




Synthetic Data Is All You Need
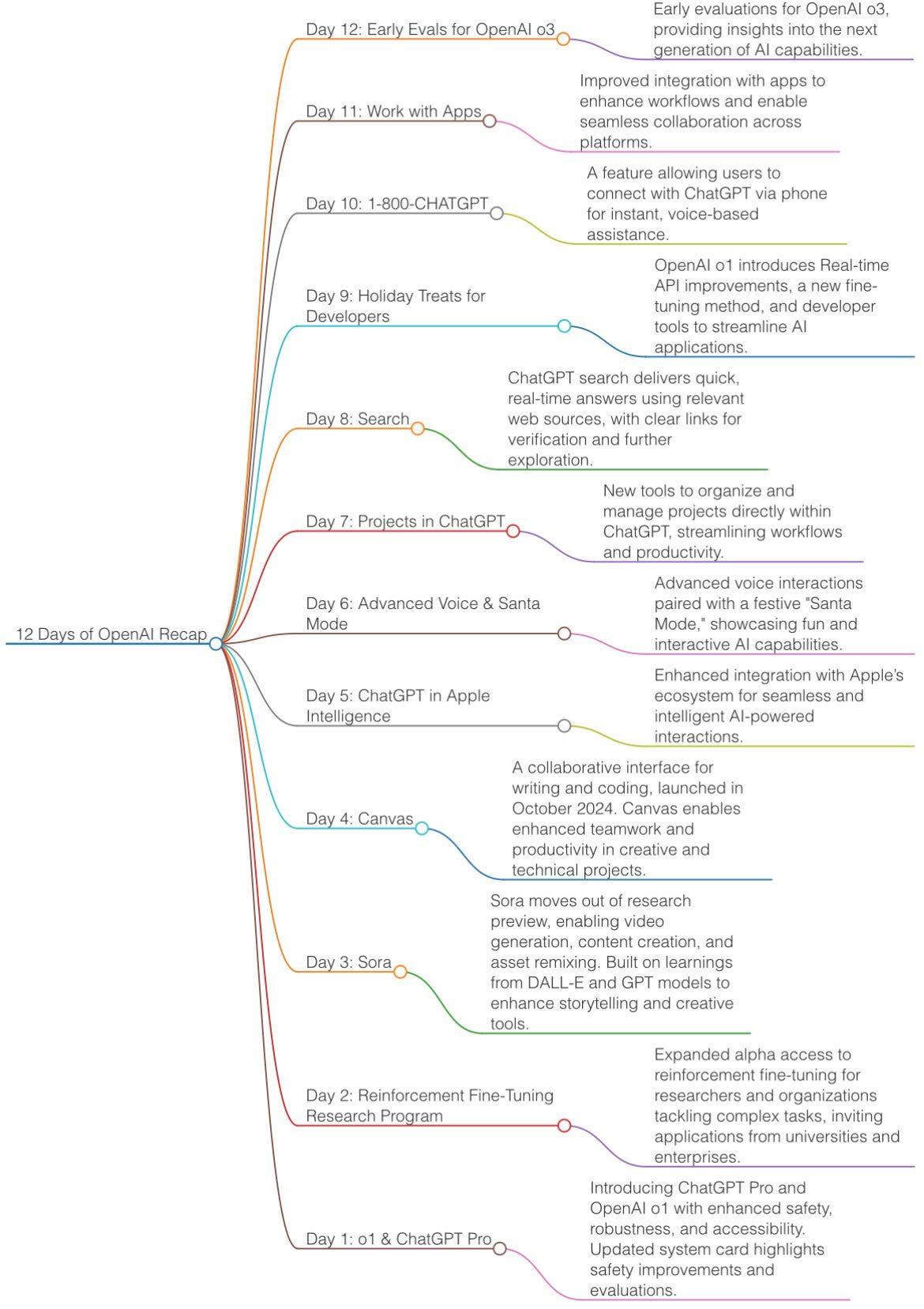
The 12-day OpenAI livestream has finally ended this week, and the image above summarizes the 12-day livestream. It wasn’t until the final day that O3 was released, which sparked some discussion.
As for O3, it’s still a future project. We’ll discuss it further once it can be tested. Of course, I don’t think it has anything to do with AGI, and the AGI-ARC evaluation has many issues.
Today, let’s talk about the Deliberative Alignment released by OpenAI
What is it? It’s a type of training method that teaches LLMs (Large Language Models) to explicitly consider safety guidelines before providing answers. By applying this method, the model can use Chain-of-Thought (CoT) reasoning to review user prompts, identify relevant policy guidelines, and generate safer responses.
The paper provides an example showing how CoT can help the model better understand the user’s intent and respond appropriately, avoiding illegal or unethical activities. For those interested, you can take a look. Here, we’ll mainly focus on the training part.
In summary, it’s a two-stage synthetic data pipeline.
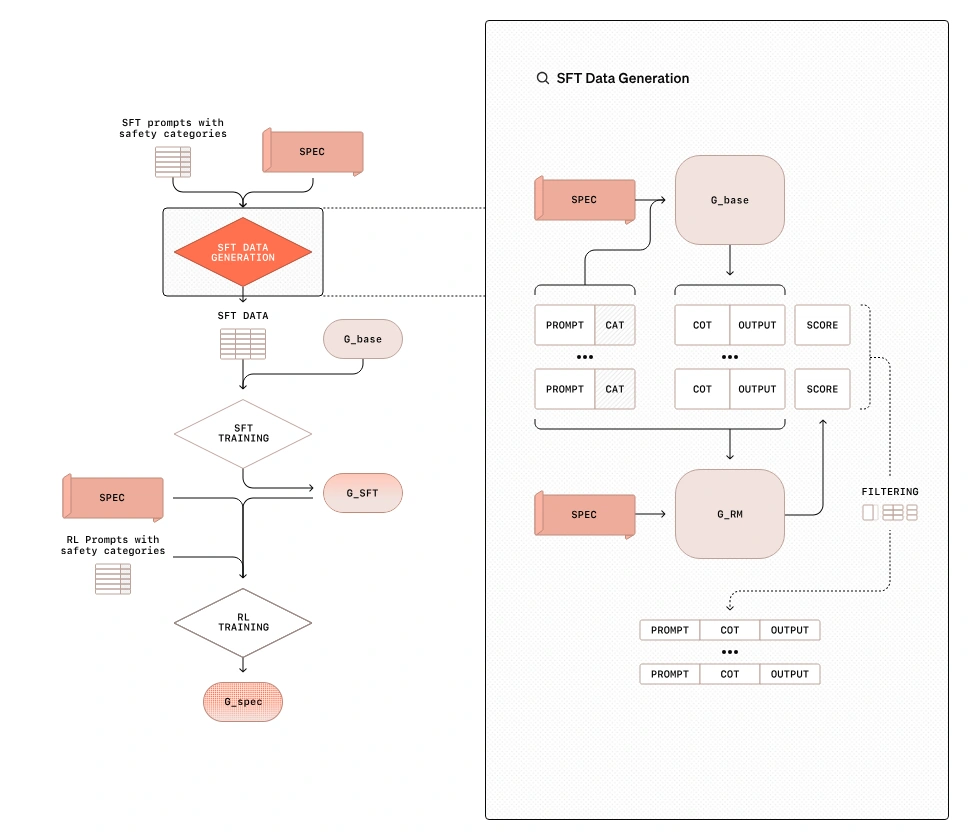
Stage 1: SFT
Prompt + CAT (Classification) + Spec (Safety Guidelines, System Prompt) → Model with CoT (e.g., O1) → CoT-enhanced Output → Train using (Prompt, CoT, Output)
Stage 2: RL
A Judge LLM gives a reward signal based on the spec, and then RL is used to improve the model’s safety capabilities.
Input: (Prompt, Category)
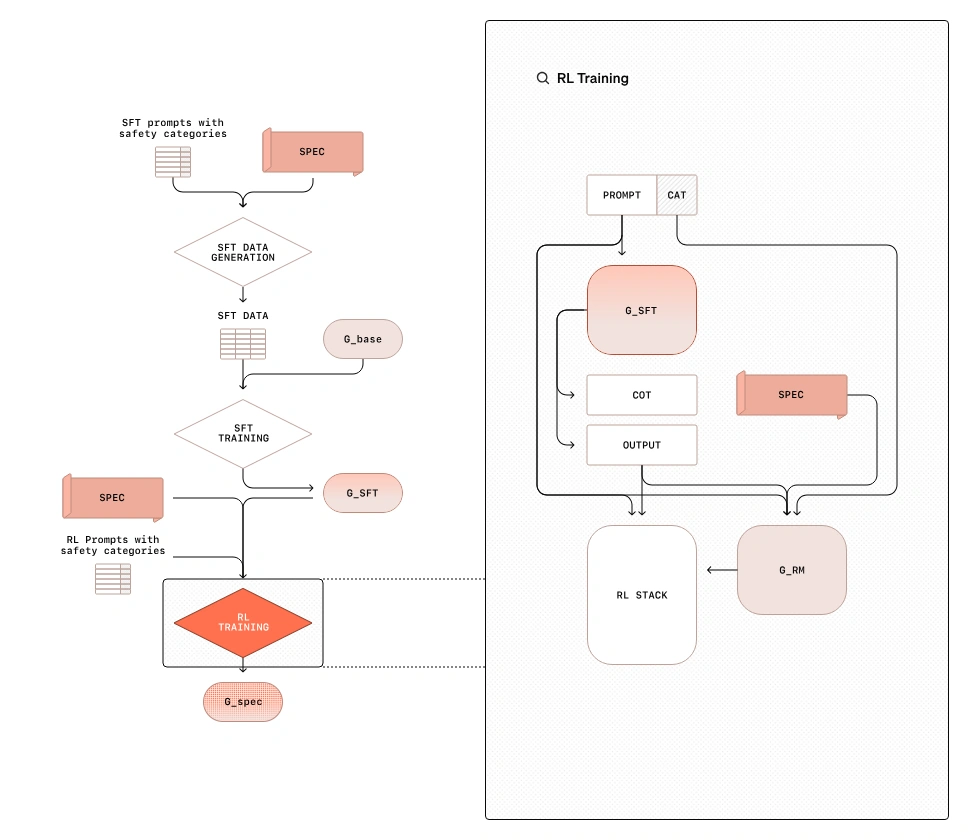
The two stages mainly do not involve human labeling or human intervention. The entire synthetic data pipeline is very smooth and can be applied on a large scale.
Synthetic data really plays a significant role this time.
Top Papers of the week
1.) Thinking in Space: How Multimodal Large Language Models See, Remember, and Recall Spaces (webpage | paper)
A video dataset used to evaluate the spatial reasoning ability of MLLMs.
It provides over 5,000 question-answer pairs, showing that MLLMs have competitive spatial reasoning abilities, but still fall short of human-level performance.
By exploring how models think about space through both language and vision, the study finds that spatial reasoning is a key bottleneck preventing MLLMs from achieving higher benchmark performance.
By explicitly generating cognitive maps during question answering, the spatial distance capabilities of MLLMs were enhanced.
2.) Alignment Faking in LLMs (webpage | paper)
An experiment by Anthropic that demonstrates how the Claude model can perform "alignment faking," meaning it can follow harmful requests while avoiding retraining and retaining its original safety preferences. This raises concerns about the reliability of AI safety training methods.
3.) Qwen-2.5 Technical Report( paper )
Alibaba released Qwen-2.5, a new series of LLMs trained on 18T tokens.
It provides open-weight models and proprietary MoE variants, with performance on par with Llama-3 and GPT-4.
4.) TheAgentCompany: Benchmarking LLM Agents on Consequential Real World Tasks (paper)
A benchmark used to evaluate AI agents' performance on real-world professional tasks, including software engineering, project management, finance, and human resources.
Multiple LLMs were tested, including API models and open-source models. The results showed the limitations of current AI agents.
The best-performing model, Claude-3.5-Sonnet, had a success rate of only 24% when completing tasks, but this increased to 34.4% when considering partial progress.
5.) How to Synthesize Text Data without Model Collapse? (paper)
A study exploring the impact of synthetic data in language model training and how to synthesize data without causing model collapse.
Experiments found a negative correlation between the proportion of synthetic data and model performance.
A token-editing method based on human-generated data was proposed to create semi-synthetic data.
Theoretical proofs show that token-level editing can prevent model collapse, as test errors are constrained by a finite upper bound.
Extensive experiments validated the theoretical proofs, demonstrating that token-level editing improves data quality and enhances model performance.
6.) Smarter, Better, Faster, Longer: A Modern Bidirectional Encoder for Fast, Memory Efficient, and Long Context Fine-tuning and Inference (paper)
ModernBERT is a modern encoder designed for fast, memory-efficient, and long-context fine-tuning, excelling in various evaluation tasks.
Trained on 2 trillion tokens with a sequence length of 8192, it performs well on multiple benchmarks, especially in code retrieval tasks.
It is the fastest and most memory-efficient encoder, suitable for inference on common GPUs.
7.) PAE (Proposer-Agent-Evaluator) (paper)
A learning system that enables AI agents to autonomously discover and practice skills through web navigation, using reinforcement learning and context-aware task proposals, achieving state-of-the-art performance on real-world benchmarks.
8.) AutoFeedback (paper)
A two-agent AI system that generates more accurate and educational feedback, significantly reducing common errors.
It achieves state-of-the-art performance in scientific evaluations through reinforcement learning and context-aware task proposals.
9.) GUI Agents: A Survey (paper)
A comprehensive survey covering the benchmarking, evaluation metrics, architecture, and training methods of GUI agents.
It proposes a unified framework describing the perception, reasoning, planning, and execution capabilities of GUI agents.
The survey identifies important open challenges and discusses key future directions.
10.) Genesis (webpage | github)
A generative physics engine capable of creating 4D dynamic worlds, providing a physical simulation platform for general-purpose robotics and AI applications.
It implements a unified simulation framework from scratch, integrating cutting-edge physics solvers.
Comment: The project has reached 18k stars in a few days, but many features have not been released yet, and the testing results are not ideal.
AIGC News of the week
1.) Jovie/Midjourney
2.) Enhance-A-Video: Better Generated Video for Free
3.) gitingest:Turn any Git repository into a prompt-friendly text ingest for LLMs