



Daily Papers
1.MoE-Mamba: Efficient Selective State Space Models with Mixture of Experts ( paper )
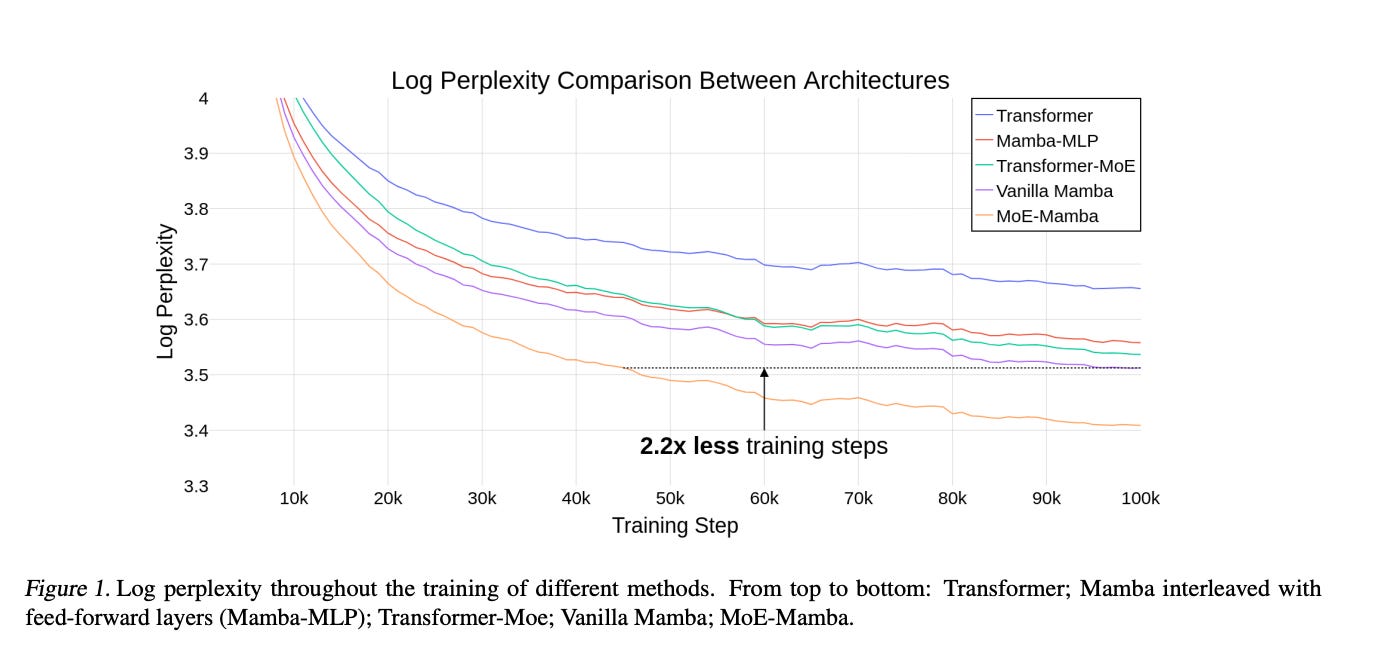
State Space Models (SSMs) have become serious contenders in the field of sequential modeling, challenging the dominance of Transformers. At the same time, Mixture of Experts (MoE) has significantly improved Transformer-based LLMs, including recent state-of-the-art open-source models. We propose that to unlock the potential of SSMs for scaling, they should be combined with MoE. We showcase this on Mamba, a recent SSM-based model that achieves remarkable, Transformer-like performance. Our model, MoE-Mamba, outperforms both Mamba and Transformer-MoE. In particular, MoE-Mamba reaches the same performance as Mamba in 2.2x less training steps while preserving the inference performance gains of Mamba against the Transformer.
2. Combating Adversarial Attacks with Multi-Agent Debate ( paper )
While state-of-the-art language models have achieved impressive results, they remain susceptible to inference-time adversarial attacks, such as adversarial prompts generated by red teams arXiv:2209.07858. One approach proposed to improve the general quality of language model generations is multi-agent debate, where language models self-evaluate through discussion and feedback arXiv:2305.14325. We implement multi-agent debate between current state-of-the-art language models and evaluate models' susceptibility to red team attacks in both single- and multi-agent settings. We find that multi-agent debate can reduce model toxicity when jailbroken or less capable models are forced to debate with non-jailbroken or more capable models. We also find marginal improvements through the general usage of multi-agent interactions. We further perform adversarial prompt content classification via embedding clustering, and analyze the susceptibility of different models to different types of attack topics.

Efficient LLM inference solution on Intel GPU ( paper )
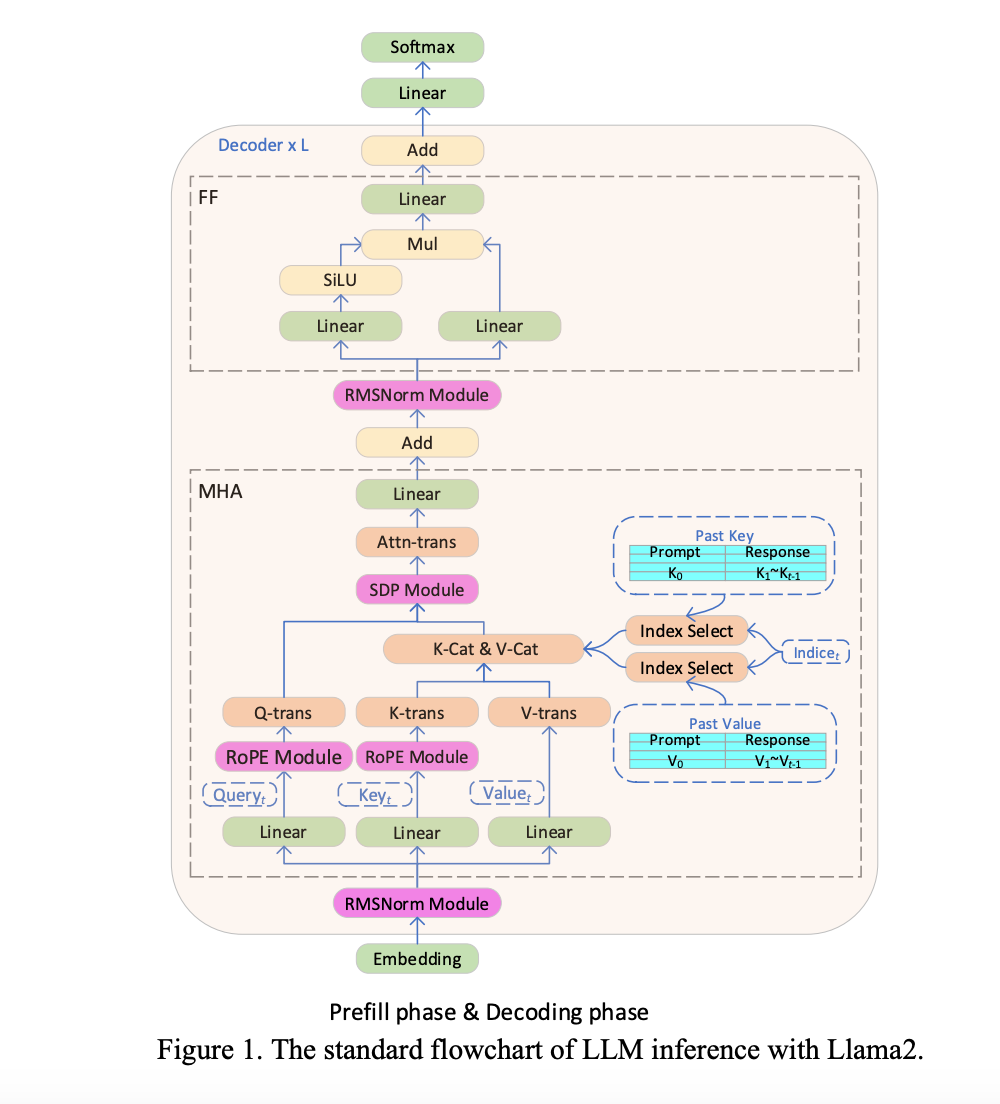
Transformer based Large Language Models (LLMs) have been widely used in many fields, and the efficiency of LLM inference becomes hot topic in real applications. However, LLMs are usually complicatedly designed in model structure with massive operations and perform inference in the auto-regressive mode, making it a challenging task to design a system with high efficiency.
In this paper, we propose an efficient LLM inference solution with low latency and high throughput. Firstly, we simplify the LLM decoder layer by fusing data movement and element-wise operations to reduce the memory access frequency and lower system latency. We also propose a segment KV cache policy to keep key/value of the request and response tokens in separate physical memory for effective device memory management, helping enlarge the runtime batch size and improve system throughput. A customized Scaled-Dot-Product-Attention kernel is designed to match our fusion policy based on the segment KV cache solution. We implement our LLM inference solution on Intel GPU and publish it publicly. Compared with the standard HuggingFace implementation, the proposed solution achieves up to 7x lower token latency and 27x higher throughput for some popular LLMs on Intel GPU.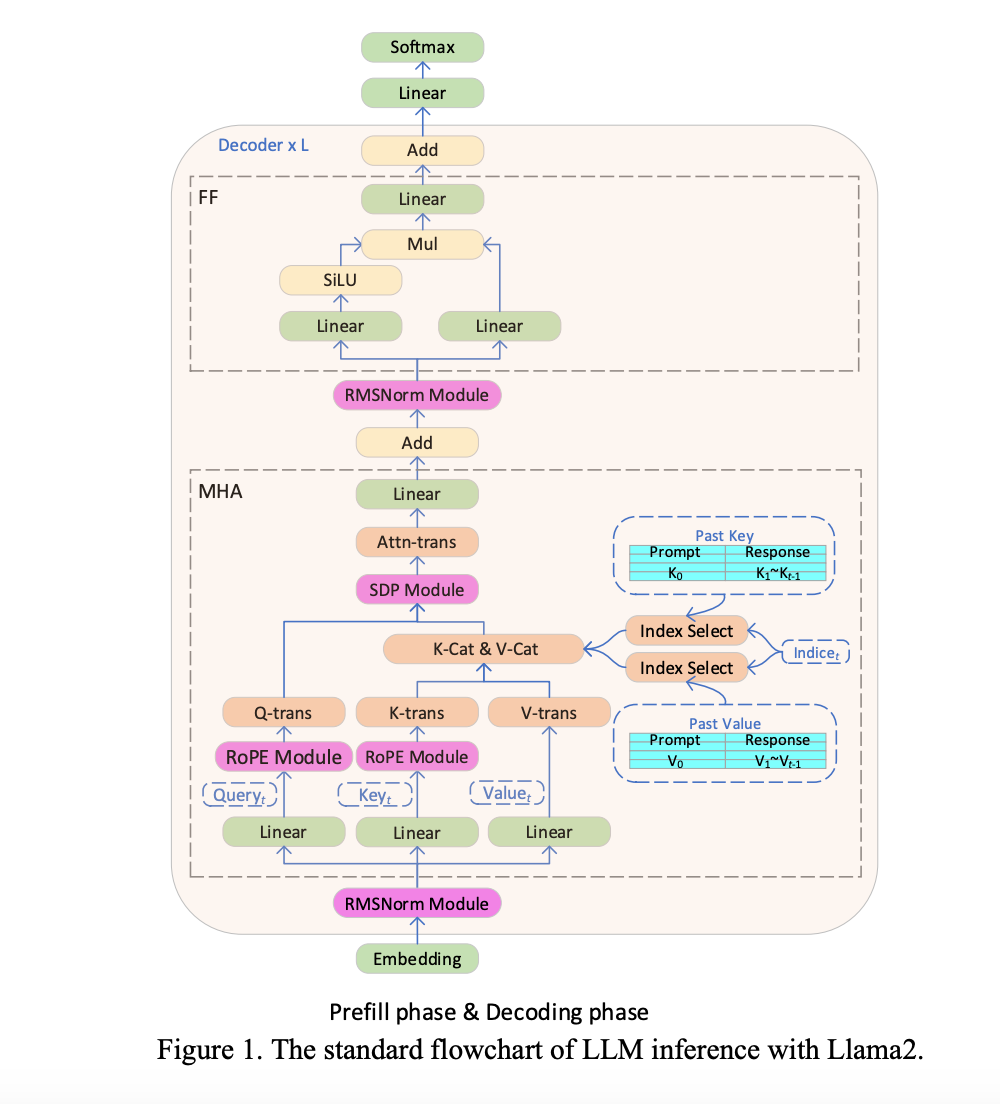
AI News
Understanding and Coding Self-Attention, Multi-Head Attention, Cross-Attention, and Causal-Attention in LLMs ( link )
Gen AI Frameworks and Tools Every AI/ML Engineer Should Know! ( link )
AI Voice Assistant: Enhancing Accessibility in AI with LlamaIndex and GPT3.5 ( link )
AI Repos
PhotoMaker: Customizing Realistic Human Photos via Stacked ID Embedding ( huggingface | code )