



Daily Papers
1.Visual Anagrams: Generating Multi-View Optical Illusions with Diffusion Models(paper | webpage)
We propose a zero-shot method to create multi-view optical illusions using text-to-image models. This involves estimating and combining noise from different views, enabling images to change appearance with transformations like flips or rotations. Our approach works for orthogonal transformations and extends to complex pixel permutations, demonstrating its effectiveness and versatility.

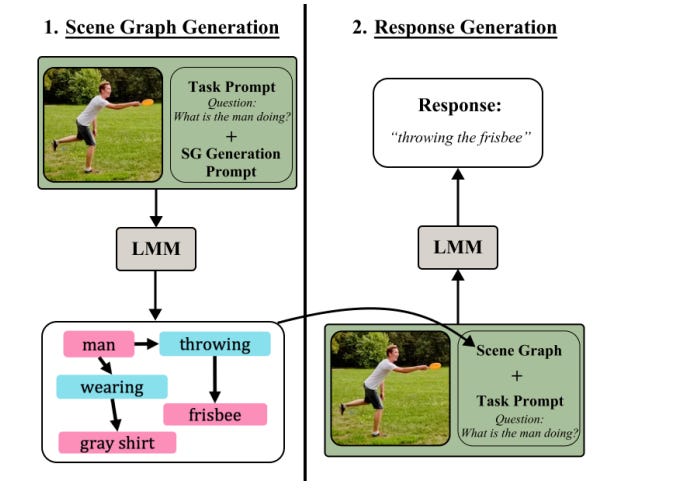
2.Compositional Chain-of-Thought Prompting for Large Multimodal Models(paper)
Recent research introduces Compositional Chain-of-Thought (CCoT), a novel method enhancing Large Multimodal Models (LMMs) in vision and language tasks. CCot utilizes scene graphs (SGs) to improve compositional visual reasoning, overcoming the limitations of expensive SG annotations and avoiding catastrophic forgetting in LMMs. This approach significantly boosts LMM performance on various benchmarks without requiring fine-tuning or annotated SGs.
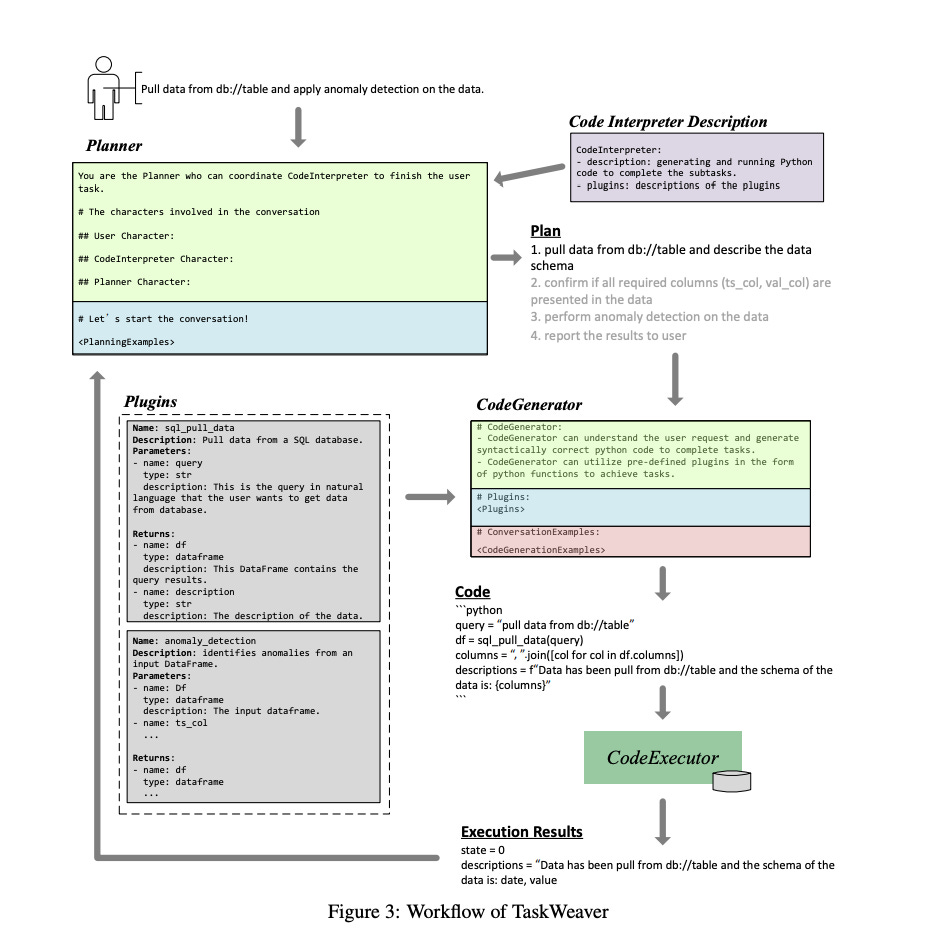
3.TaskWeaver: A Code-First Agent Framework(paper | code)
TaskWeaver, a code-first framework, enhances Large Language Models (LLMs) for domain-specific data analytics and flexible user needs. It transforms user requests into executable code, utilizes user-defined plugins, and supports rich data structures and dynamic plugin selection. Leveraging LLMs' coding capabilities for complex logic and incorporating domain-specific knowledge, TaskWeaver ensures secure code execution, offering a versatile solution for intelligent conversational agents in complex and specific scenarios.
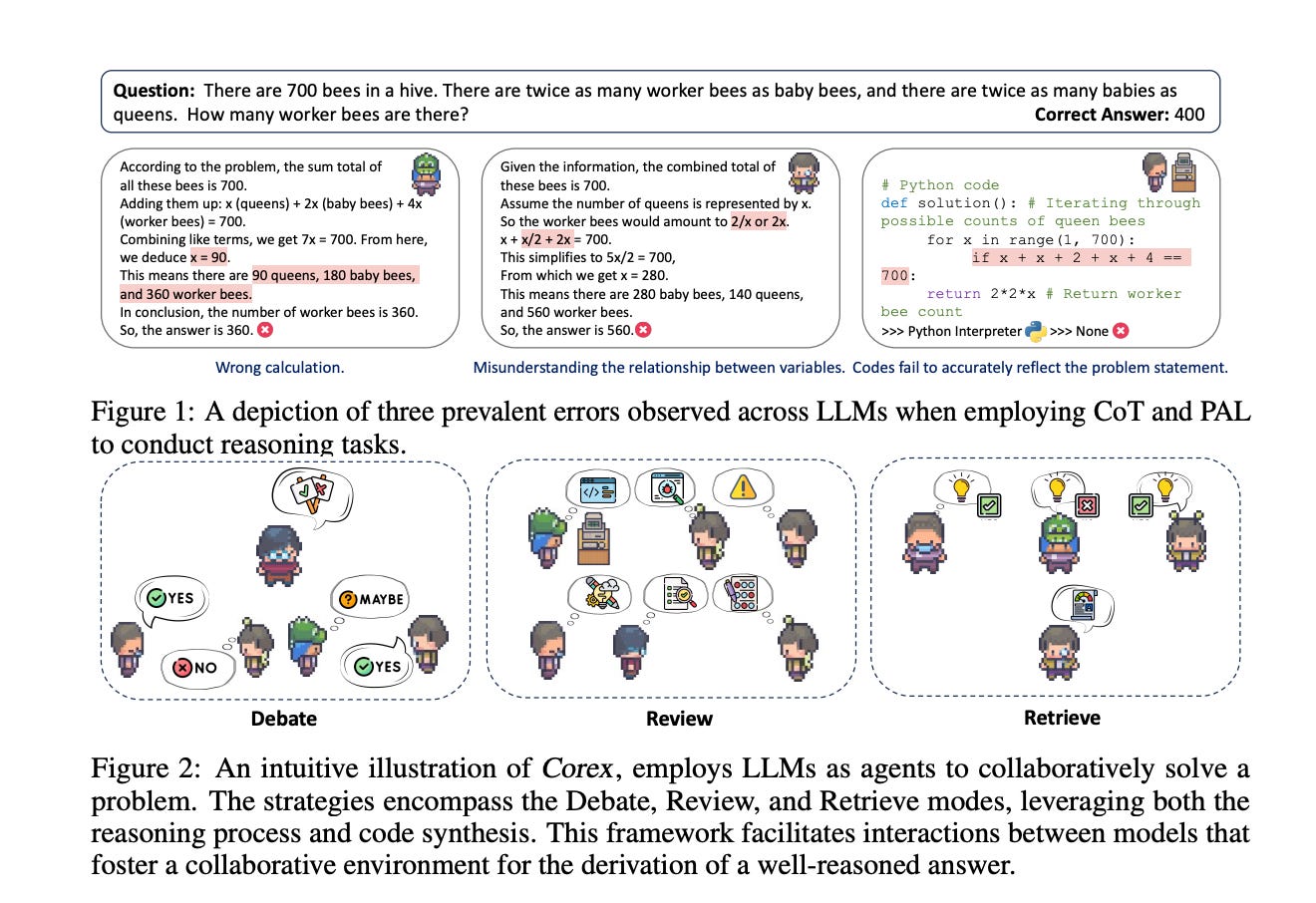
4.Corex: Pushing the Boundaries of Complex Reasoning through Multi-Model Collaboration(paper )
In response to the limitations of Large Language Models (LLMs) in reasoning tasks, this paper introduces Corex, a suite of novel strategies transforming LLMs into multi-model collaborative agents for complex problem-solving. Corex employs diverse collaboration paradigms, such as Debate, Review, and Retrieve modes, to enhance the accuracy and reliability of reasoning. These paradigms allow LLMs to adopt task-agnostic approaches, mitigating issues like hallucinations and improving solution quality. Extensive testing across various reasoning tasks shows that Corex, by coordinating multiple LLMs, significantly outperforms existing methods. Additionally, Corex demonstrates cost-effectiveness and efficiency in annotations, facilitating better collaboration among different LLMs.
5.Animate Anyone: Consistent and Controllable Image-to-Video Synthesis for Character Animation(paper | webpage)
This paper focuses on improving character animation in image-to-video conversion using diffusion models. Traditional methods face challenges in maintaining detailed consistency and temporal coherence in animated characters. To address this, the authors introduce a novel framework leveraging diffusion models for enhanced character animation. Key components include ReferenceNet, which integrates intricate appearance features from a reference image through spatial attention, and an efficient pose guider for controlling character movements. Additionally, a temporal modeling approach is employed to ensure smooth transitions between video frames. This framework is versatile, capable of animating a wide range of characters and achieving superior animation quality compared to other image-to-video methods. The method's effectiveness is demonstrated through state-of-the-art results in benchmarks for fashion videos and human dance synthesis, showcasing its potential in diverse animation scenarios.
AI News
1.Accelerating Generative AI with PyTorch II: GPT, Fast(pytorch blog)
2.RAGs To Riches: Bringing Wandbot into Production(blog)
3.llamafile is the new best way to run a LLM on your own computer(blog)
AI Repo
unsloth: 2x faster 50% less memory LLM finetuning(repo)
LaVie: Text-to-Video generation(huggingface space)
adapters:A Unified Library for Parameter-Efficient and Modular Transfer Learning (repo)
LaVie: High-Quality Video Generation with Cascaded Latent Diffusion Models(repo)
SEINE:Short-to-Long Video Diffusion Model for Generative Transition and Prediction(repo)
PixArt-LCM 1024px: a transformer-based text-to-image diffusion system trained on text embeddings from T5.(huggingface space)