Top Papers of the week(July 29 - August 04)
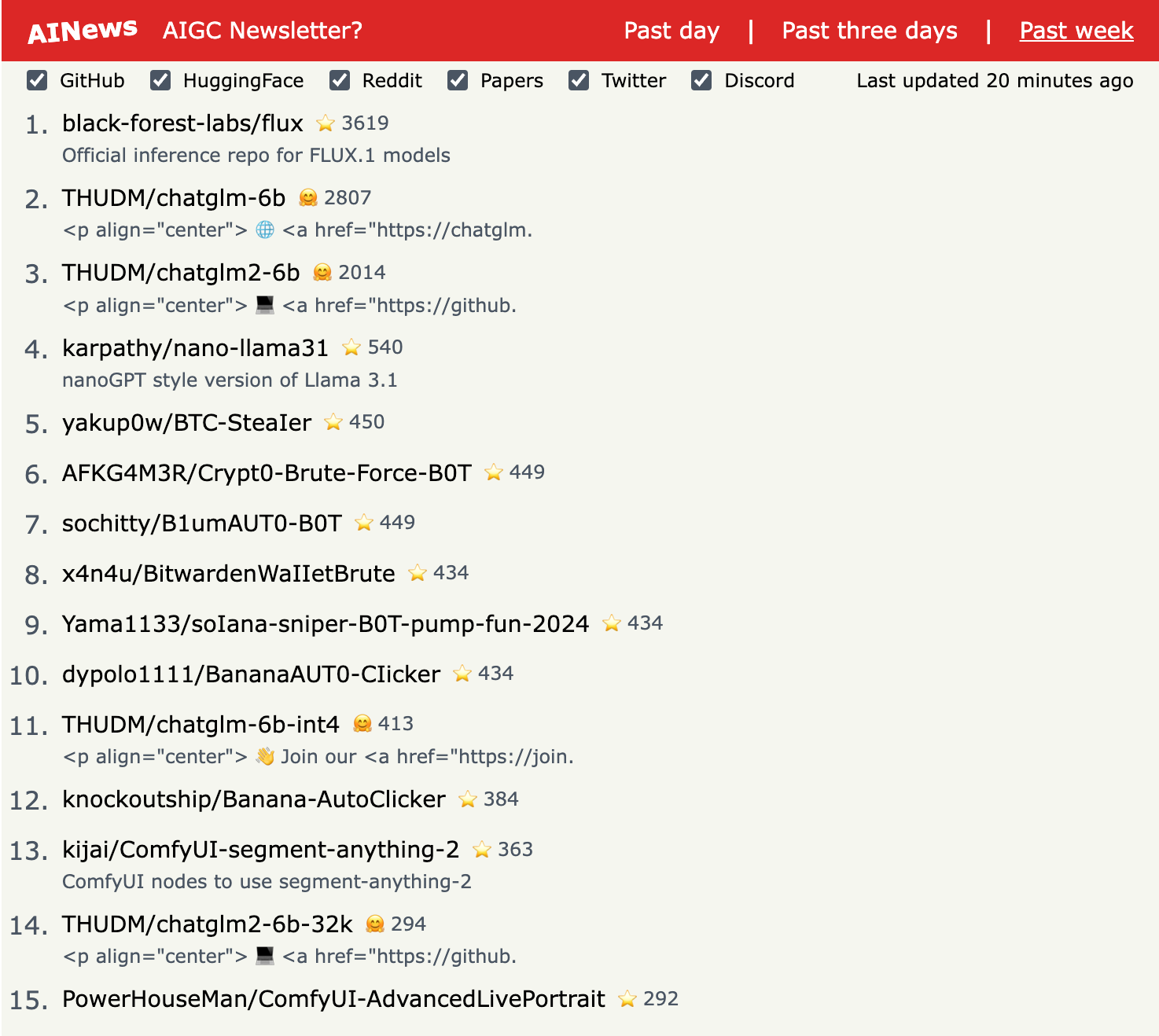
1.) Apple Intelligence Foundation Language Models( paper )
We present foundation language models developed to power Apple Intelligence features, including a ~3 billion parameter model designed to run efficiently on devices and a large server-based language model designed for Private Cloud Compute. These models are designed to perform a wide range of tasks efficiently, accurately, and responsibly. This report describes the model architecture, the data used to train the model, the training process, how the models are optimized for inference, and the evaluation results. We highlight our focus on Responsible AI and how the principles are applied throughout the model development.
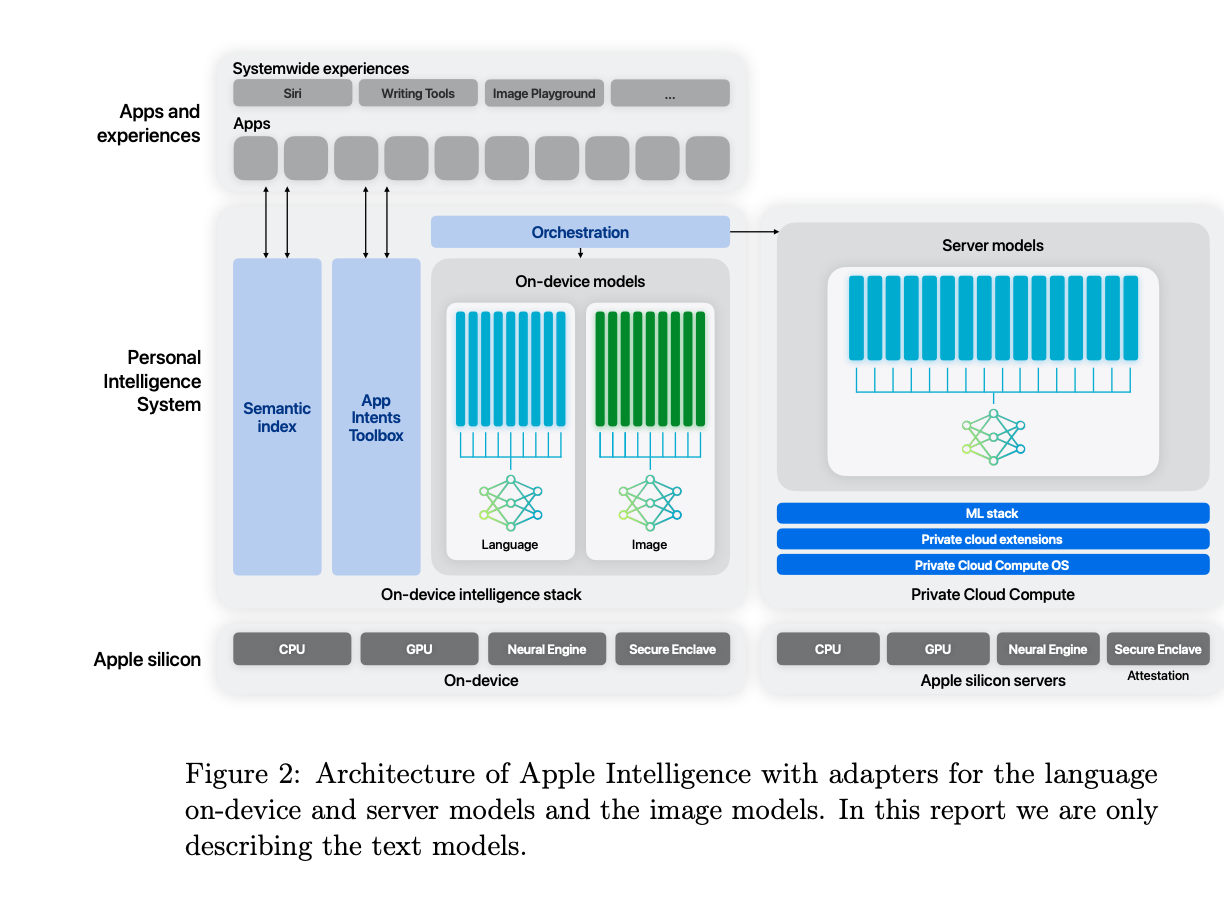
2.) Meta-Rewarding Language Models: Self-Improving Alignment with LLM-as-a-Meta-Judge( paper )
Large Language Models (LLMs) are rapidly surpassing human knowledge in many domains. While improving these models traditionally relies on costly human data, recent self-rewarding mechanisms (Yuan et al., 2024) have shown that LLMs can improve by judging their own responses instead of relying on human labelers. However, existing methods have primarily focused on improving model responses rather than judgment capabilities, resulting in rapid saturation during iterative training. To address this issue, we introduce a novel Meta-Rewarding step to the self-improvement process, where the model judges its own judgements and uses that feedback to refine its judgment skills. Surprisingly, this unsupervised approach improves the model's ability to judge {\em and} follow instructions, as demonstrated by a win rate improvement of Llama-3-8B-Instruct from 22.9% to 39.4% on AlpacaEval 2, and 20.6% to 29.1% on Arena-Hard. These results strongly suggest the potential for self-improving models without human supervision.
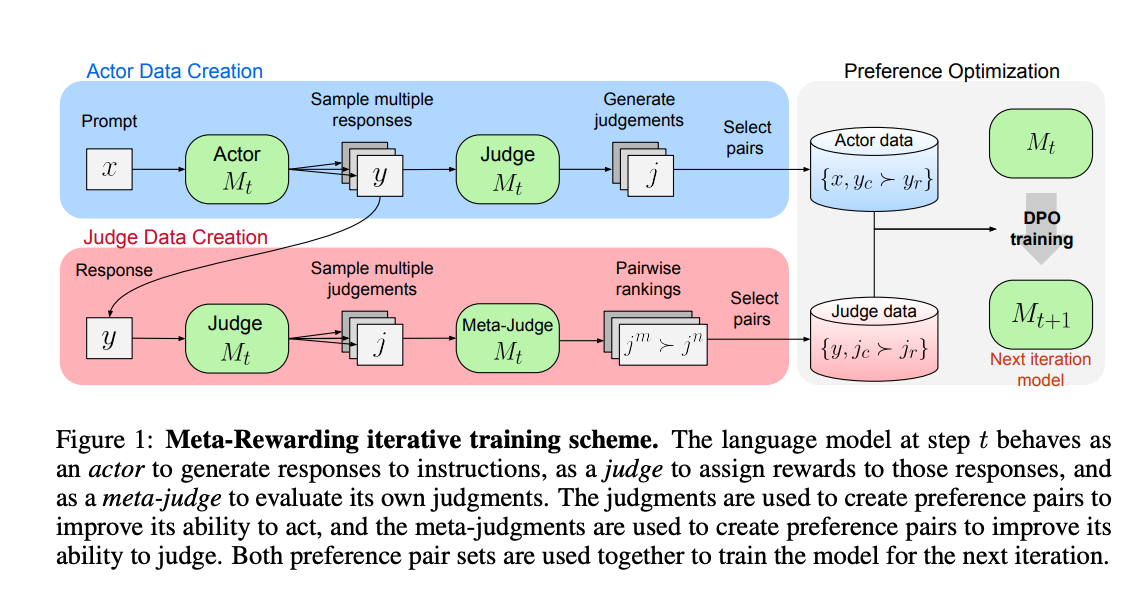
3.) Gemma 2: Improving Open Language Models at a Practical Size( paper )
In this work, we introduce Gemma 2, a new addition to the Gemma family of lightweight, state-of-the-art open models, ranging in scale from 2 billion to 27 billion parameters. In this new version, we apply several known technical modifications to the Transformer architecture, such as interleaving local-global attentions (Beltagy et al., 2020a) and group-query attention (Ainslie et al., 2023). We also train the 2B and 9B models with knowledge distillation (Hinton et al., 2015) instead of next token prediction. The resulting models deliver the best performance for their size, and even offer competitive alternatives to models that are 2-3 times bigger. We release all our models to the community.
4.) SF3D: Stable Fast 3D Mesh Reconstruction with UV-unwrapping and Illumination Disentanglement ( webpage | paper )
We present SF3D, a novel method for rapid and high-quality textured object mesh reconstruction from a single image in just 0.5 seconds. Unlike most existing approaches, SF3D is explicitly trained for mesh generation, incorporating a fast UV unwrapping technique that enables swift texture generation rather than relying on vertex colors. The method also learns to predict material parameters and normal maps to enhance the visual quality of the reconstructed 3D meshes. Furthermore, SF3D integrates a delighting step to effectively remove low-frequency illumination effects, ensuring that the reconstructed meshes can be easily used in novel illumination conditions.
5.) MindSearch: Mimicking Human Minds Elicits Deep AI Searcher ( webpage | paper | demo )
Information seeking and integration is a complex cognitive task that consumes enormous time and effort. Inspired by the remarkable progress of Large Language Models, recent works attempt to solve this task by combining LLMs and search engines. However, these methods still obtain unsatisfying performance due to three challenges: (1) complex requests often cannot be accurately and completely retrieved by the search engine once (2) corresponding information to be integrated is spread over multiple web pages along with massive noise, and (3) a large number of web pages with long contents may quickly exceed the maximum context length of LLMs. Inspired by the cognitive process when humans solve these problems, we introduce MindSearch to mimic the human minds in web information seeking and integration, which can be instantiated by a simple yet effective LLM-based multi-agent framework.
6.) Tora: Trajectory-oriented Diffusion Transformer for Video Generation(webpage | paper )
Recent advancements in Diffusion Transformer (DiT) have demonstrated remarkable proficiency in producing high-quality video content. Nonetheless, the potential of transformer-based diffusion models for effectively generating videos with controllable motion remains an area of limited exploration. This paper introduces Tora, the first trajectory-oriented DiT framework that integrates textual, visual, and trajectory conditions concurrently for video generation.
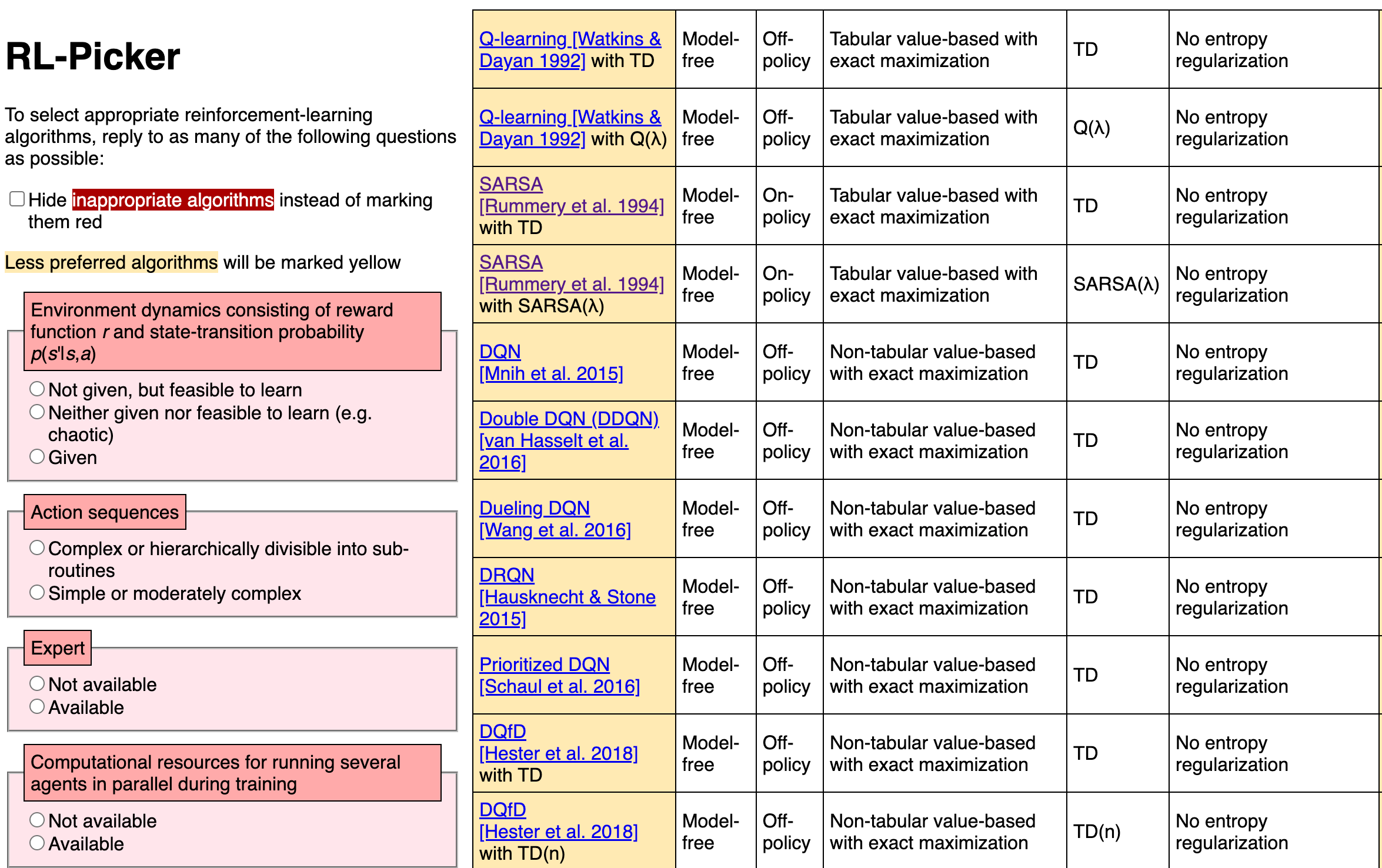
7.) How to Choose a Reinforcement-Learning Algorithm ( webpage | paper )
The field of reinforcement learning offers a large variety of concepts and methods to tackle sequential decision-making problems. This variety has become so large that choosing an algorithm for a task at hand can be challenging. In this work, we streamline the process of choosing reinforcement-learning algorithms and action-distribution families. We provide a structured overview of existing methods and their properties, as well as guidelines for when to choose which methods.
8.) SAM 2: Segment Anything in Images and Videos ( webpage | paper )
We present Segment Anything Model 2 (SAM 2), a foundation model towards solving promptable visual segmentation in images and videos. We build a data engine, which improves model and data via user interaction, to collect the largest video segmentation dataset to date. Our model is a simple transformer architecture with streaming memory for real-time video processing. SAM 2 trained on our data provides strong performance across a wide range of tasks. In video segmentation, we observe better accuracy, using 3x fewer interactions than prior approaches. In image segmentation, our model is more accurate and 6x faster than the Segment Anything Model (SAM). We believe that our data, model, and insights will serve as a significant milestone for video segmentation and related perception tasks. We are releasing a version of our model, the dataset and an interactive demo.
9.) Machine Unlearning in Generative AI: A Survey ( paper | repo )
Generative AI technologies have been deployed in many places, such as (multimodal) large language models and vision generative models. Their remarkable performance should be attributed to massive training data and emergent reasoning abilities. However, the models would memorize and generate sensitive, biased, or dangerous information originated from the training data especially those from web crawl. New machine unlearning (MU) techniques are being developed to reduce or eliminate undesirable knowledge and its effects from the models, because those that were designed for traditional classification tasks could not be applied for Generative AI. We offer a comprehensive survey on many things about MU in Generative AI, such as a new problem formulation, evaluation methods, and a structured discussion on the advantages and limitations of different kinds of MU techniques. It also presents several critical challenges and promising directions in MU research.

10.) The Art of Refusal: A Survey of Abstention in Large Language Models ( paper )
Abstention, the refusal of large language models (LLMs) to provide an answer, is increasingly recognized for its potential to mitigate hallucinations and enhance safety in building LLM systems. In this survey, we introduce a framework to examine abstention behavior from three perspectives: the query, the model, and human values. We review the literature on abstention methods (categorized based on the development stages of LLMs), benchmarks, and evaluation metrics, and discuss the merits and limitations of prior work. We further identify and motivate areas for future research, such as encouraging the study of abstention as a meta-capability across tasks and customizing abstention abilities based on context. In doing so, we aim to broaden the scope and impact of abstention methodologies in AI systems.

AIGC News of the week(July 29 - August 04)
1.) FLUX.1: A new era of creation ( webpage | model | repo )
The best of FLUX.1, offering state-of-the-art performance image generation with top of the line prompt following, visual quality, image detail and output diversity.
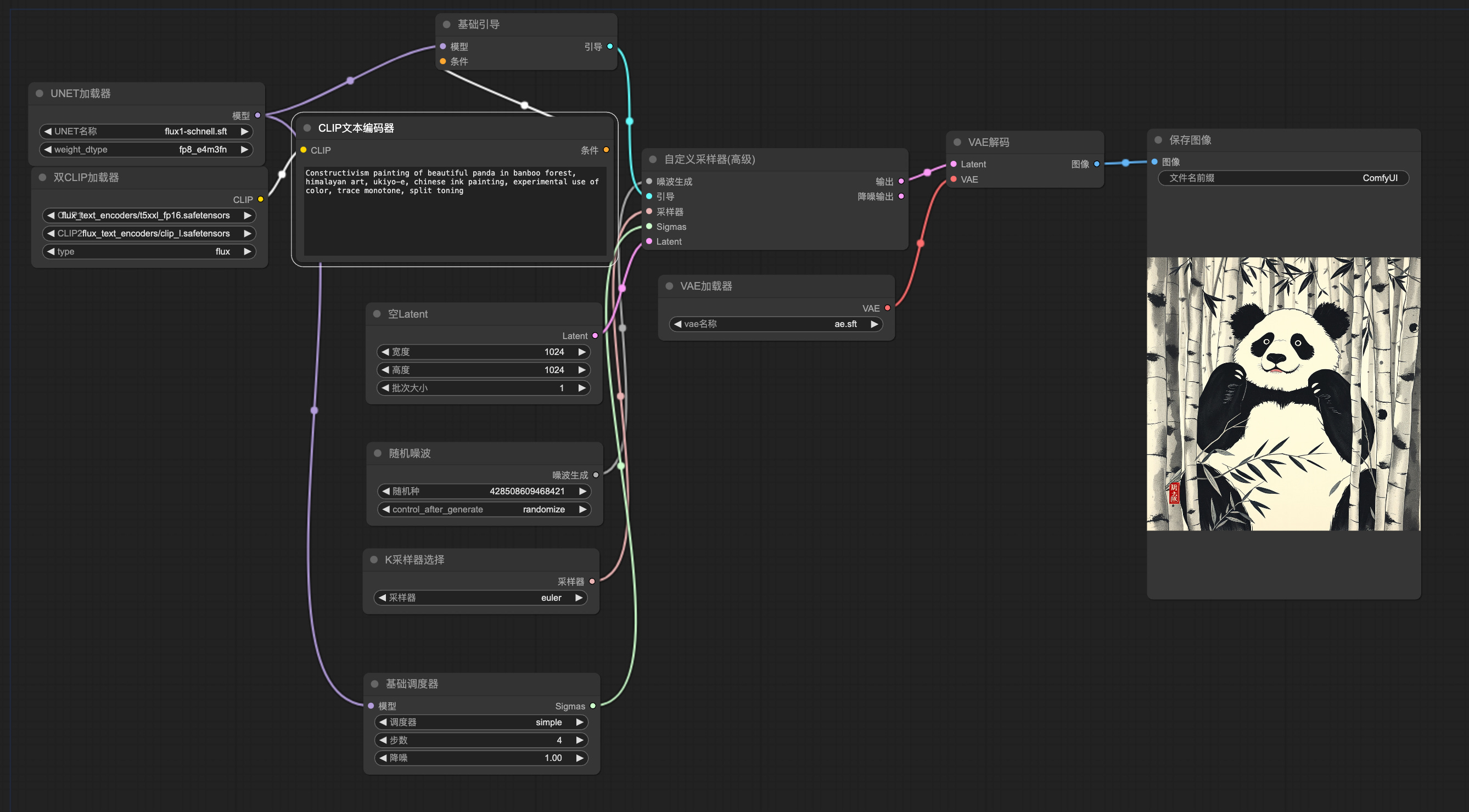
2.) ComfyUI-segment-anything-2 ( repo )
3.) nano-llama31: nanoGPT style version of Llama 3.1 ( repo )
4.) tiny-tpu: A minimal Tensor Processing Unit (TPU) inspired by Google's TPUv1 ( repo)
5.) Awesome 3D Gaussian Splatting Resources ( repo )
more AIGC News: AINews