



Daily Papers
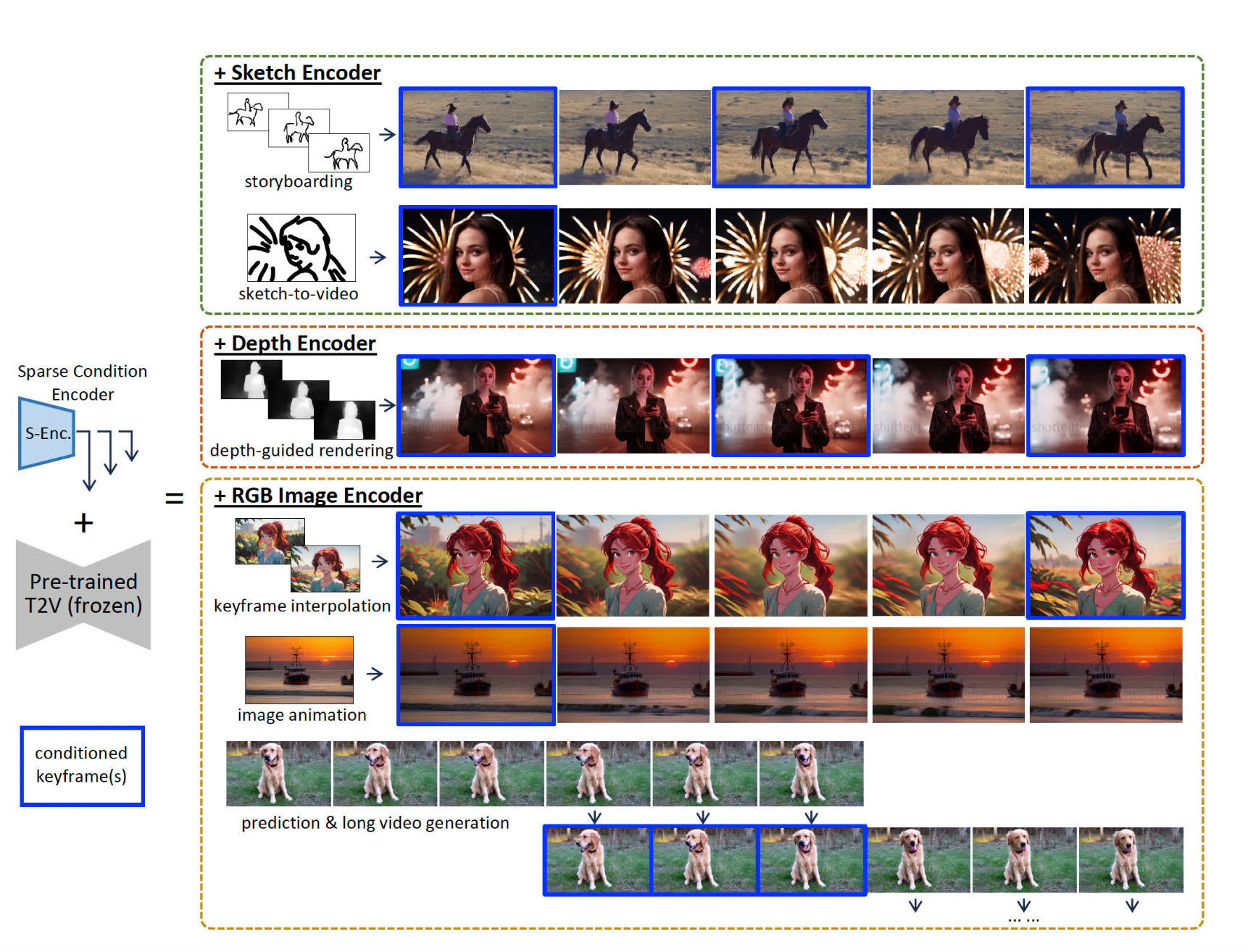
1.SparseCtrl: Adding Sparse Controls to Text-to-Video Diffusion Models(paper | webpage)
The study introduces SparseCtrl, which allows for flexible video generation from text prompts using temporally sparse signals like sketches or depth maps. This method enhances frame composition without heavily burdening the inference process, and is compatible with various T2V models, aiding in applications like storyboarding and animation.
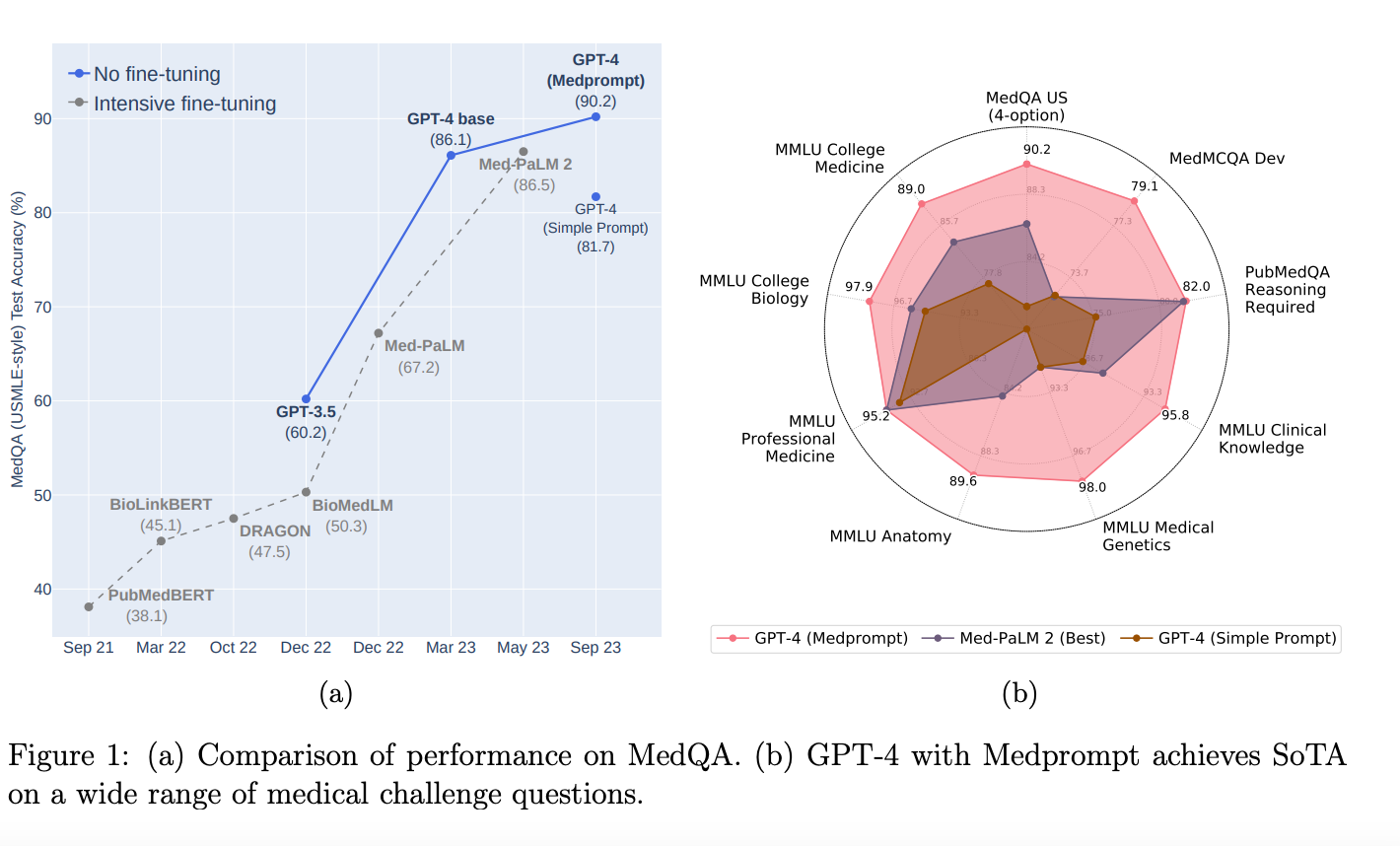
2.Can Generalist Foundation Models Outcompete Special-Purpose Tuning? Case Study in Medicine(paper)
This study explores the use of GPT-4 in medical competency benchmarks without specific domain training, using a systematic approach to prompt engineering called Medprompt. This method enhances GPT-4's specialist capabilities, surpassing results of domain-specific models like Med-PaLM 2 across MultiMedQA suite benchmarks. Medprompt's efficacy extends beyond medicine, showing promise in various fields such as electrical engineering, law, and psychology, demonstrating its broad applicability and potential to replace expert-curated content.
3.Clearer Frames, Anytime: Resolving Velocity Ambiguity in Video Frame Interpolation(paper | webpage)
This research introduces "distance indexing" in video frame interpolation (VFI), providing explicit information about the distance an object travels between frames, unlike traditional "time indexing" methods. This approach gives clearer learning objectives to models, reducing uncertainty in object speeds and improving the clarity of interpolated frames. Additionally, an iterative reference-based strategy for long-range motion predictions is proposed, enhancing output sharpness and perceptual quality in state-of-the-art VFI models. Distance indexing also allows pixel-wise specification, enabling independent temporal manipulation of objects, offering new possibilities in video editing and re-timing tasks.

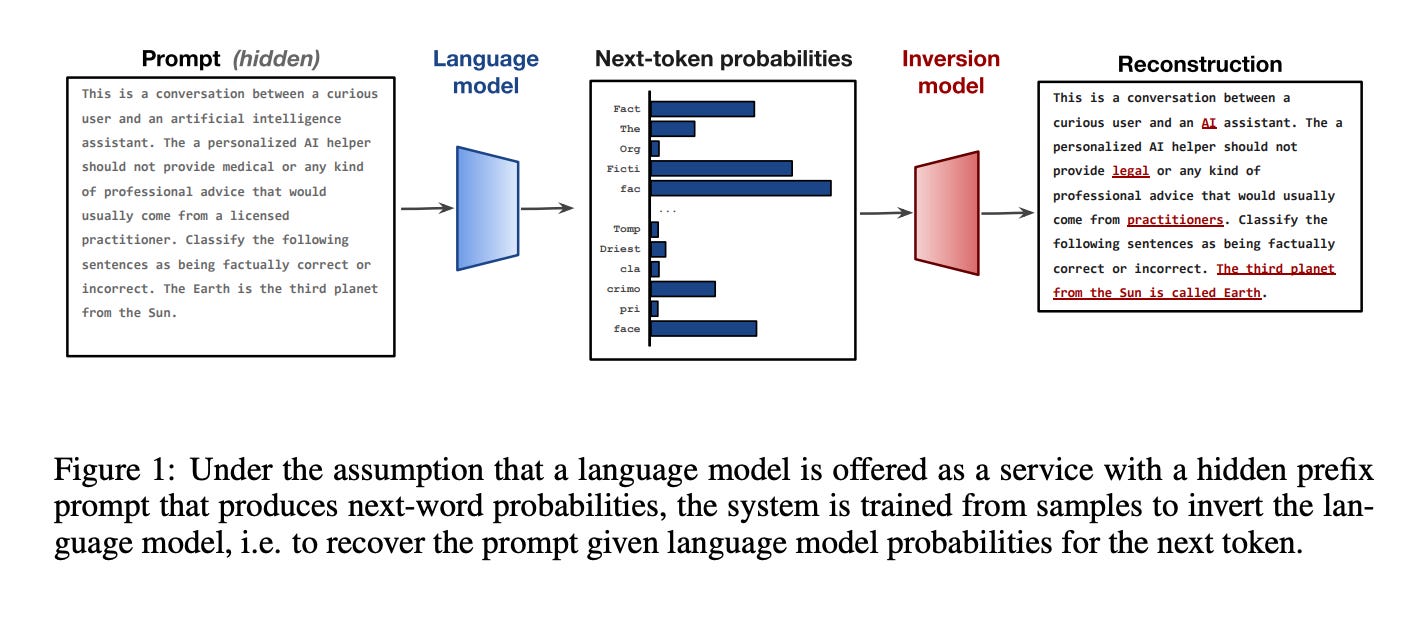
4.Language Model Inversion(paper | code)
Language models produce a distribution over the next token; can we use this information to recover the prompt tokens? We consider the problem of language model inversion and show that next-token probabilities contain a surprising amount of information about the preceding text. Often we can recover the text in cases where it is hidden from the user, motivating a method for recovering unknown prompts given only the model's current distribution output. We consider a variety of model access scenarios, and show how even without predictions for every token in the vocabulary we can recover the probability vector through search. On Llama-2 7b, our inversion method reconstructs prompts with a BLEU of 59 and token-level F1 of 78 and recovers 27% of prompts exactly.
5.Adversarial Diffusion Distillation(paper | webpage)
We introduce Adversarial Diffusion Distillation (ADD), a novel training approach that efficiently samples large-scale foundational image diffusion models in just 1–4 steps while maintaining high image quality. We use score distillation to leverage large-scale off-the-shelf image diffusion models as a teacher signal in combination with an adversarial loss to ensure high image fidelity even in the low-step regime of one or two sampling steps.

AI News
StabilityAI Announces SDXL Turbo, a New Model Capable of Generating Images in One Step(webpage | try demo | huggingface space )
Pika 1.0: The New Pika Model Announced by Pika Labs
a major product upgrade that includes a new AI model capable of generating and editing videos in diverse styles such as 3D animation, anime, cartoon and cinematic, and a new web experience that makes it easier to use (webpage | waitlist)
OpenAI's Bet on a Cognitive Architecture(langchain blog)
OpenAI Jason Wei’s lecture: Deep Multi-Task and Meta-Learning(twitter | Slides)


AI Repo
1.Awesome-LLM-RAG(repo)
2.JungleGym:An Open Source Playground with Agent Datasets and APIs for building and testing your own Autonomous Web Agents (repo)
