



Daily Papers
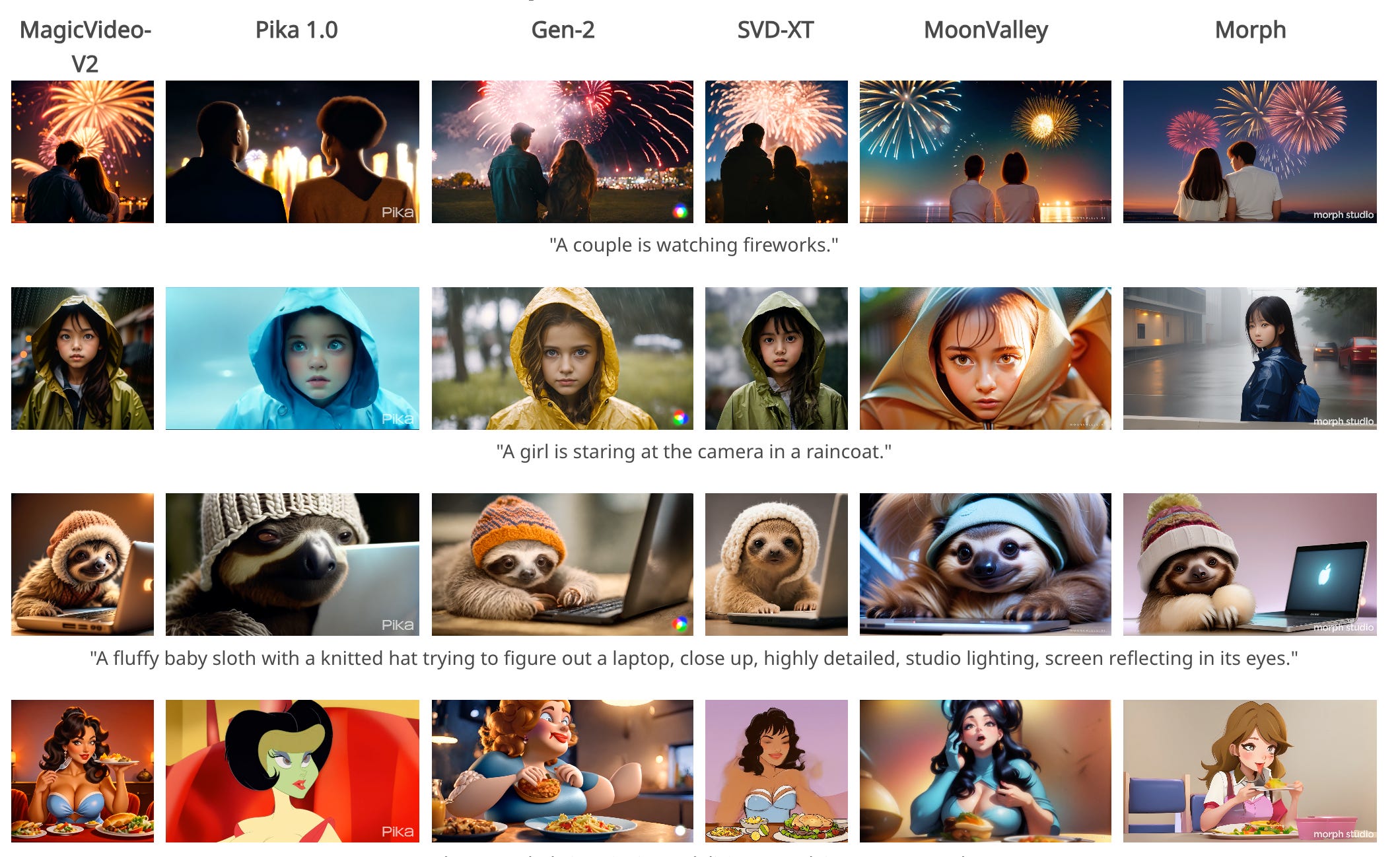
1.MagicVideo-V2: Multi-Stage High-Aesthetic Video Generation( paper | webpage )
The growing demand for high-fidelity video generation from textual descriptions has catalyzed significant research in this field. In this work, we introduce MagicVideo-V2 that integrates the text-to-image model, video motion generator, reference image embedding module and frame interpolation module into an end-to-end video generation pipeline. Benefiting from these architecture designs, MagicVideo-V2 can generate an aesthetically pleasing, high-resolution video with remarkable fidelity and smoothness. It demonstrates superior performance over leading Text-to-Video systems such as Runway, Pika 1.0, Morph, Moon Valley and Stable Video Diffusion model via user evaluation at large scale.
2.Jump Cut Smoothing for Talking Heads (paper | webpage)
A jump cut offers an abrupt, sometimes unwanted change in the viewing experience. We present a novel framework for smoothing these jump cuts, in the context of talking head videos. We leverage the appearance of the subject from the other source frames in the video, fusing it with a mid-level representation driven by DensePose keypoints and face landmarks. To achieve motion, we interpolate the keypoints and landmarks between the end frames around the cut. We then use an image translation network from the keypoints and source frames, to synthesize pixels. Because keypoints can contain errors, we propose a cross-modal attention scheme to select and pick the most appropriate source amongst multiple options for each key point. By leveraging this mid-level representation, our method can achieve stronger results than a strong video interpolation baseline. We demonstrate our method on various jump cuts in the talking head videos, such as cutting filler words, pauses, and even random cuts. Our experiments show that we can achieve seamless transitions, even in the challenging cases where the talking head rotates or moves drastically in the jump cut.
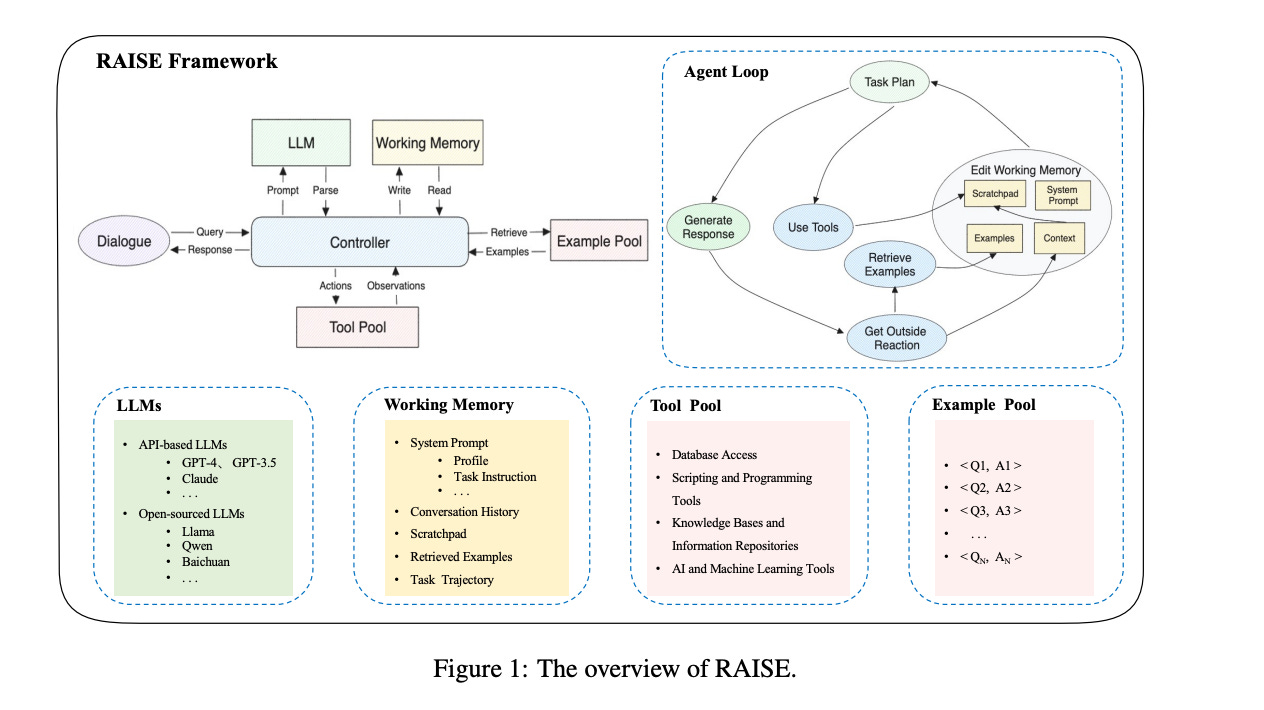
3.From LLM to Conversational Agent: A Memory Enhanced Architecture with Fine-Tuning of Large Language Models ( paper )
This paper introduces RAISE (Reasoning and Acting through Scratchpad and Examples), an advanced architecture enhancing the integration of Large Language Models (LLMs) like GPT-4 into conversational agents. RAISE, an enhancement of the ReAct framework, incorporates a dual-component memory system, mirroring human short-term and long-term memory, to maintain context and continuity in conversations. It entails a comprehensive agent construction scenario, including phases like Conversation Selection, Scene Extraction, CoT Completion, and Scene Augmentation, leading to the LLMs Training phase. This approach appears to enhance agent controllability and adaptability in complex, multi-turn dialogues. Our preliminary evaluations in a real estate sales context suggest that RAISE has some advantages over traditional agents, indicating its potential for broader applications. This work contributes to the AI field by providing a robust framework for developing more context-aware and versatile conversational agents.
4.A Mechanistic Understanding of Alignment Algorithms: A Case Study on DPO and Toxicity( paper )
5.Narrowing the Knowledge Evaluation Gap: Open-Domain Question Answering with Multi-Granularity Answers( paper )
AI News
1.Top 15 AI Voice Generators of 2024 ( link )
2.Merge Large Language Models with mergekit ( link )
3.Poor facsimile: The problem in chatbot conversations with historical figures ( link )
AI Repos
1.gateway:A Blazing Fast AI Gateway. Route to 100+ LLMs with 1 fast & friendly API.( repo )
2.copilot-gpt4-service:Convert Github Copilot to ChatGPT, free to use the GPT-4 model ( repo )
3.chatbot-ui:The open-source AI chat app for everyone.( repo )