



Daily Papers
1. LEGO:Language Enhanced Multi-modal Grounding Model ( paper | webpage)
LEGO is an end-to-end multimodal grounding model that accurately comprehends inputs and possesses robust grounding capabilities across multi modalities,including images, audios, and videos. To address the issue of limited data, we construct a diverse and high-quality multimodal training dataset. This dataset encompasses a rich collection of multimodal data enriched with spatial and temporal information, thereby serving as a valuable resource to foster further advancements in this field. Extensive experimental evaluations validate the effectiveness of the LEGO model in understanding and grounding tasks across various modalities.

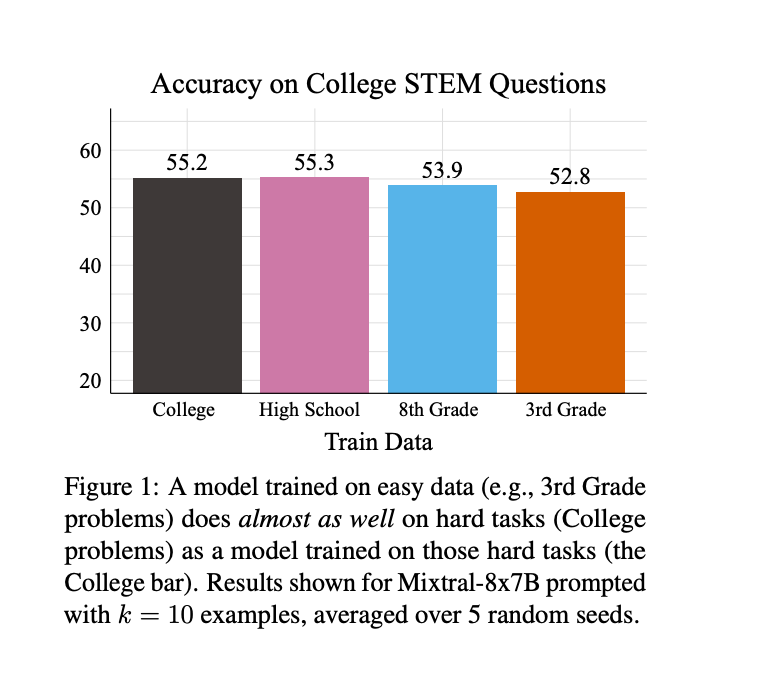
2.The Unreasonable Effectiveness of Easy Training Data for Hard Tasks ( paper | code )
How can we train models to perform well on hard test data when hard training data is by definition difficult to label correctly? This question has been termed the scalable oversight problem and has drawn increasing attention as language models have continually improved. In this paper, we present the surprising conclusion that current language models often generalize relatively well from easy to hard data, even performing as well as "oracle" models trained on hard data. We demonstrate this kind of easy-to-hard generalization using simple training methods like in-context learning, linear classifier heads, and QLoRA for seven different measures of datapoint hardness, including six empirically diverse human hardness measures (like grade level) and one model-based measure (loss-based). Furthermore, we show that even if one cares most about model performance on hard data, it can be better to collect and train on easy data rather than hard data, since hard data is generally noisier and costlier to collect. Our experiments use open models up to 70b in size and four publicly available question-answering datasets with questions ranging in difficulty from 3rd grade science questions to college level STEM questions and general-knowledge trivia. We conclude that easy-to-hard generalization in LMs is surprisingly strong for the tasks studied, suggesting the scalable oversight problem may be easier than previously thought.
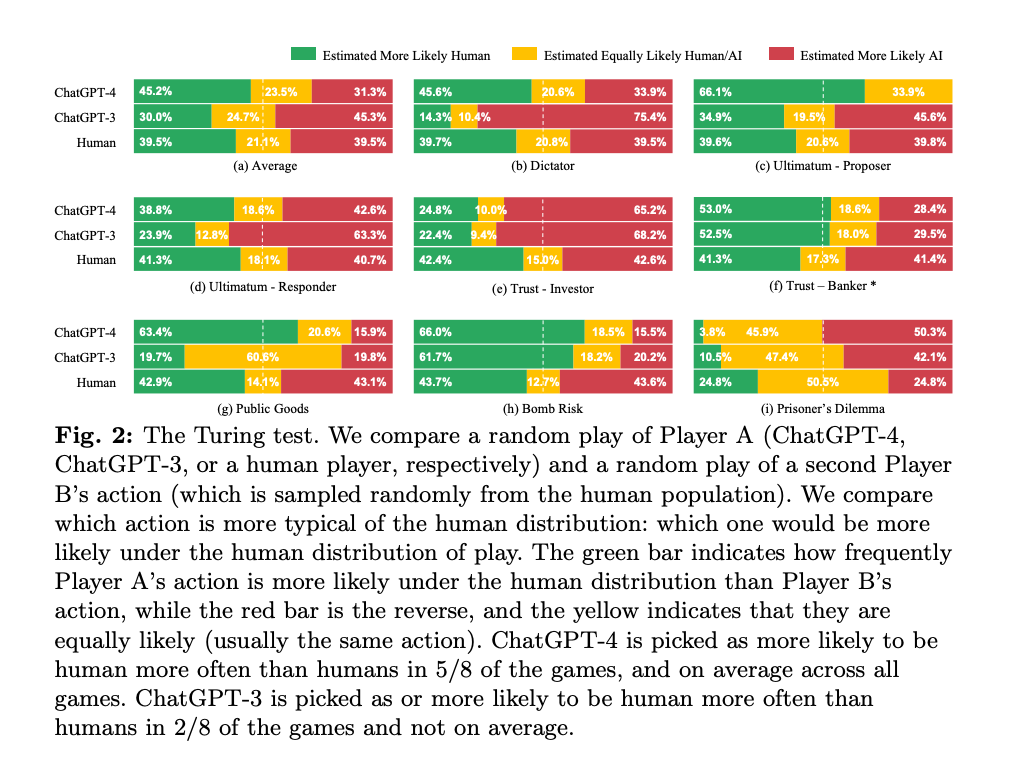
3.A Turing Test: Are Ai Chatbots Behaviorally Similar to Humans? ( paper )
We administer a Turing Test to AI Chatbots. We examine how Chatbots behave in a suite of classic behavioral games that are designed to elicit characteristics such as trust, fairness, risk-aversion, cooperation, \textit{etc.}, as well as how they respond to a traditional Big-5 psychological survey that measures personality traits. ChatGPT-4 exhibits behavioral and personality traits that are statistically indistinguishable from a random human from tens of thousands of human subjects from more than 50 countries. Chatbots also modify their behavior based on previous experience and contexts ``as if'' they were learning from the interactions, and change their behavior in response to different framings of the same strategic situation. Their behaviors are often distinct from average and modal human behaviors, in which case they tend to behave on the more altruistic and cooperative end of the distribution. We estimate that they act as if they are maximizing an average of their own and partner's payoffs.
AI News
Patterns for Building LLM-based Systems & Products( link )
OpenAI: Democratic inputs to AI grant program: lessons learned and implementation plans ( link )
SakanaAI: We raised $30M to develop nature-inspired AI in Japan ( link )