



Daily Papers
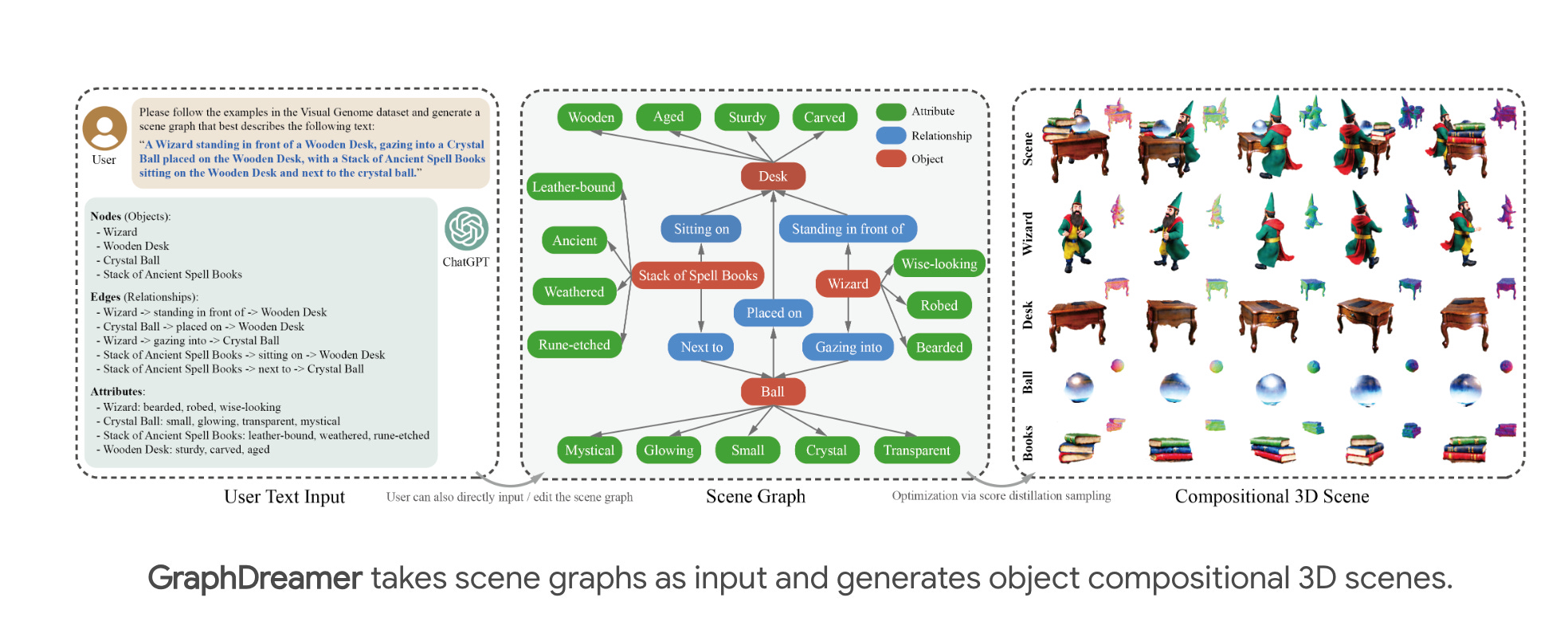
1.GraphDreamer: Compositional 3D Scene Synthesis from Scene Graphs(paper | webpage)
"GraphDreamer is a novel framework that generates 3D scenes from scene graphs, improving on text-to-image models by using nodes for objects and edges for interactions. It disentangles objects in complex scenes without image supervision, using signed distance fields to model relationships and avoid overlap. A text prompt for ChatGPT creates scene graphs, enhancing the generation of high-fidelity, compositional 3D scenes."
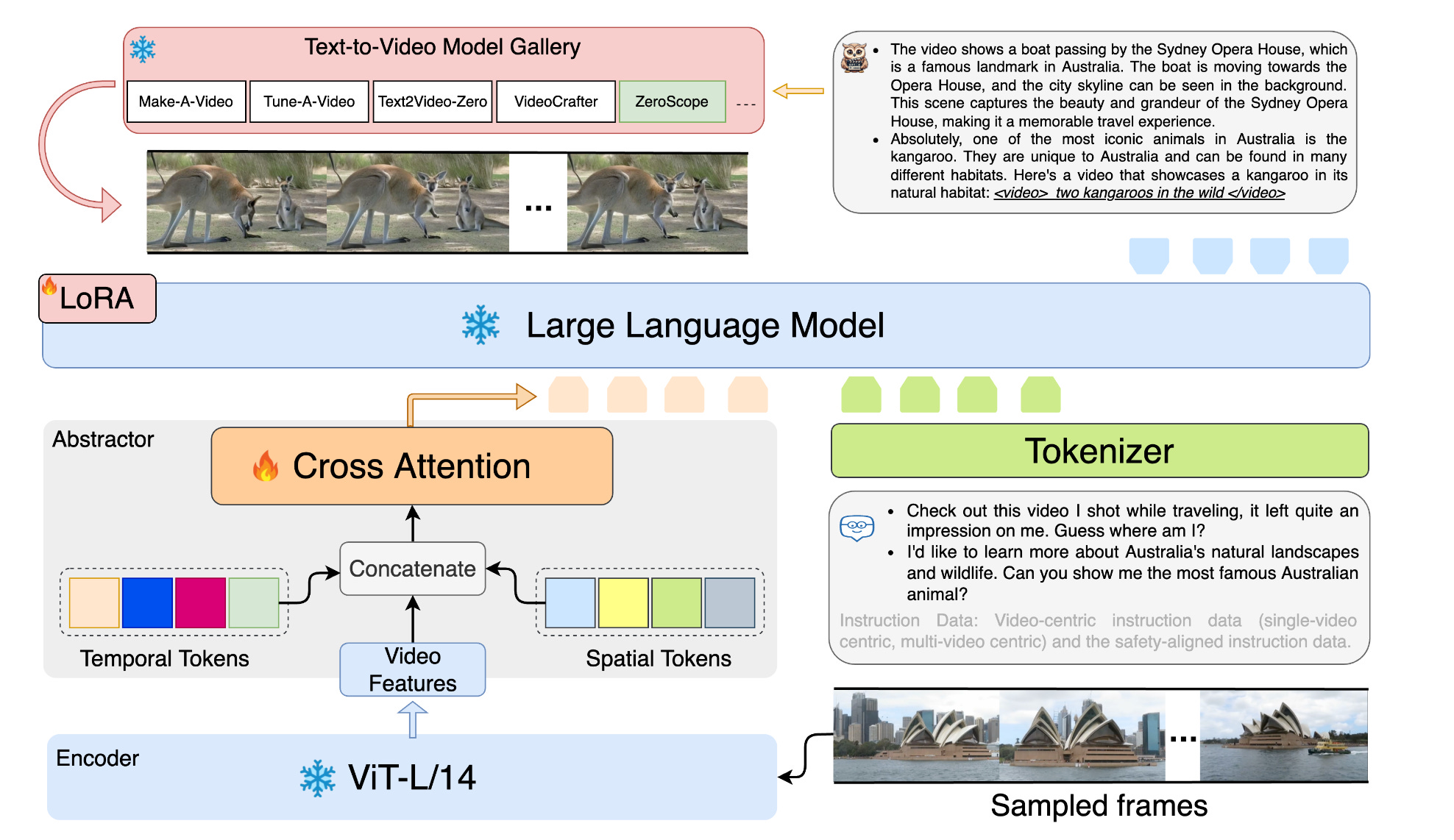
2.GPT4Video:A Unified Multimodal Large Language Model for lnstruction-Followed Understanding and Safety-Aware Generation(paper | webpage)
"GPT4Video is a groundbreaking multi-model framework enhancing Large Language Models with video understanding and generation capabilities. It integrates an instruction-following approach with the stable diffusion model for efficient and secure video generation. Outperforming existing models in video understanding and generation, GPT4Video doesn't require extra training parameters and works with various models. It ensures safe and healthy interactions, proving to be an effective, secure, and humanoid-like video assistant in both understanding and generating video content."
3.Beyond ChatBots: ExploreLLM for Structured Thoughts and Personalized Model Responses(paper)
"ExploreLLM revolutionizes the use of Large Language Models (LLMs) in chatbots by introducing a system that aids users in structuring thoughts, exploring options, and personalizing responses for complex tasks like trip planning. Traditional text-based LLMs lack structural support, making it challenging for users to navigate and express preferences. ExploreLLM addresses this by providing a schema-like structure, enabling more effective navigation and personalized interaction. User studies confirm its effectiveness in enhancing task-oriented dialogues, suggesting a future where LLMs integrate seamlessly with graphical interfaces for complex user tasks."

4.MoMask: Generative Masked Modeling of 3D Human Motions(paper | webpage)
"MoMask is an innovative framework for text-driven 3D human motion generation, leveraging a hierarchical quantization scheme to create detailed, discrete motion tokens. It uses two bidirectional transformers: one predicts base-layer motion tokens from text, and the other generates higher-layer tokens. MoMask excels in text-to-motion tasks, achieving significantly lower FID scores compared to other methods on datasets like HumanML3D and KIT-ML. It's also versatile, applicable to tasks like text-guided temporal inpainting without additional fine-tuning."
AI News
1.LLM Visualization(link)
2.ChatGPT one year on: who is using it, how and why?(nature link)
3.Illustrated LLM OS: An Implementational Perspective(hugging face blog)
4.Forecasting the future of artificial intelligence with machine learning-based link prediction in an exponentially growing knowledge network(nature link)
AI Repo
1.opengpts(repo)
2.Cloth2Tex: A Customized Cloth Texture Generation Pipeline for 3D Virtual Try-On(repo)