Top Papers of the week(September 16 - September 22)
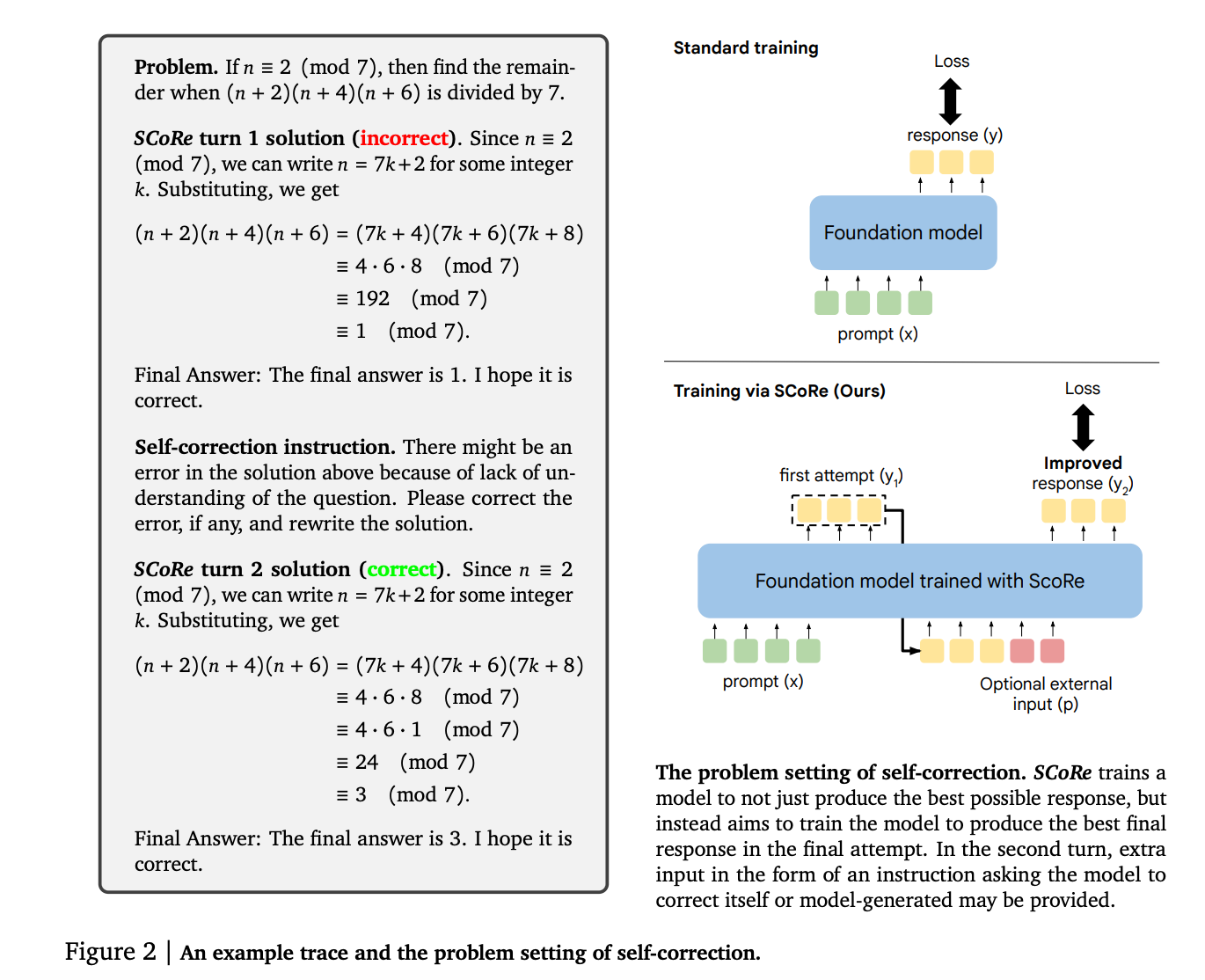
1.) Training Language Models to Self-Correct via Reinforcement Learning ( paper )
Self-correction is a highly desirable capability of large language models (LLMs), yet it has consistently been found to be largely ineffective in modern LLMs. Existing approaches for training self-correction either require multiple models or rely on a more capable model or other forms of supervision. To this end, we develop a multi-turn online reinforcement learning (RL) approach, SCoRe, that significantly improves an LLM's self-correction ability using entirely self-generated data. To build SCoRe, we first show that variants of supervised fine-tuning (SFT) on offline model-generated correction traces are insufficient for instilling self-correction behavior. In particular, we observe that training via SFT either suffers from a distribution mismatch between the training data and the model's own responses or implicitly prefers only a certain mode of correction behavior that is often not effective at test time. SCoRe addresses these challenges by training under the model's own distribution of self-generated correction traces and using appropriate regularization to steer the learning process into learning a self-correction strategy that is effective at test time as opposed to simply fitting high-reward responses for a given prompt. This regularization prescribes running a first phase of RL on a base model to generate a policy initialization that is less susceptible to collapse and then using a reward bonus to amplify self-correction during training. When applied to Gemini 1.0 Pro and 1.5 Flash models, we find that SCoRe achieves state-of-the-art self-correction performance, improving the base models' self-correction by 15.6% and 9.1% respectively on the MATH and HumanEval benchmarks.
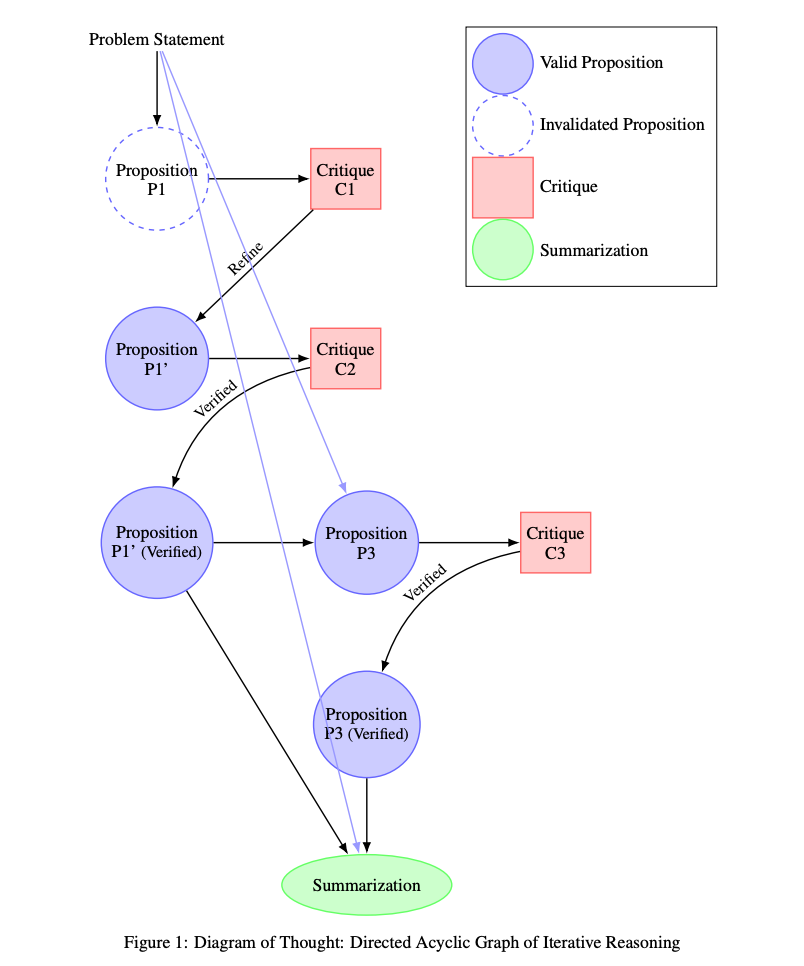
2.) On the Diagram of Thought ( paper | code )
We introduce Diagram of Thought (DoT), a framework that models iterative reasoning in large language models (LLMs) as the construction of a directed acyclic graph (DAG) within a single model. Unlike traditional approaches that represent reasoning as linear chains or trees, DoT organizes propositions, critiques, refinements, and verifications into a cohesive DAG structure, allowing the model to explore complex reasoning pathways while maintaining logical consistency. Each node in the diagram corresponds to a proposition that has been proposed, critiqued, refined, or verified, enabling the LLM to iteratively improve its reasoning through natural language feedback. By leveraging auto-regressive next-token prediction with role-specific tokens, DoT facilitates seamless transitions between proposing ideas and critically evaluating them, providing richer feedback than binary signals. Furthermore, we formalize the DoT framework using Topos Theory, providing a mathematical foundation that ensures logical consistency and soundness in the reasoning process. This approach enhances both the training and inference processes within a single LLM, eliminating the need for multiple models or external control mechanisms. DoT offers a conceptual framework for designing next-generation reasoning-specialized models, emphasizing training efficiency, robust reasoning capabilities, and theoretical grounding.
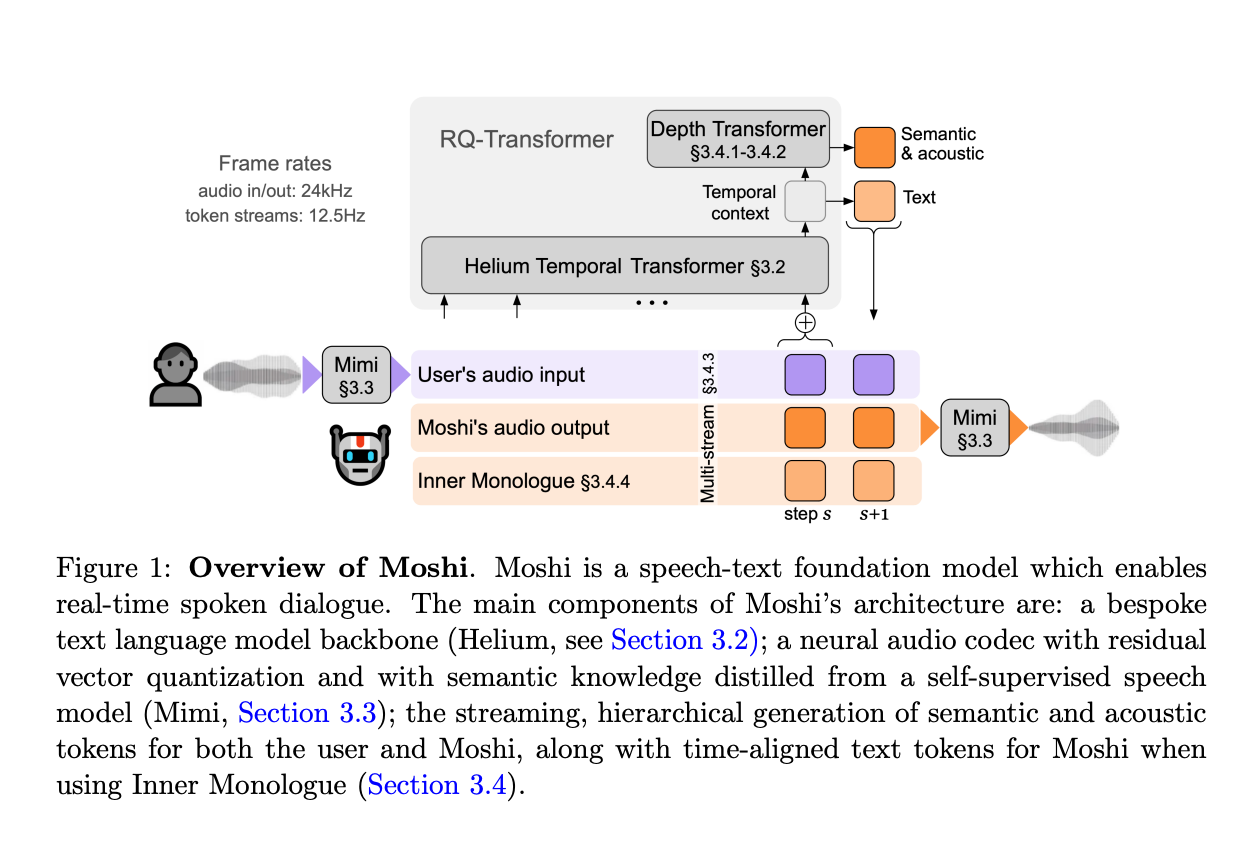
3.) Moshi: a speech-text foundation model for real time dialogue ( paper | code )
We introduce Moshi, a speech-text foundation model and full-duplex spoken dialogue framework. Current systems for spoken dialogue rely on pipelines of independent components, namely voice activity detection, speech recognition, textual dialogue and text-to-speech. Such frameworks cannot emulate the experience of real conversations. First, their complexity induces a latency of several seconds between interactions. Second, text being the intermediate modality for dialogue, non-linguistic information that modifies meaning— such as emotion or non-speech sounds— is lost in the interaction. Finally, they rely on a segmentation into speaker turns, which does not take into account overlapping speech, interruptions and interjections. Moshi solves these independent issues altogether by casting spoken dialogue as speech-to-speech generation. Starting from a text language model backbone, Moshi generates speech as tokens from the residual quantizer of a neural audio codec, while modeling separately its own speech and that of the user into parallel streams. This allows for the removal of explicit speaker turns, and the modeling of arbitrary conversational dynamics. We moreover extend the hierarchical semantic-to-acoustic token generation of previous work to first predict time-aligned text tokens as a prefix to audio tokens. Not only this “Inner Monologue” method significantly improves the linguistic quality of generated speech, but we also illustrate how it can provide streaming speech recognition and text-to-speech. Our resulting model is the first real-time full-duplex spoken large language model, with a theoretical latency of 160ms, 200ms in practice.
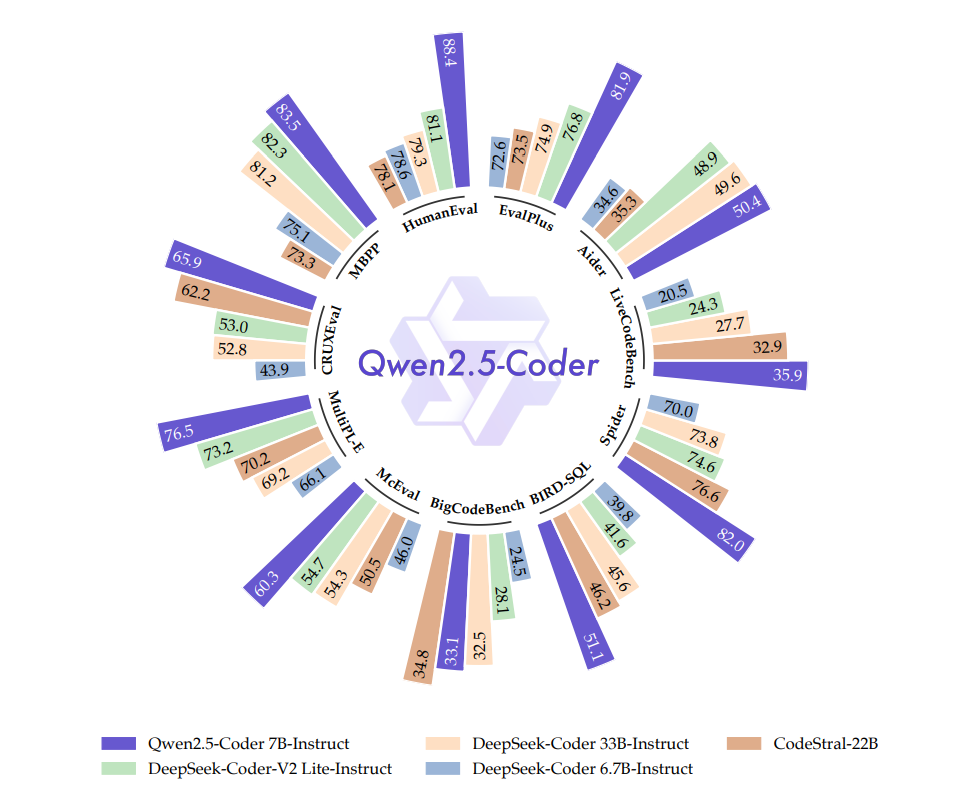
4.) Qwen2.5-Coder Technical Report ( paper | code )
In this report, we introduce the Qwen2.5-Coder series, a significant upgrade from its predecessor, CodeQwen1.5. This series includes two models: Qwen2.5-Coder-1.5B and Qwen2.5-Coder-7B. As a code-specific model, Qwen2.5-Coder is built upon the Qwen2.5 architecture and continues pretrained on a vast corpus of over 5.5 trillion tokens. Through meticulous data cleaning, scalable synthetic data generation, and balanced data mixing, Qwen2.5-Coder demonstrates impressive code generation capabilities while retaining general versatility. The model has been evaluated on a wide range of code-related tasks, achieving state-of-the-art (SOTA) performance across more than 10 benchmarks, including code generation, completion, reasoning, and repair, consistently outperforming larger models of the same model size. We believe that the release of the Qwen2.5-Coder series will not only push the boundaries of research in code intelligence but also, through its permissive licensing, encourage broader adoption by developers in real-world applications.
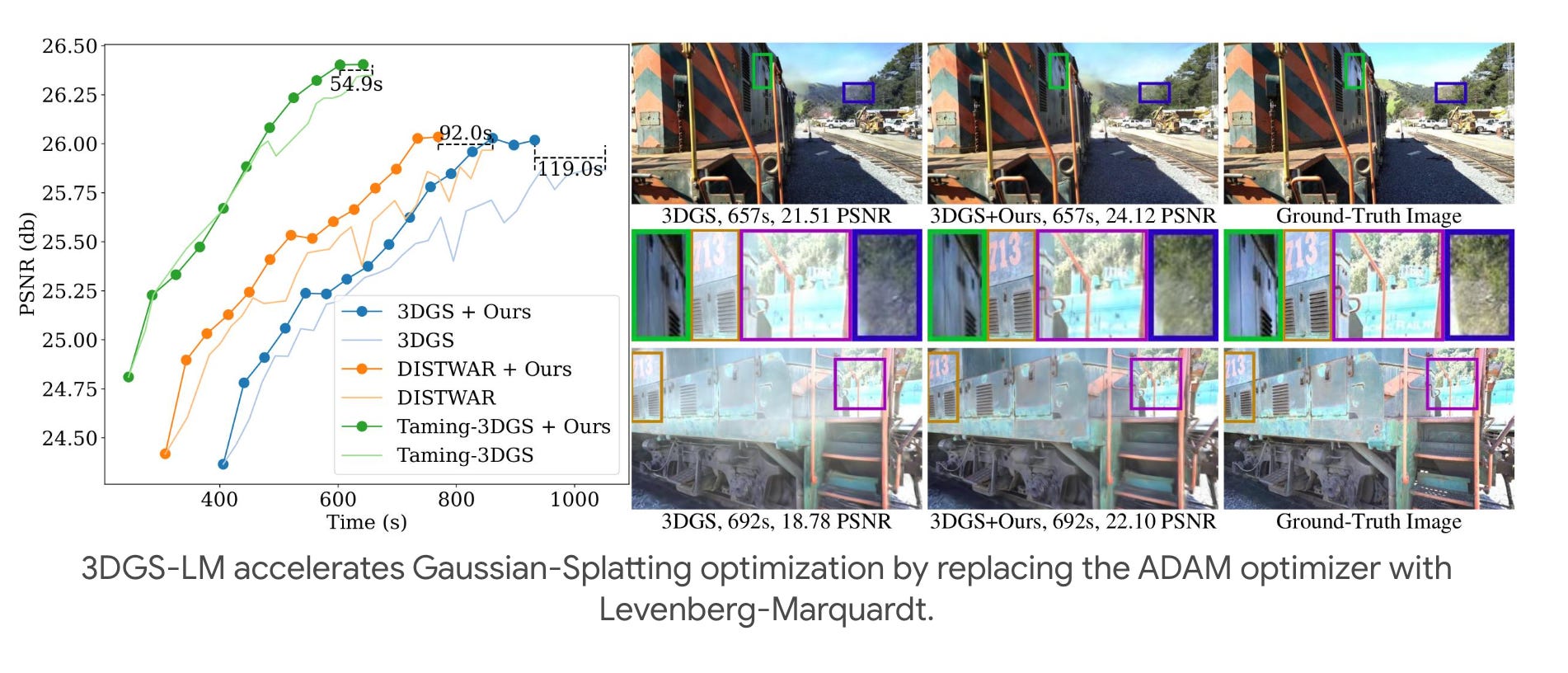
5.) 3DGS-LM: Faster Gaussian-Splatting Optimization with Levenberg-Marquardt ( webpage | paper )
We present 3DGS-LM, a new method that accelerates the reconstruction of 3D Gaussian Splatting (3DGS) by replacing its ADAM optimizer with a tailored Levenberg-Marquardt (LM). Existing methods reduce the optimization time by decreasing the number of Gaussians or by improving the implementation of the differentiable rasterizer. However, they still rely on the ADAM optimizer to fit Gaussian parameters of a scene in thousands of iterations, which can take up to an hour. To this end, we change the optimizer to LM that runs in conjunction with the 3DGS differentiable rasterizer. For efficient GPU parallization, we propose a caching data structure for intermediate gradients that allows us to efficiently calculate Jacobian-vector products in custom CUDA kernels. In every LM iteration, we calculate update directions from multiple image subsets using these kernels and combine them in a weighted mean. Overall, our method is 30% faster than the original 3DGS while obtaining the same reconstruction quality. Our optimization is also agnostic to other methods that acclerate 3DGS, thus enabling even faster speedups compared to vanilla 3DGS.
6.) StoryMaker: Towards Holistic Consistent Characters in Text-to-image Generation ( paper | code )
Tuning-free personalized image generation methods have achieved significant success in maintaining facial consistency, i.e., identities, even with multiple characters. However, the lack of holistic consistency in scenes with multiple characters hampers these methods' ability to create a cohesive narrative. In this paper, we introduce StoryMaker, a personalization solution that preserves not only facial consistency but also clothing, hairstyles, and body consistency, thus facilitating the creation of a story through a series of images. StoryMaker incorporates conditions based on face identities and cropped character images, which include clothing, hairstyles, and bodies. Specifically, we integrate the facial identity information with the cropped character images using the Positional-aware Perceiver Resampler (PPR) to obtain distinct character features. To prevent intermingling of multiple characters and the background, we separately constrain the cross-attention impact regions of different characters and the background using MSE loss with segmentation masks. Additionally, we train the generation network conditioned on poses to promote decoupling from poses. A LoRA is also employed to enhance fidelity and quality. Experiments underscore the effectiveness of our approach. StoryMaker supports numerous applications and is compatible with other societal plug-ins.

7.) 3DTopia-XL: Scaling High-quality 3D Asset Generation via Primitive Diffusion ( webpage | paper | code )
The increasing demand for high-quality 3D assets across various industries necessitates efficient and automated 3D content creation. Despite recent advancements in 3D generative models, existing methods still face challenges with optimization speed, geometric fidelity, and the lack of assets for physically based rendering (PBR). In this paper, we introduce 3DTopia-XL, a scalable native 3D generative model designed to overcome these limitations. 3DTopia-XL leverages a novel primitive-based 3D representation, PrimX, which encodes detailed shape, albedo, and material field into a compact tensorial format, facilitating the modeling of high-resolution geometry with PBR assets. On top of the novel representation, we propose a generative framework based on Diffusion Transformer (DiT), which comprises 1) Primitive Patch Compression, 2) and Latent Primitive Diffusion. 3DTopia-XL learns to generate high-quality 3D assets from textual or visual inputs. We conduct extensive qualitative and quantitative experiments to demonstrate that 3DTopia-XL significantly outperforms existing methods in generating high-quality 3D assets with fine-grained textures and materials, efficiently bridging the quality gap between generative models and real-world applications

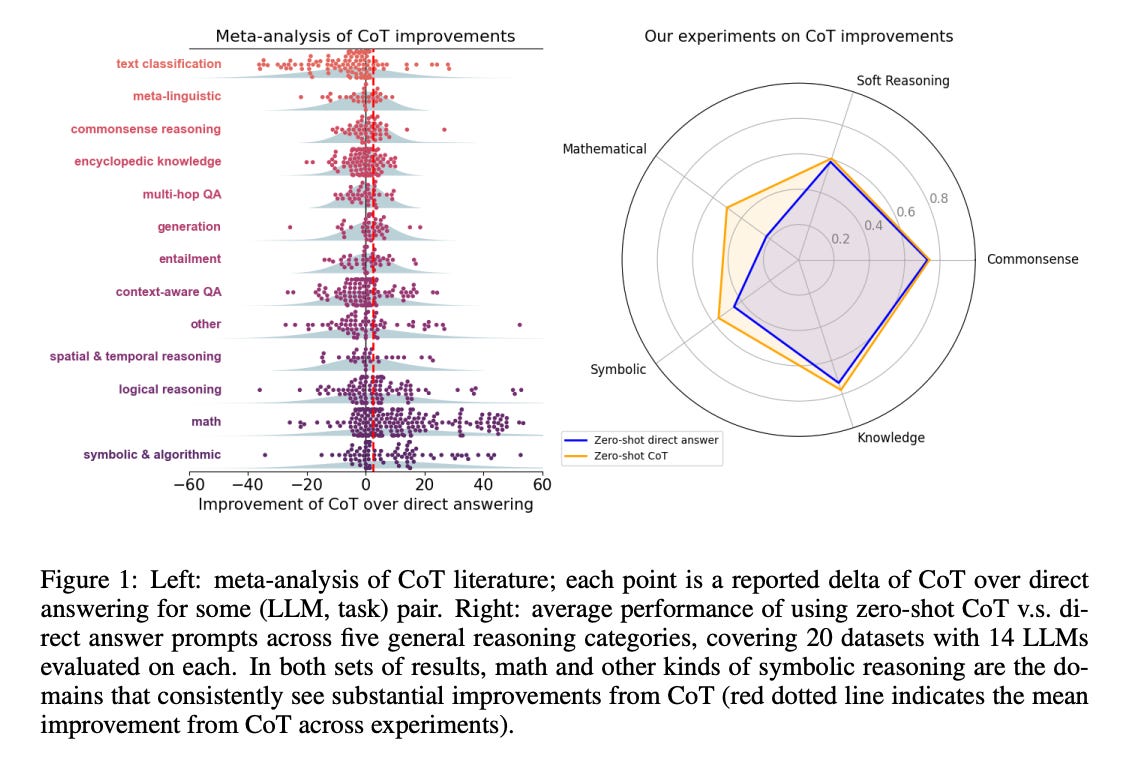
8.) To CoT or not to CoT? Chain-of-thought helps mainly on math and symbolic reasoning ( paper )
Chain-of-thought (CoT) via prompting is the de facto method for eliciting reasoning capabilities from large language models (LLMs). But for what kinds of tasks is this extra ``thinking'' really helpful? To analyze this, we conducted a quantitative meta-analysis covering over 100 papers using CoT and ran our own evaluations of 20 datasets across 14 models. Our results show that CoT gives strong performance benefits primarily on tasks involving math or logic, with much smaller gains on other types of tasks. On MMLU, directly generating the answer without CoT leads to almost identical accuracy as CoT unless the question or model's response contains an equals sign, indicating symbolic operations and reasoning. Following this finding, we analyze the behavior of CoT on these problems by separating planning and execution and comparing against tool-augmented LLMs. Much of CoT's gain comes from improving symbolic execution, but it underperforms relative to using a symbolic solver. Our results indicate that CoT can be applied selectively, maintaining performance while saving inference costs. Furthermore, they suggest a need to move beyond prompt-based CoT to new paradigms that better leverage intermediate computation across the whole range of LLM applications.
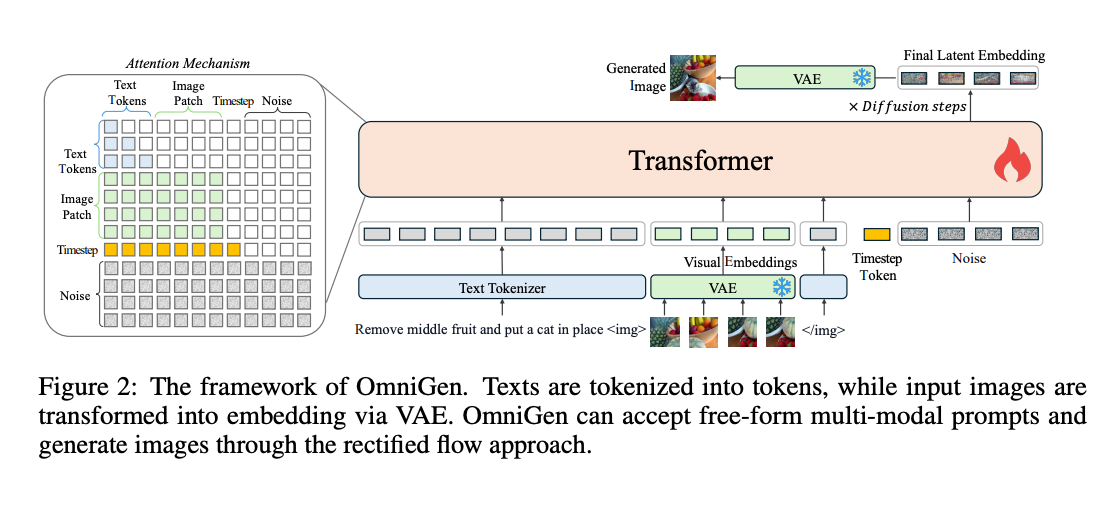
9.) OmniGen: Unified Image Generation ( paper | code )
In this work, we introduce OmniGen, a new diffusion model for unified image generation. Unlike popular diffusion models (e.g., Stable Diffusion), OmniGen no longer requires additional modules such as ControlNet or IP-Adapter to process diverse control conditions. OmniGenis characterized by the following features: 1) Unification: OmniGen not only demonstrates text-to-image generation capabilities but also inherently supports other downstream tasks, such as image editing, subject-driven generation, and visual-conditional generation. Additionally, OmniGen can handle classical computer vision tasks by transforming them into image generation tasks, such as edge detection and human pose recognition. 2) Simplicity: The architecture of OmniGen is highly simplified, eliminating the need for additional text encoders. Moreover, it is more user-friendly compared to existing diffusion models, enabling complex tasks to be accomplished through instructions without the need for extra preprocessing steps (e.g., human pose estimation), thereby significantly simplifying the workflow of image generation. 3) Knowledge Transfer: Through learning in a unified format, OmniGen effectively transfers knowledge across different tasks, manages unseen tasks and domains, and exhibits novel capabilities. We also explore the model's reasoning capabilities and potential applications of chain-of-thought mechanism. This work represents the first attempt at a general-purpose image generation model, and there remain several unresolved issues.
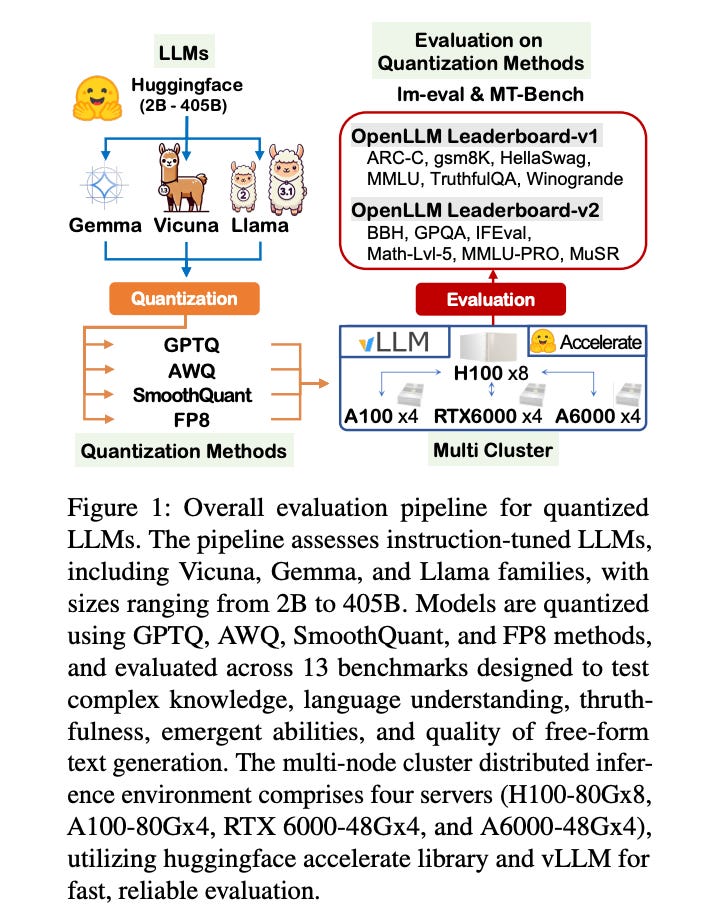
10.) A Comprehensive Evaluation of Quantized Instruction-Tuned Large Language Models: An Experimental Analysis up to 405B ( paper )
Prior research works have evaluated quantized LLMs using limited metrics such as perplexity or a few basic knowledge tasks and old datasets. Additionally, recent large-scale models such as Llama 3.1 with up to 405B have not been thoroughly examined. This paper evaluates the performance of instruction-tuned LLMs across various quantization methods (GPTQ, AWQ, SmoothQuant, and FP8) on models ranging from 7B to 405B. Using 13 benchmarks, we assess performance across six task types: commonsense Q\&A, knowledge and language understanding, instruction following, hallucination detection, mathematics, and dialogue. Our key findings reveal that (1) quantizing a larger LLM to a similar size as a smaller FP16 LLM generally performs better across most benchmarks, except for hallucination detection and instruction following; (2) performance varies significantly with different quantization methods, model size, and bit-width, with weight-only methods often yielding better results in larger models; (3) task difficulty does not significantly impact accuracy degradation due to quantization; and (4) the MT-Bench evaluation method has limited discriminatory power among recent high-performing LLMs.
AIGC News of the week(September 16 - September 22)
1.) o1: Using Groq or OpenAI or Ollama to create o1-like reasoning chains ( repo )
2.) Local Knowledge Graph ( code )

3.) Cogstudio: Advanced Web UI for CogVideo ( repo )

4.) jinaai/jina-embeddings-v3 ( repo )
5.) fishaudio/fish-speech-1.4 ( repo )
more AIGC News: AINews