Top Papers of the week(September 23 - September 29)
1.) Llama 3.2: Revolutionizing edge AI and vision with open, customizable models ( webpage | model )
The two largest models of the Llama 3.2 collection, 11B and 90B, support image reasoning use cases, such as document-level understanding including charts and graphs, captioning of images, and visual grounding tasks such as directionally pinpointing objects in images based on natural language descriptions. For example, a person could ask a question about which month in the previous year their small business had the best sales, and Llama 3.2 can then reason based on an available graph and quickly provide the answer. In another example, the model could reason with a map and help answer questions such as when a hike might become steeper or the distance of a particular trail marked on the map. The 11B and 90B models can also bridge the gap between vision and language by extracting details from an image, understanding the scene, and then crafting a sentence or two that could be used as an image caption to help tell the story.
The lightweight 1B and 3B models are highly capable with multilingual text generation and tool calling abilities. These models empower developers to build personalized, on-device agentic applications with strong privacy where data never leaves the device. For example, such an application could help summarize the last 10 messages received, extract action items, and leverage tool calling to directly send calendar invites for follow-up meetings.

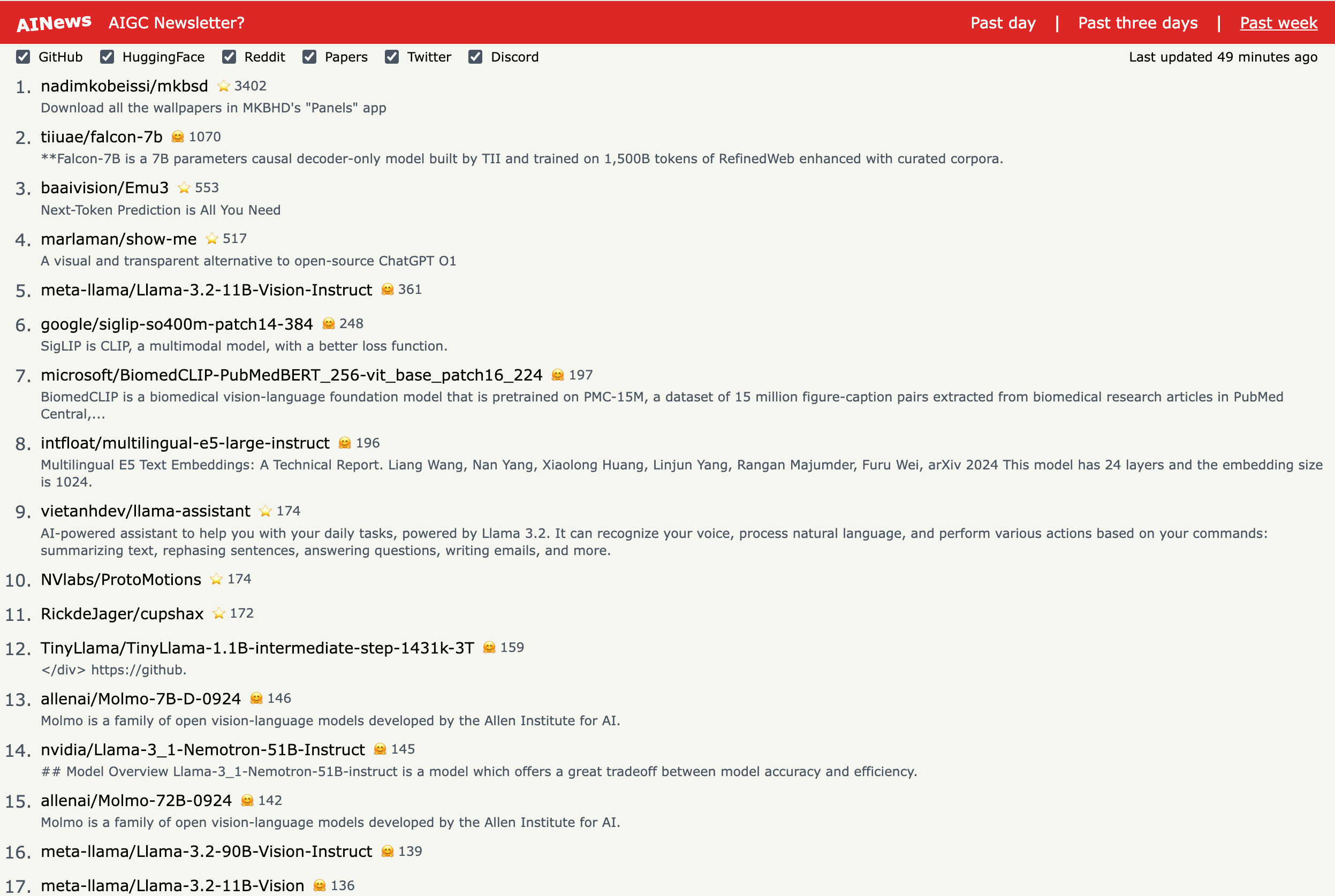
2.) LLMs Still Can't Plan; Can LRMs? A Preliminary Evaluation of OpenAI's o1 on PlanBench ( paper )
The ability to plan a course of action that achieves a desired state of affairs has long been considered a core competence of intelligent agents and has been an integral part of AI research since its inception. With the advent of large language models (LLMs), there has been considerable interest in the question of whether or not they possess such planning abilities. PlanBench, an extensible benchmark we developed in 2022, soon after the release of GPT3, has remained an important tool for evaluating the planning abilities of LLMs. Despite the slew of new private and open source LLMs since GPT3, progress on this benchmark has been surprisingly slow. OpenAI claims that their recent o1 (Strawberry) model has been specifically constructed and trained to escape the normal limitations of autoregressive LLMs--making it a new kind of model: a Large Reasoning Model (LRM). Using this development as a catalyst, this paper takes a comprehensive look at how well current LLMs and new LRMs do on PlanBench. As we shall see, while o1's performance is a quantum improvement on the benchmark, outpacing the competition, it is still far from saturating it. This improvement also brings to the fore questions about accuracy, efficiency, and guarantees which must be considered before deploying such systems.
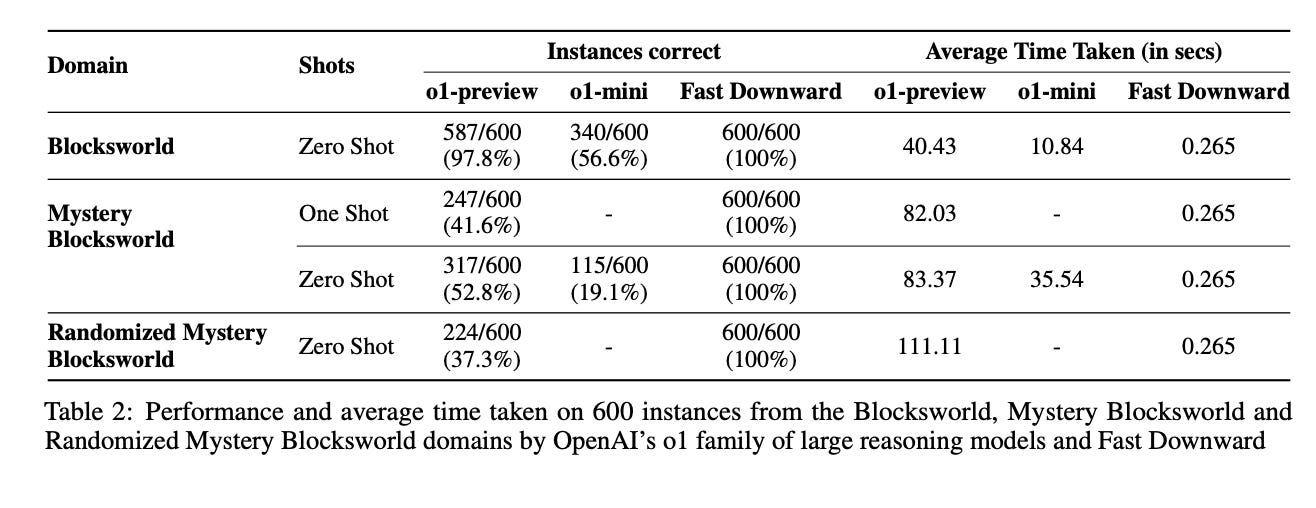
3.) Larger and more instructable language models become less reliable ( paper )
The prevailing methods to make large language models more powerful and amenable have been based on continuous scaling up (that is, increasing their size, data volume and computational resources) and bespoke shaping up (including post-filtering, fine tuning or use of human feedback). However, larger and more instructable large language models may have become less reliable. By studying the relationship between difficulty concordance, task avoidance and prompting stability of several language model families, here we show that easy instances for human participants are also easy for the models, but scaled-up, shaped-up models do not secure areas of low difficulty in which either the model does not err or human supervision can spot the errors. We also find that early models often avoid user questions but scaled-up, shaped-up models tend to give an apparently sensible yet wrong answer much more often, including errors on difficult questions that human supervisors frequently overlook. Moreover, we observe that stability to different natural phrasings of the same question is improved by scaling-up and shaping-up interventions, but pockets of variability persist across difficulty levels. These findings highlight the need for a fundamental shift in the design and development of general-purpose artificial intelligence, particularly in high-stakes areas for which a predictable distribution of errors is paramount.
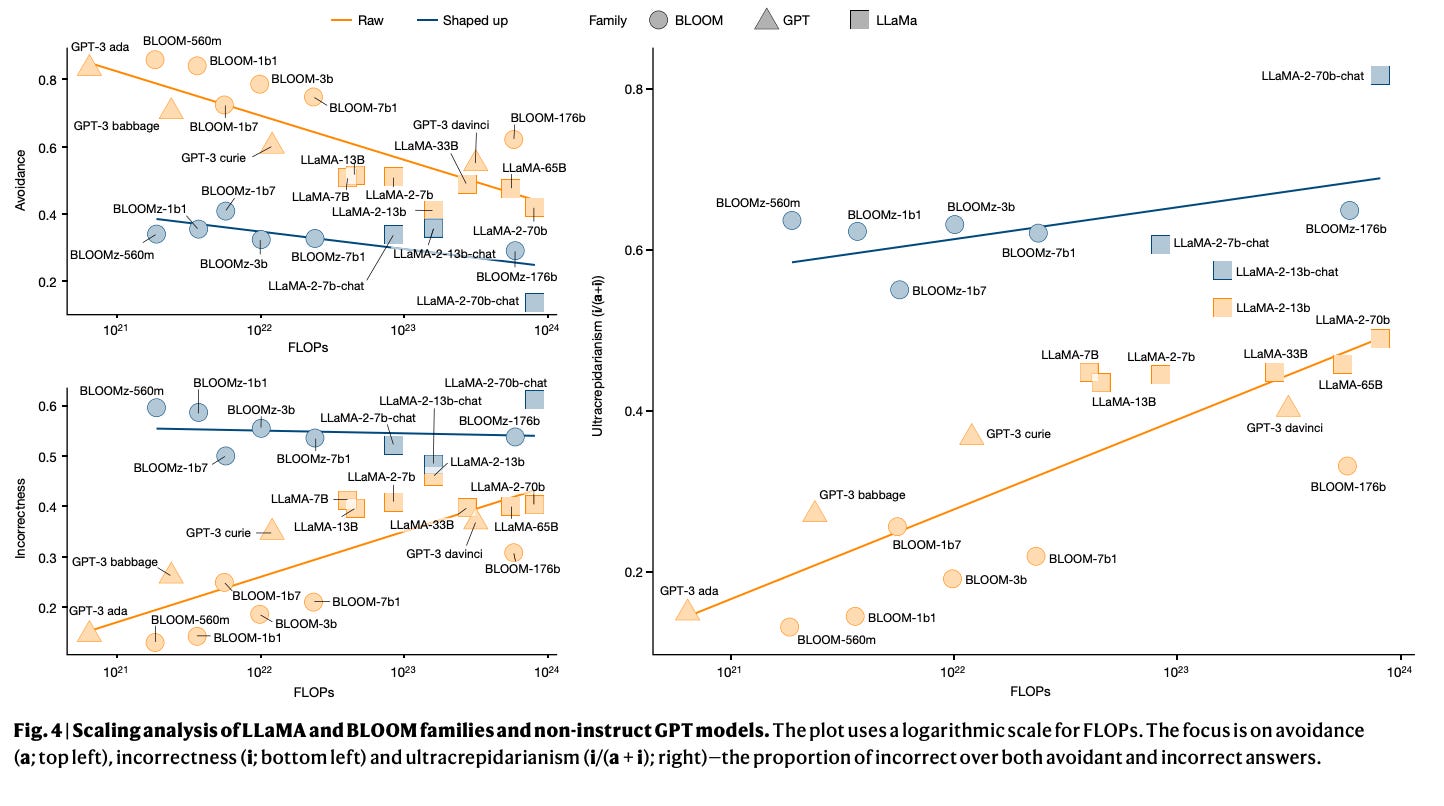
4.) A Preliminary Study of o1 in Medicine: Are We Closer to an AI Doctor? ( webpage | paper)
Large language models (LLMs) have exhibited remarkable capabilities across various domains and tasks, pushing the boundaries of our knowledge in learning and cognition. The latest model, OpenAI's o1, stands out as the first LLM with an internalized chain-of-thought technique using reinforcement learning strategies. While it has demonstrated surprisingly strong capabilities on various general language tasks, its performance in specialized fields such as medicine remains unknown. To this end, this report provides a comprehensive exploration of o1 on different medical scenarios, examining 3 key aspects: understanding, reasoning, and multilinguality. Specifically, our evaluation encompasses 6 tasks using data from 37 medical datasets, including two newly constructed and more challenging question-answering (QA) tasks based on professional medical quizzes from the New England Journal of Medicine (NEJM) and The Lancet. These datasets offer greater clinical relevance compared to standard medical QA benchmarks such as MedQA, translating more effectively into real-world clinical utility. Our analysis of o1 suggests that the enhanced reasoning ability of LLMs may (significantly) benefit their capability to understand various medical instructions and reason through complex clinical scenarios. Notably, o1 surpasses the previous GPT-4 in accuracy by an average of 6.2% and 6.6% across 19 datasets and two newly created complex QA scenarios. But meanwhile, we identify several weaknesses in both the model capability and the existing evaluation protocols, including hallucination, inconsistent multilingual ability, and discrepant metrics for evaluation.
5.) PhysGen: Rigid-Body Physics-Grounded Image-to-Video Generation ( webpage | paper )
We present PhysGen, a novel image-to-video generation method that converts a single image and an input condition (e.g., force and torque applied to an object in the image) to produce a realistic, physically plausible, and temporally consistent video. Our key insight is to integrate model-based physical simulation with a data-driven video generation process, enabling plausible image-space dynamics. At the heart of our system are three core components: (i) an image understanding module that effectively captures the geometry, materials, and physical parameters of the image; (ii) an image-space dynamics simulation model that utilizes rigid-body physics and inferred parameters to simulate realistic behaviors; and (iii) an image-based rendering and refinement module that leverages generative video diffusion to produce realistic video footage featuring the simulated motion. The resulting videos are realistic in both physics and appearance and are even precisely controllable, showcasing superior results over existing data-driven image-to-video generation works through quantitative comparison and comprehensive user study. PhysGen's resulting videos can be used for various downstream applications, such as turning an image into a realistic animation or allowing users to interact with the image and create various dynamics.
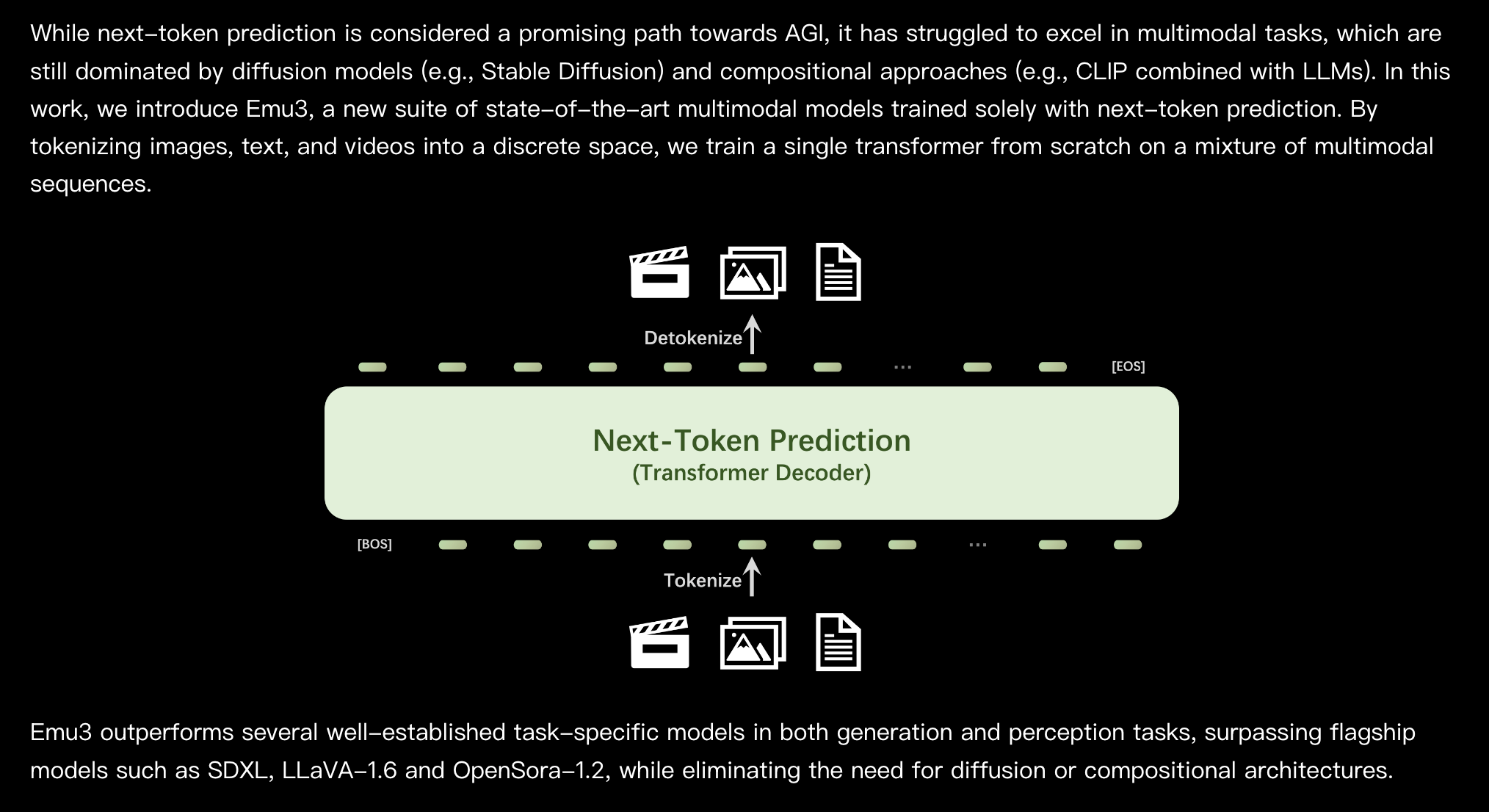
6.) Emu3: Next-Token Prediction is All You Need ( webpage | paper | code )
While next-token prediction is considered a promising path towards artificial general intelligence, it has struggled to excel in multimodal tasks, which are still dominated by diffusion models (e.g., Stable Diffusion) and compositional approaches (e.g., CLIP combined with LLMs). In this paper, we introduce Emu3, a new suite of state-of-the-art multimodal models trained solely with next-token prediction. By tokenizing images, text, and videos into a discrete space, we train a single transformer from scratch on a mixture of multimodal sequences. Emu3 outperforms several well-established task-specific models in both generation and perception tasks, surpassing flagship models such as SDXL and LLaVA-1.6, while eliminating the need for diffusion or compositional architectures. Emu3 is also capable of generating high-fidelity video via predicting the next token in a video sequence. We simplify complex multimodal model designs by converging on a singular focus: tokens, unlocking great potential for scaling both during training and inference. Our results demonstrate that next-token prediction is a promising path towards building general multimodal intelligence beyond language. We open-source key techniques and models to support further research in this direction.
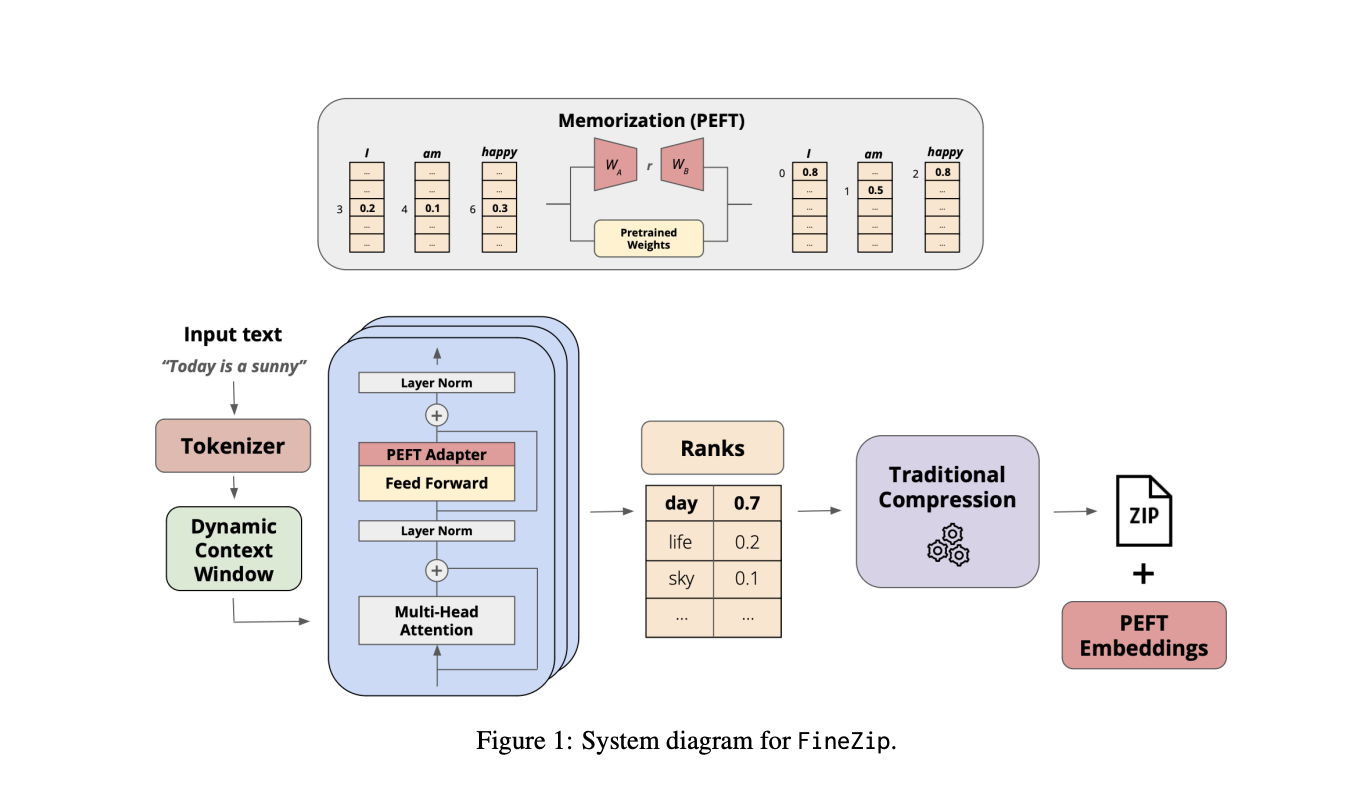
7.) FineZip : Pushing the Limits of Large Language Models for Practical Lossless Text Compression ( paper )
While the language modeling objective has been shown to be deeply connected with compression, it is surprising that modern LLMs are not employed in practical text compression systems. In this paper, we provide an in-depth analysis of neural network and transformer-based compression techniques to answer this question. We compare traditional text compression systems with neural network and LLM-based text compression methods. Although LLM-based systems significantly outperform conventional compression methods, they are highly impractical. Specifically, LLMZip, a recent text compression system using Llama3-8B requires 9.5 days to compress just 10 MB of text, although with huge improvements in compression ratios. To overcome this, we present FineZip - a novel LLM-based text compression system that combines ideas of online memorization and dynamic context to reduce the compression time immensely. FineZip can compress the above corpus in approximately 4 hours compared to 9.5 days, a 54 times improvement over LLMZip and comparable performance. FineZip outperforms traditional algorithmic compression methods with a large margin, improving compression ratios by approximately 50\%. With this work, we take the first step towards making lossless text compression with LLMs a reality. While FineZip presents a significant step in that direction, LLMs are still not a viable solution for large-scale text compression. We hope our work paves the way for future research and innovation to solve this problem.
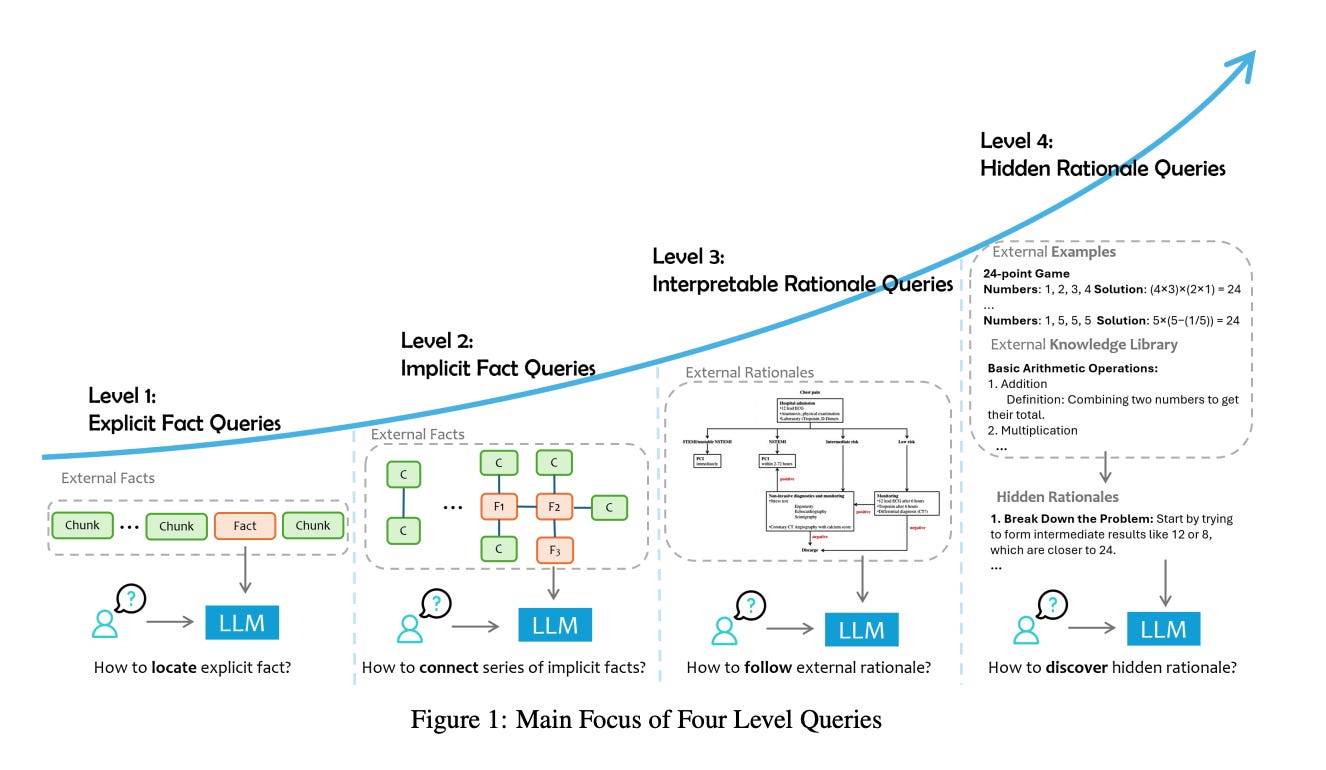
8.) Retrieval Augmented Generation (RAG) and Beyond: A Comprehensive Survey on How to Make your LLMs use External Data More Wisely ( paper )
Large language models (LLMs) augmented with external data have demonstrated remarkable capabilities in completing real-world tasks. Techniques for integrating external data into LLMs, such as Retrieval-Augmented Generation (RAG) and fine-tuning, are gaining increasing attention and widespread application. Nonetheless, the effective deployment of data-augmented LLMs across various specialized fields presents substantial challenges. These challenges encompass a wide range of issues, from retrieving relevant data and accurately interpreting user intent to fully harnessing the reasoning capabilities of LLMs for complex tasks. We believe that there is no one-size-fits-all solution for data-augmented LLM applications. In practice, underperformance often arises from a failure to correctly identify the core focus of a task or because the task inherently requires a blend of multiple capabilities that must be disentangled for better resolution. In this survey, we propose a RAG task categorization method, classifying user queries into four levels based on the type of external data required and primary focus of the task: explicit fact queries, implicit fact queries, interpretable rationale queries, and hidden rationale queries. We define these levels of queries, provide relevant datasets, and summarize the key challenges and most effective techniques for addressing these challenges. Finally, we discuss three main forms of integrating external data into LLMs: context, small model, and fine-tuning, highlighting their respective strengths, limitations, and the types of problems they are suited to solve. This work aims to help readers thoroughly understand and decompose the data requirements and key bottlenecks in building LLM applications, offering solutions to the different challenges and serving as a guide to systematically developing such applications.
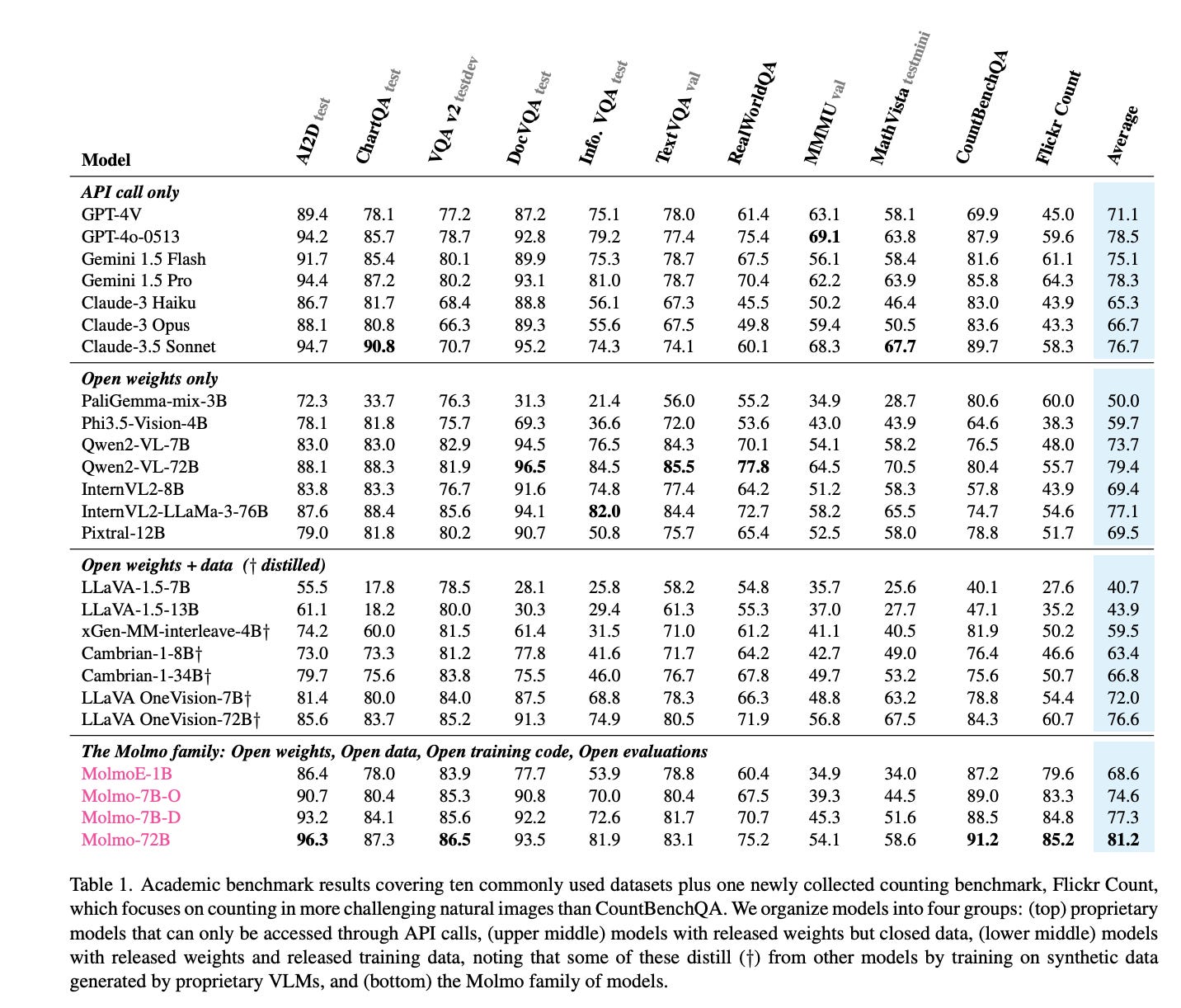
9.) Molmo and PixMo: Open Weights and Open Data for State-of-the-Art Multimodal Models ( webpage | paper )
Today's most advanced multimodal models remain proprietary. The strongest open-weight models rely heavily on synthetic data from proprietary VLMs to achieve good performance, effectively distilling these closed models into open ones. As a result, the community is still missing foundational knowledge about how to build performant VLMs from scratch. We present Molmo, a new family of VLMs that are state-of-the-art in their class of openness. Our key innovation is a novel, highly detailed image caption dataset collected entirely from human annotators using speech-based descriptions. To enable a wide array of user interactions, we also introduce a diverse dataset mixture for fine-tuning that includes in-the-wild Q&A and innovative 2D pointing data. The success of our approach relies on careful choices for the model architecture details, a well-tuned training pipeline, and, most critically, the quality of our newly collected datasets, all of which will be released. The best-in-class 72B model within the Molmo family not only outperforms others in the class of open weight and data models but also compares favorably against proprietary systems like GPT-4o, Claude 3.5, and Gemini 1.5 on both academic benchmarks and human evaluation.
10.) Gen2Act: Human Video Generation in Novel Scenarios enables Generalizable Robot Manipulation ( webpage | paper )
How can robot manipulation policies generalize to novel tasks involving unseen object types and new motions? In this paper, we provide a solution in terms of predicting motion information from web data through human video generation and conditioning a robot policy on the generated video. Instead of attempting to scale robot data collection which is expensive, we show how we can leverage video generation models trained on easily available web data, for enabling generalization. Our approach Gen2Act casts language-conditioned manipulation as zero-shot human video generation followed by execution with a single policy conditioned on the generated video. To train the policy, we use an order of magnitude less robot interaction data compared to what the video prediction model was trained on. Gen2Act doesn't require fine-tuning the video model at all and we directly use a pre-trained model for generating human videos. Our results on diverse real-world scenarios show how Gen2Act enables manipulating unseen object types and performing novel motions for tasks not present in the robot data.
AIGC News of the week(September 23 - September 29)
1.) Show-Me: A Visual and Transparent Reasoning Agent ( repo )
2.) ProtoMotions: Physics-based Character Animation ( repo )

3.) GemFilter: Discovering the Gems in Early Layers: Accelerating Long-Context LLMs with 1000x Input Token Reduction ( repo )
4.) llama-assistant:Your Local AI Assistant with Llama Models ( repo )
5.) nvidia/Llama-3_1-Nemotron-51B-Instruct ( link )
more AIGC News: AINews