Top Papers of the week(September 09 - September 15)
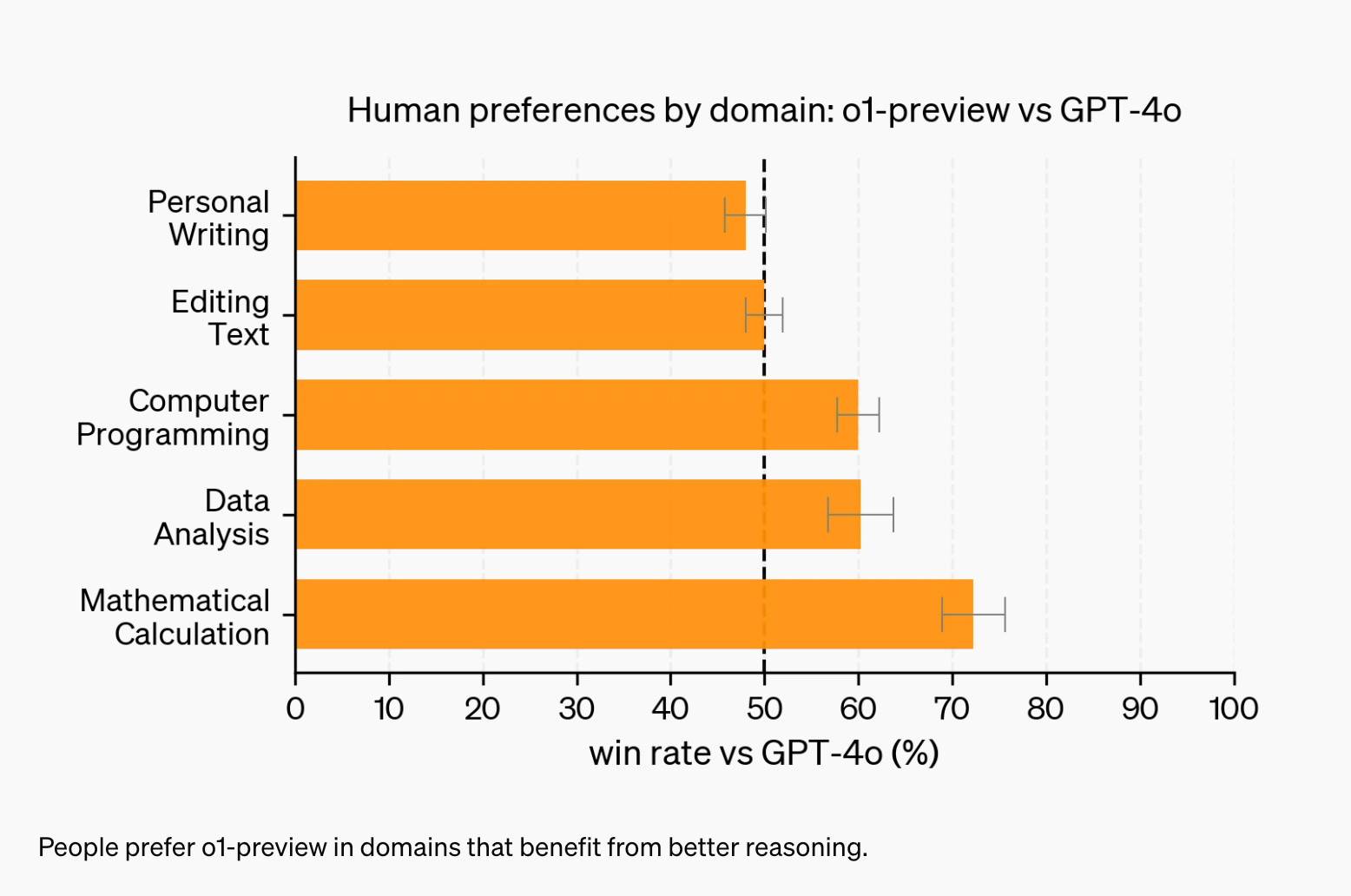
1.) OpenAI o1 ( webpage )
We are introducing OpenAI o1, a new large language model trained with reinforcement learning to perform complex reasoning. o1 thinks before it answers—it can produce a long internal chain of thought before responding to the user.
2.) Can LLMs Generate Novel Research Ideas? A Large-Scale Human Study with 100+ NLP Researchers ( paper )
Recent advancements in large language models (LLMs) have sparked optimism about their potential to accelerate scientific discovery, with a growing number of works proposing research agents that autonomously generate and validate new ideas. Despite this, no evaluations have shown that LLM systems can take the very first step of producing novel, expert-level ideas, let alone perform the entire research process. We address this by establishing an experimental design that evaluates research idea generation while controlling for confounders and performs the first head-to-head comparison between expert NLP researchers and an LLM ideation agent. By recruiting over 100 NLP researchers to write novel ideas and blind reviews of both LLM and human ideas, we obtain the first statistically significant conclusion on current LLM capabilities for research ideation: we find LLM-generated ideas are judged as more novel (p < 0.05) than human expert ideas while being judged slightly weaker on feasibility. Studying our agent baselines closely, we identify open problems in building and evaluating research agents, including failures of LLM self-evaluation and their lack of diversity in generation. Finally, we acknowledge that human judgements of novelty can be difficult, even by experts, and propose an end-to-end study design which recruits researchers to execute these ideas into full projects, enabling us to study whether these novelty and feasibility judgements result in meaningful differences in research outcome.

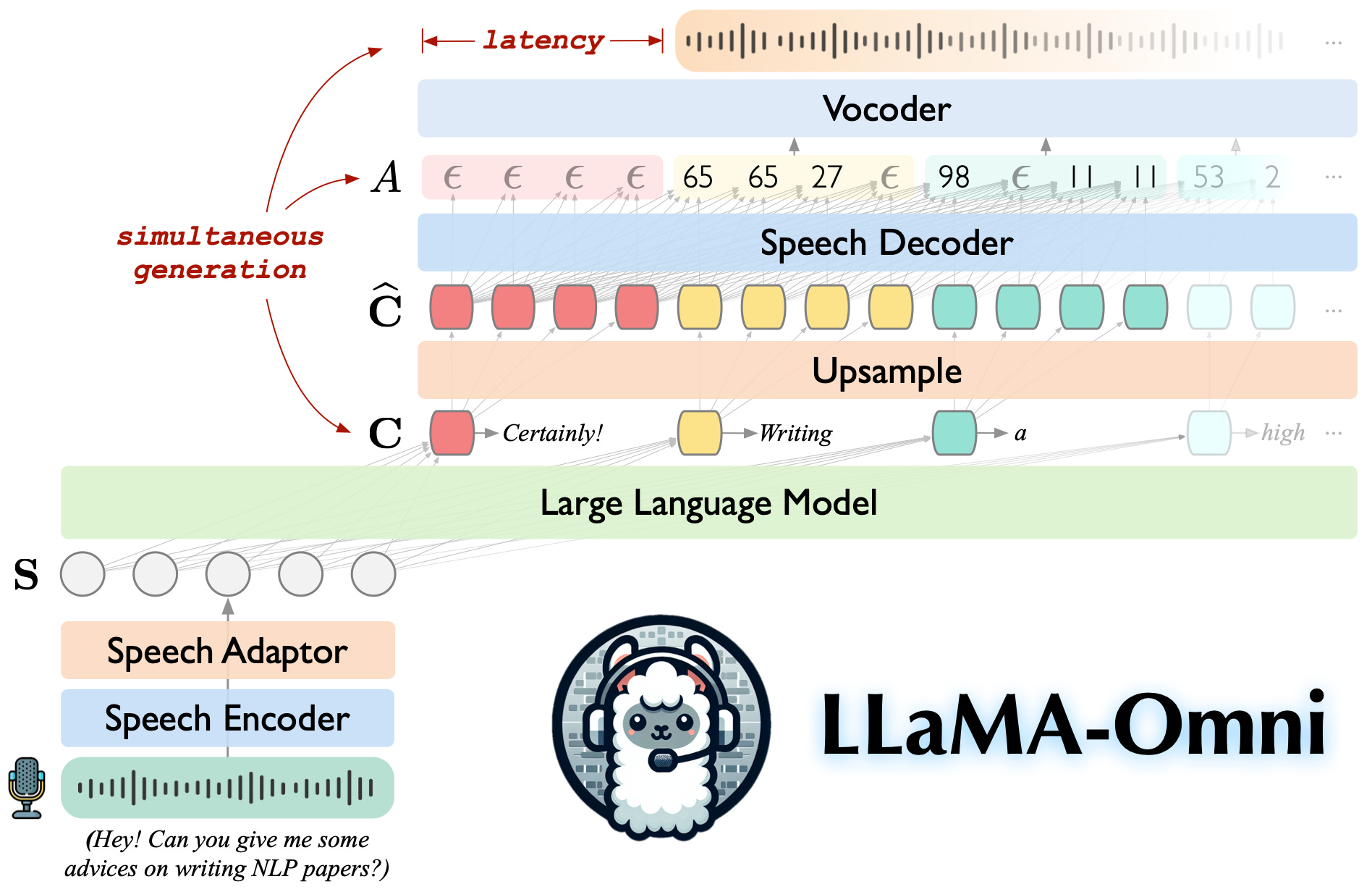
3.) LLaMA-Omni: Seamless Speech Interaction with Large Language Models ( paper | code | model )
Models like GPT-4o enable real-time interaction with large language models (LLMs) through speech, significantly enhancing user experience compared to traditional text-based interaction. However, there is still a lack of exploration on how to build speech interaction models based on open-source LLMs. To address this, we propose LLaMA-Omni, a novel model architecture designed for low-latency and high-quality speech interaction with LLMs. LLaMA-Omni integrates a pretrained speech encoder, a speech adaptor, an LLM, and a streaming speech decoder. It eliminates the need for speech transcription, and can simultaneously generate text and speech responses directly from speech instructions with extremely low latency. We build our model based on the latest Llama-3.1-8B-Instruct model. To align the model with speech interaction scenarios, we construct a dataset named InstructS2S-200K, which includes 200K speech instructions and corresponding speech responses. Experimental results show that compared to previous speech-language models, LLaMA-Omni provides better responses in both content and style, with a response latency as low as 226ms. Additionally, training LLaMA-Omni takes less than 3 days on just 4 GPUs, paving the way for the efficient development of speech-language models in the future.
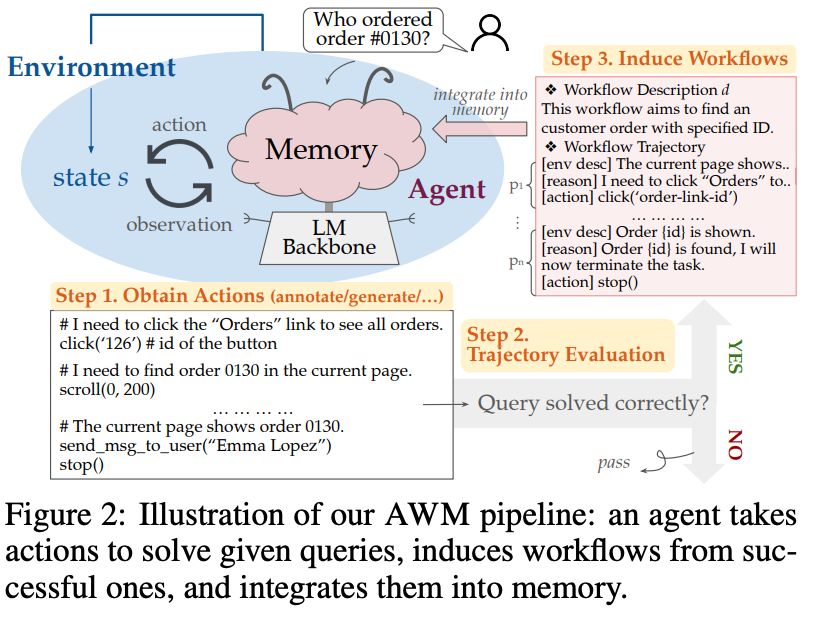
4.) Agent Workflow Memory ( paper )
Despite the potential of language model-based agents to solve real-world tasks such as web navigation, current methods still struggle with long-horizon tasks with complex action trajectories. In contrast, humans can flexibly solve complex tasks by learning reusable task workflows from past experiences and using them to guide future actions. To build agents that can similarly benefit from this process, we introduce Agent Workflow Memory (AWM), a method for inducing commonly reused routines, i.e., workflows, and selectively providing workflows to the agent to guide subsequent generations. AWM flexibly applies to both offline and online scenarios, where agents induce workflows from training examples beforehand or from test queries on the fly. We experiment on two major web navigation benchmarks -- Mind2Web and WebArena -- that collectively cover 1000+ tasks from 200+ domains across travel, shopping, and social media, among others. AWM substantially improves the baseline results by 24.6% and 51.1% relative success rate on Mind2Web and WebArena while reducing the number of steps taken to solve WebArena tasks successfully. Furthermore, online AWM robustly generalizes in cross-task, website, and domain evaluations, surpassing baselines from 8.9 to 14.0 absolute points as train-test task distribution gaps widen.
5.) SciAgents: Automating scientific discovery through multi-agent intelligent graph reasoning ( paper )
A key challenge in artificial intelligence is the creation of systems capable of autonomously advancing scientific understanding by exploring novel domains, identifying complex patterns, and uncovering previously unseen connections in vast scientific data. In this work, we present SciAgents, an approach that leverages three core concepts: (1) the use of large-scale ontological knowledge graphs to organize and interconnect diverse scientific concepts, (2) a suite of large language models (LLMs) and data retrieval tools, and (3) multi-agent systems with in-situ learning capabilities. Applied to biologically inspired materials, SciAgents reveals hidden interdisciplinary relationships that were previously considered unrelated, achieving a scale, precision, and exploratory power that surpasses traditional human-driven research methods. The framework autonomously generates and refines research hypotheses, elucidating underlying mechanisms, design principles, and unexpected material properties. By integrating these capabilities in a modular fashion, the intelligent system yields material discoveries, critique and improve existing hypotheses, retrieve up-to-date data about existing research, and highlights their strengths and limitations. Our case studies demonstrate scalable capabilities to combine generative AI, ontological representations, and multi-agent modeling, harnessing a `swarm of intelligence' similar to biological systems. This provides new avenues for materials discovery and accelerates the development of advanced materials by unlocking Nature's design principles.

6.) Click2Mask: Local Editing with Dynamic Mask Generation ( webpage | paper )
Recent advancements in generative models have revolutionized image generation and editing, making these tasks accessible to non-experts. This paper focuses on local image editing, particularly the task of adding new content to a loosely specified area. Existing methods often require a precise mask or a detailed description of the location, which can be cumbersome and prone to errors. We propose Click2Mask, a novel approach that simplifies the local editing process by requiring only a single point of reference (in addition to the content description). A mask is dynamically grown around this point during a Blended Latent Diffusion (BLD) process, guided by a masked CLIP-based semantic loss. Click2Mask surpasses the limitations of segmentation-based and fine-tuning dependent methods, offering a more user-friendly and contextually accurate solution. Our experiments demonstrate that Click2Mask not only minimizes user effort but also delivers competitive or superior local image manipulation results compared to SoTA methods, according to both human judgement and automatic metrics. Key contributions include the simplification of user input, the ability to freely add objects unconstrained by existing segments, and the integration potential of our dynamic mask approach within other editing methods.
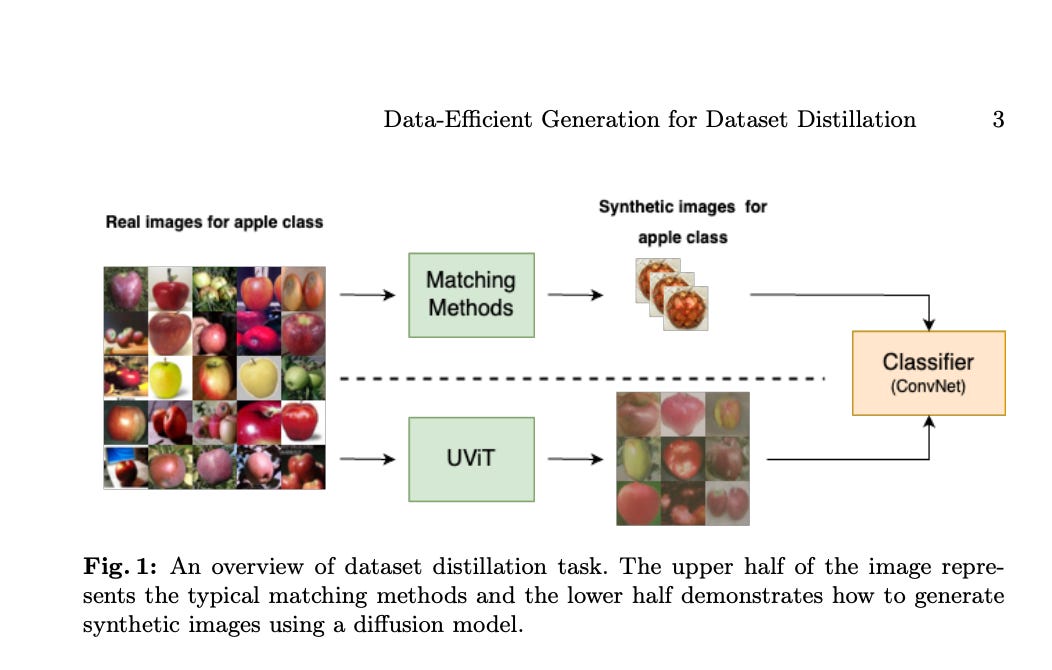
7.) Data-Efficient Generation for Dataset Distillation ( paper )
While deep learning techniques have proven successful in image-related tasks, the exponentially increased data storage and computation costs become a significant challenge. Dataset distillation addresses these challenges by synthesizing only a few images for each class that encapsulate all essential information. Most current methods focus on matching. The problems lie in the synthetic images not being human-readable and the dataset performance being insufficient for downstream learning tasks. Moreover, the distillation time can quickly get out of bounds when the number of synthetic images per class increases even slightly. To address this, we train a class conditional latent diffusion model capable of generating realistic synthetic images with labels. The sampling time can be reduced to several tens of images per seconds. We demonstrate that models can be effectively trained using only a small set of synthetic images and evaluated on a large real test set. Our approach achieved rank \(1\) in The First Dataset Distillation Challenge at ECCV 2024 on the CIFAR100 and TinyImageNet datasets.
8.) MarS: a Financial Market Simulation Engine Powered by Generative Foundation Model ( paper )
Generative models aim to simulate realistic effects of various actions across different contexts, from text generation to visual effects. Despite efforts to build real-world simulators, leveraging generative models for virtual worlds, like financial markets, remains underexplored. In financial markets, generative models can simulate market effects of various behaviors, enabling interaction with market scenes and players, and training strategies without financial risk. This simulation relies on the finest structured data in financial market like orders thus building the finest realistic simulation. We propose Large Market Model (LMM), an order-level generative foundation model, for financial market simulation, akin to language modeling in the digital world. Our financial Market Simulation engine (MarS), powered by LMM, addresses the need for realistic, interactive and controllable order generation. Key objectives of this paper include evaluating LMM's scaling law in financial markets, assessing MarS's realism, balancing controlled generation with market impact, and demonstrating MarS's potential applications. We showcase MarS as a forecast tool, detection system, analysis platform, and agent training environment. Our contributions include pioneering a generative model for financial markets, designing MarS to meet domain-specific needs, and demonstrating MarS-based applications' industry potential.

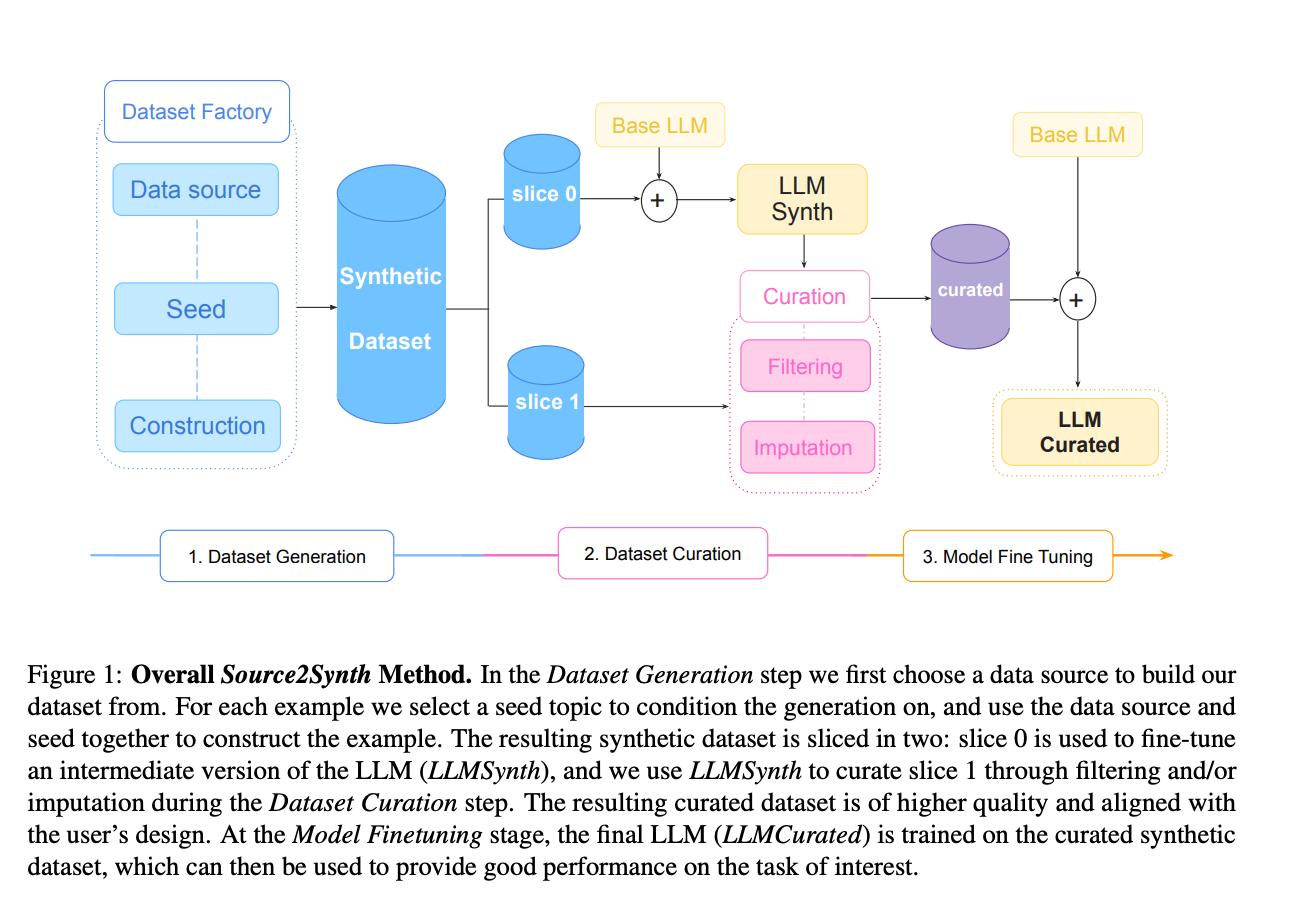
9.) Source2Synth: Synthetic Data Generation and Curation Grounded in Real Data Sources ( paper )
Large Language Models still struggle in challenging scenarios that leverage structured data, complex reasoning, or tool usage. In this paper, we propose Source2Synth: a new method that can be used for teaching LLMs new skills without relying on costly human annotations. Source2Synth takes as input a custom data source and produces synthetic data points with intermediate reasoning steps grounded in real-world sources. Source2Synth improves the dataset quality by discarding low-quality generations based on their answerability. We demonstrate the generality of this approach by applying it to two challenging domains: we test reasoning abilities in multi-hop question answering (MHQA), and tool usage in tabular question answering (TQA). Our method improves performance by 25.51% for TQA on WikiSQL and 22.57% for MHQA on HotPotQA compared to the fine-tuned baselines.
10.) What is the Role of Small Models in the LLM Era: A Survey ( paper | code )
Large Language Models (LLMs) have made significant progress in advancing artificial general intelligence (AGI), leading to the development of increasingly large models such as GPT-4 and LLaMA-405B. However, scaling up model sizes results in exponentially higher computational costs and energy consumption, making these models impractical for academic researchers and businesses with limited resources. At the same time, Small Models (SMs) are frequently used in practical settings, although their significance is currently underestimated. This raises important questions about the role of small models in the era of LLMs, a topic that has received limited attention in prior research. In this work, we systematically examine the relationship between LLMs and SMs from two key perspectives: Collaboration and Competition. We hope this survey provides valuable insights for practitioners, fostering a deeper understanding of the contribution of small models and promoting more efficient use of computational resources.

AIGC News of the week(September 09 - September 15)
1.) g1: Using Llama-3.1 70b on Groq to create o1-like reasoning chains ( repo )

2.) Raspberry:Create an open source toy dataset for finetuning LLMs with reasoning abilities( repo )
3.) Fei-Fei Li’ s new spatially intelligent startup: world labs ( link )
4.) spann3r:3D Reconstruction with Spatial Memory ( repo )
5.) ell: A language model programming library ( repo )
more AIGC News: AINews