



Daily Papers
1.UniVG: Towards UNIfied-modal Video Generation( paper | webpage )
Diffusion based video generation has received extensive attention and achieved considerable success within both the academic and industrial communities. However, current efforts are mainly concentrated on single-objective or single-task video generation, such as generation driven by text, by image, or by a combination of text and image. This cannot fully meet the needs of real-world application scenarios, as users are likely to input images and text conditions in a flexible manner, either individually or in combination. To address this, we propose a Unified-modal Video Genearation system that is capable of handling multiple video generation tasks across text and image modalities. To this end, we revisit the various video generation tasks within our system from the perspective of generative freedom, and classify them into high-freedom and low-freedom video generation categories. For high-freedom video generation, we employ Multi-condition Cross Attention to generate videos that align with the semantics of the input images or text. For low-freedom video generation, we introduce Biased Gaussian Noise to replace the pure random Gaussian Noise, which helps to better preserve the content of the input conditions. Our method achieves the lowest Fréchet Video Distance (FVD) on the public academic benchmark MSR-VTT, surpasses the current open-source methods in human evaluations, and is on par with the current close-source method Gen2.

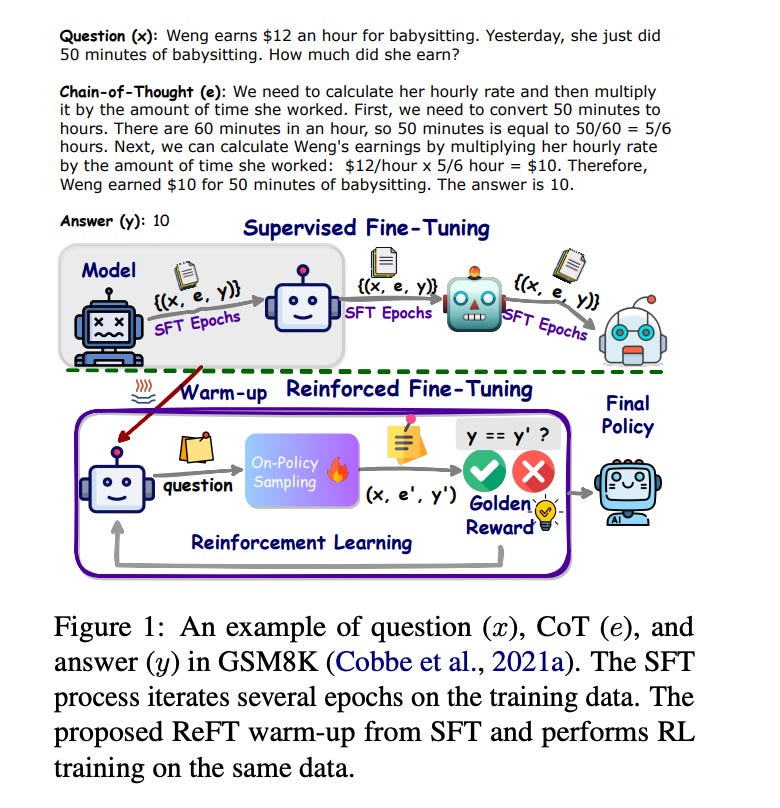
2.ReFT: Reasoning with Reinforced Fine-Tuning( paper )
One way to enhance the reasoning capability of Large Language Models (LLMs) is to conduct Supervised Fine-Tuning (SFT) using Chain-of-Thought (CoT) annotations. This approach does not show sufficiently strong generalization ability, however, because the training only relies on the given CoT data. In math problem-solving, for example, there is usually only one annotated reasoning path for each question in the training data. Intuitively, it would be better for the algorithm to learn from multiple annotated reasoning paths given a question. To address this issue, we propose a simple yet effective approach called Reinforced Fine-Tuning (ReFT) to enhance the generalizability of learning LLMs for reasoning, with math problem-solving as an example. ReFT first warmups the model with SFT, and then employs on-line reinforcement learning, specifically the PPO algorithm in this paper, to further fine-tune the model, where an abundance of reasoning paths are automatically sampled given the question and the rewards are naturally derived from the ground-truth answers. Extensive experiments on GSM8K, MathQA, and SVAMP datasets show that ReFT significantly outperforms SFT, and the performance can be potentially further boosted by combining inference-time strategies such as majority voting and re-ranking. Note that ReFT obtains the improvement by learning from the same training questions as SFT, without relying on extra or augmented training questions. This indicates a superior generalization ability for ReFT.
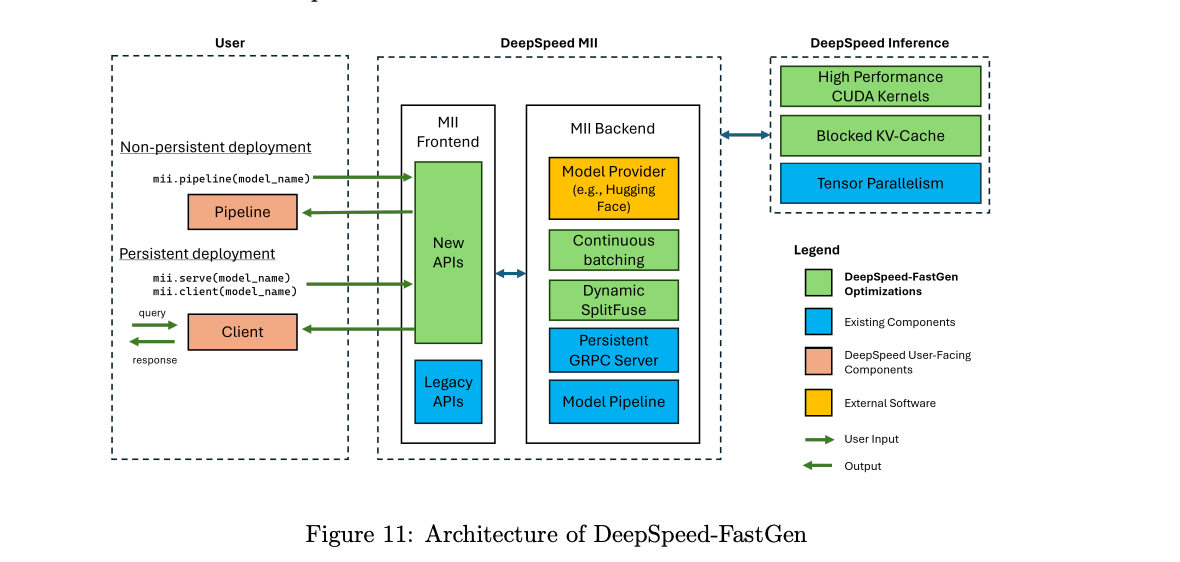
3.DeepSpeed-FastGen: High-throughput Text Generation for LLMs via MII and DeepSpeed-Inference( paper )
The deployment and scaling of large language models (LLMs) have become critical as they permeate various applications, demanding high-throughput and low-latency serving systems. Existing frameworks struggle to balance these requirements, especially for workloads with long prompts. This paper introduces DeepSpeed-FastGen, a system that employs Dynamic SplitFuse, a novel prompt and generation composition strategy, to deliver up to 2.3x higher effective throughput, 2x lower latency on average, and up to 3.7x lower (token-level) tail latency, compared to state-of-the-art systems like vLLM. We leverage a synergistic combination of DeepSpeed-MII and DeepSpeed-Inference to provide an efficient and easy-to-use serving system for LLMs. DeepSpeed-FastGen's advanced implementation supports a range of models and offers both non-persistent and persistent deployment options, catering to diverse user scenarios from interactive sessions to long-running applications. We present a detailed benchmarking methodology, analyze the performance through latency-throughput curves, and investigate scalability via load balancing. Our evaluations demonstrate substantial improvements in throughput and latency across various models and hardware configurations. We discuss our roadmap for future enhancements, including broader model support and new hardware backends. The DeepSpeed-FastGen code is readily available for community engagement and contribution.
4.PRewrite: Prompt Rewriting with Reinforcement Learning ( paper )
5.Google DeepMind: Solving olympiad geometry without human demonstrations ( paper | code )
AI News
1.Media Alert: Adobe Premiere Pro Innovations Make Audio Editing Faster, Easier and More Intuitive ( link )
2.Enter the New Era of Mobile AI With Samsung Galaxy S24 Series(link)
3.SHORT COURSE: LLMOps (link)
AI Repos
1.SiT: Exploring Flow and Diffusion-based Generative Models with Scalable Interpolant Transformers( repo )
2.Entropy-ABF: Extending LLMs' Context Window with 100 Samples ( repo )
3.AIM: Autoregressive Image Models ( repo )