of the rise of LLMs(link)
2.Playground v2: A new leap in creativity (link)
3.Celebrating the first year of Copilot with significant new innovations(link)
4.NexusRaven-V2: Surpassing GPT-4 for Zero-shot Function Calling(link)
5.Introducing Scale’s Automotive Foundation Model(link)
6.Introducing Gemini: our largest and most capable AI model(google blog | Gemini technical report)
AI Repo
1.Apple's OpenSource ML Framework for Mac(mlx repo | examples )
2.llama-journey:Experimental adventure game with AI-generated content( repo )
3.X-Adapter: Adding Universal Compatibility of Plugins for Upgraded Diffusion Model( repo )