



Daily Papers
1.Improving Text Embeddings with Large Language Models ( paper )
Key Points:
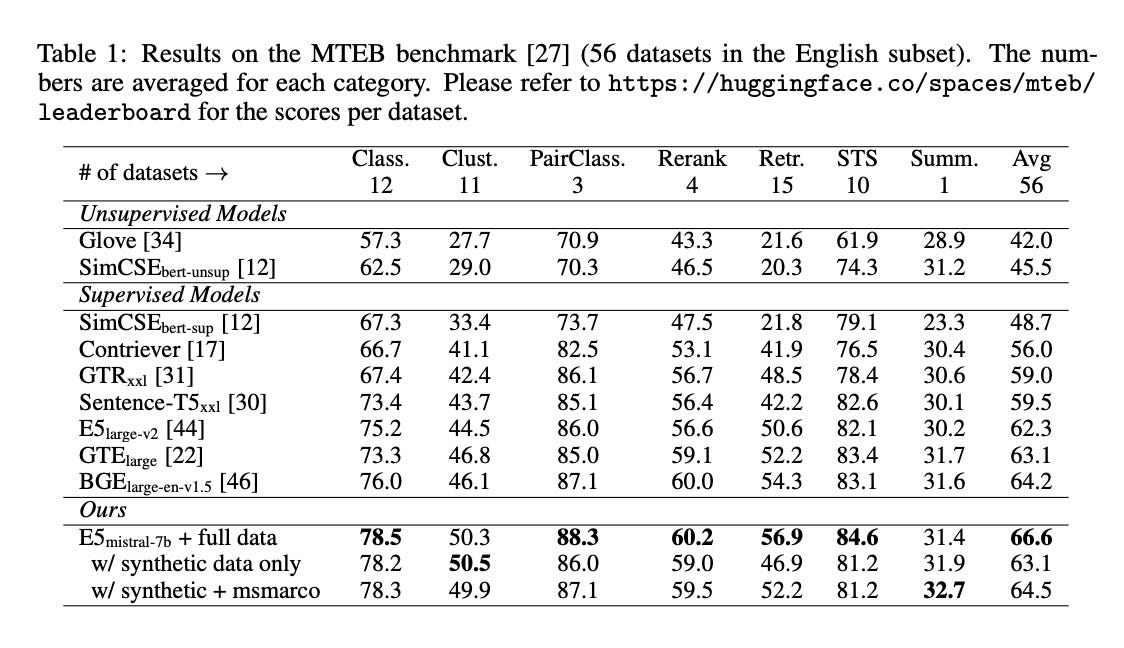
The paper introduces a novel method for obtaining high-quality text embeddings using synthetic data and less than 1k training steps.
It leverages proprietary LLMs to generate diverse synthetic data for text embedding tasks across nearly 100 languages.
The method uses a two-step prompting strategy for task generation and data creation, followed by fine-tuning on synthetic data with standard contrastive loss.
Experiments demonstrate strong performance on text embedding benchmarks without labeled data, and even better results when combined with labeled data.
The model shows effective performance on personalized passkey retrieval and can handle inputs up to 32k tokens.
Advantages:
The method simplifies the training process by eliminating the need for complex multi-stage pipelines and reliance on manually collected datasets.
It achieves competitive performance without using any labeled data, setting new benchmarks when fine-tuned with a mix of synthetic and labeled data.
The training process is efficient, requiring less than 1k steps, and the model can handle long-context tasks effectively.
Summary:
This paper presents a novel approach to text embeddings that leverages synthetic data generated by LLMs, achieving state-of-the-art performance with minimal training steps and without reliance on labeled data.
2.LARP: Language-Agent Role Play for Open-World Games( paper | webpage )
Key Points:
The paper introduces the Language Agent for Role-Playing (LARP) framework, designed for open-world games.
LARP includes a cognitive architecture for memory processing, a decision-making assistant, an environment interaction module, and a method for aligning diverse personalities.
The cognitive architecture is based on cognitive psychology and includes long-term memory, working memory, memory processing, and decision-making components.
The environment interaction module allows agents to interact with the game environment through a feedback-driven learnable action space.
The framework uses a cluster of smaller language models, each fine-tuned for different domains, to handle various tasks separately.
LARP aims to enhance the gaming experience in open-world contexts and demonstrates the potential of language models in entertainment, education, and simulation scenarios.
Advantages:
LARP provides a more realistic role-playing experience by integrating memory, decision-making, and continuous learning from interactions.
The modular approach allows for flexibility in adapting to complex environments and maintaining long-term memory.
The use of smaller, specialized language models addresses the challenges of general-purpose language agents in open-world games.
The framework promotes the alignment of various personalities, enhancing the diversity and realism of agents.
Summary:
LARP is a novel framework for integrating language agents into open-world games, utilizing cognitive architecture and specialized language models to enhance gaming experiences and agent diversity.
3.Building Efficient Universal Classifiers with Natural Language Inference ( paper )
Key Points:
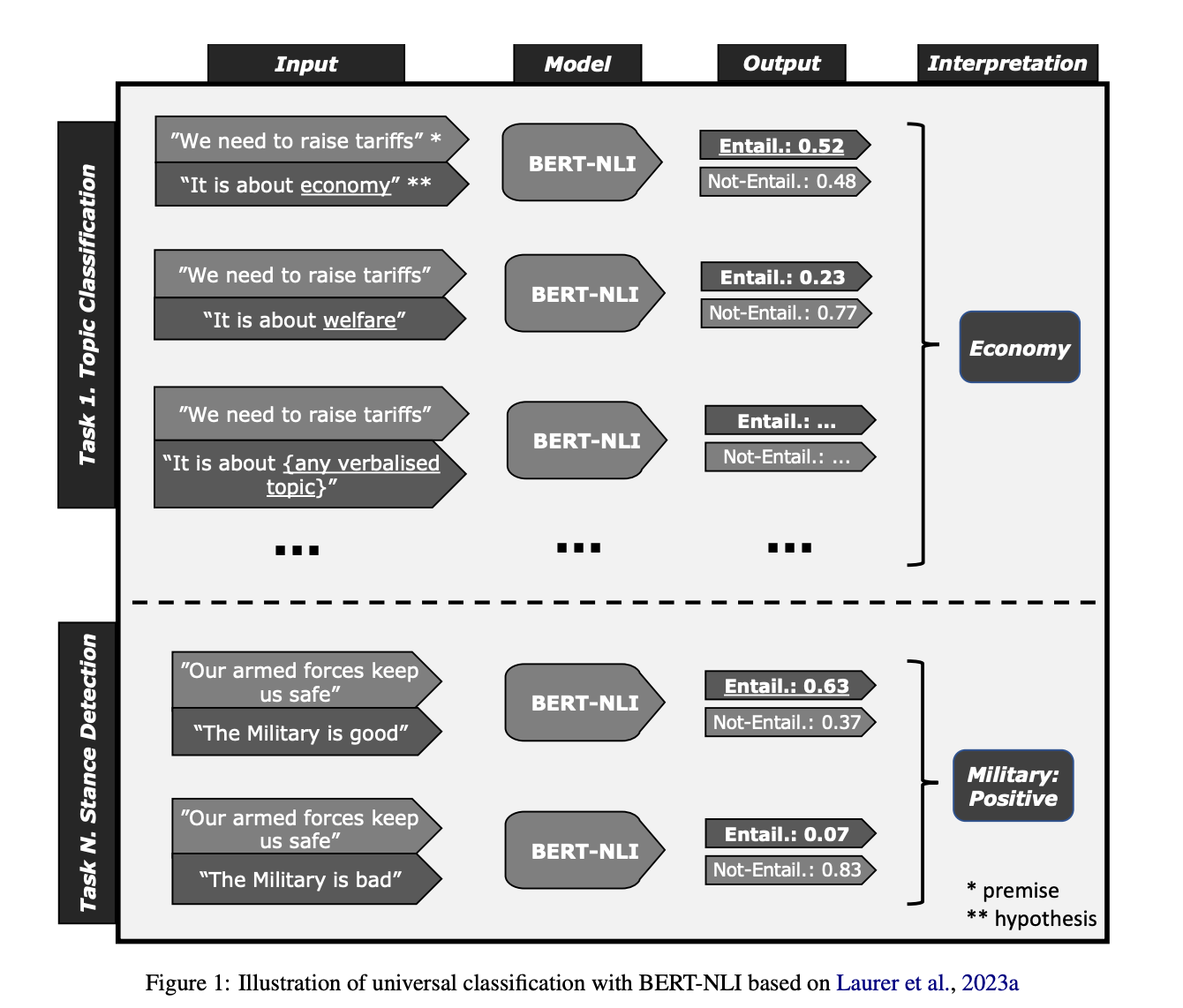
The paper introduces a method for building efficient universal classifiers using Natural Language Inference (NLI) as a universal classification task.
It provides a step-by-step guide with reusable Jupyter notebooks for building a universal classifier.
The resulting universal classifier is trained on 33 datasets with 389 diverse classes, improving zero-shot performance by 9.4% compared to NLI-only models.
The authors share code that has been used to train older zero-shot classifiers, downloaded over 55 million times via the Hugging Face Hub.
The paper discusses limitations, such as the diversity of academic datasets, potential data noise, and the computational overhead of NLI for zero-shot classification.
Advantages:
The method allows for zero-shot classification without fine-tuning, which is more efficient than generative LLMs.
It provides a practical guide with Jupyter notebooks, making it accessible to users.
The universal classifier achieves strong performance across various tasks, demonstrating its versatility.
The paper's approach leverages the principles of NLI, which is a simpler and more efficient task than generating text.
Summary:
This paper presents a novel approach to building efficient universal classifiers using Natural Language Inference, offering a step-by-step guide and achieving improved zero-shot performance without the need for task-specific fine-tuning.
4.FlowVid: Taming Imperfect Optical Flows for Consistent Video-to-Video Synthesis ( paper | webpage )
5.Task Contamination: Language Models May Not Be Few-Shot Anymore ( paper )
AI News
1.Can LLMs make medicine safer? ( link )
2.LLMs and Programming in the first days of 2024 ( link )
3.AI: The Coming Revolution ( link )
AI Repos
1.nanoGPT_mlx: Port of Andrej Karpathy's nanoGPT to Apple MLX framework ( repo )
2.Mixtral offloading ( repo )
3.llm-course:Course to get into Large Language Models (LLMs) with roadmaps and Colab notebooks ( repo )