Top Papers of the week(July 22 - July 28)
1.) Introducing Llama 3.1: Our most capable models to date ( webpage | paper | model | repo )
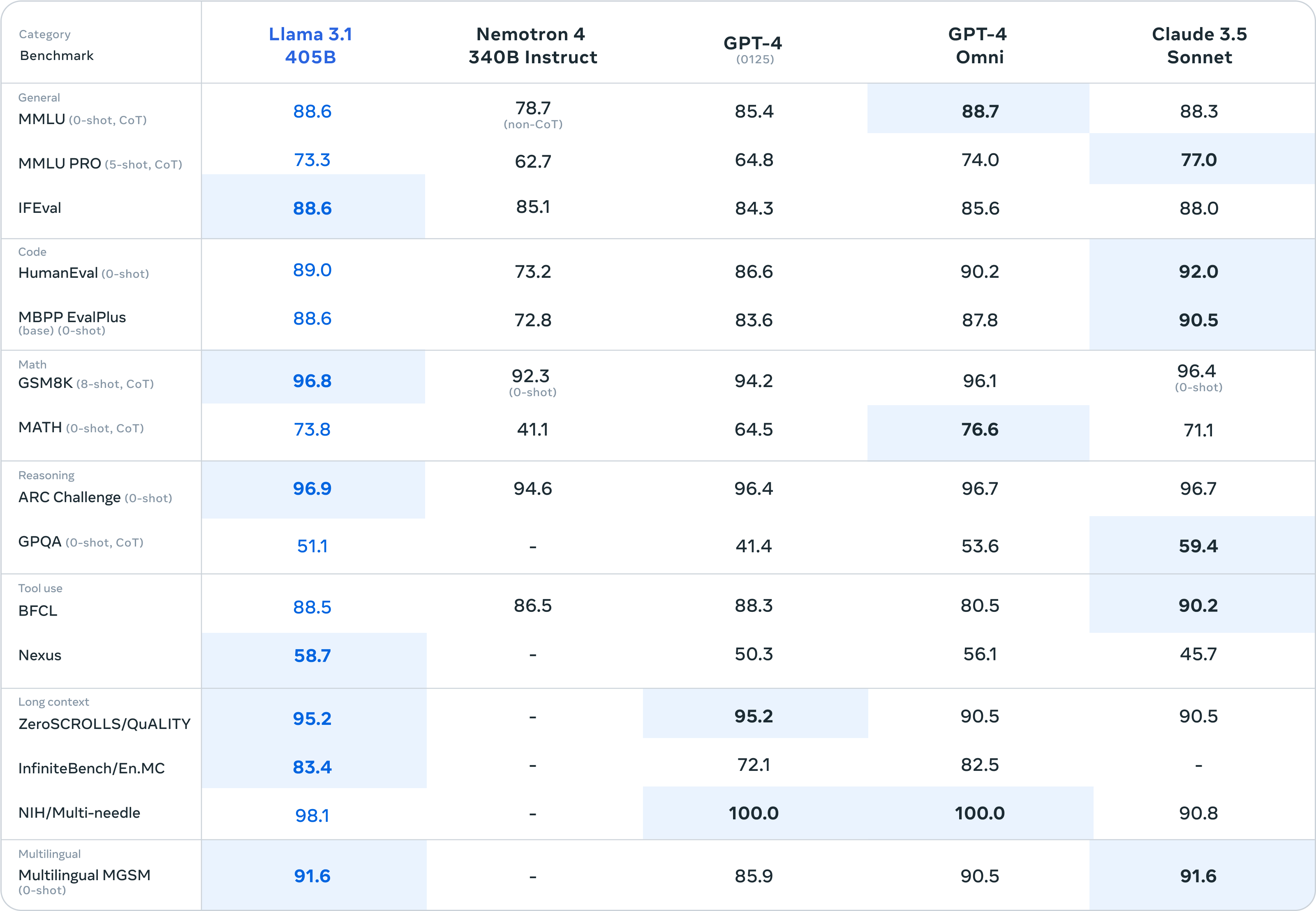
Llama 3.1 405B is the first openly available model that rivals the top AI models when it comes to state-of-the-art capabilities in general knowledge, steerability, math, tool use, and multilingual translation. With the release of the 405B model, we’re poised to supercharge innovation—with unprecedented opportunities for growth and exploration. We believe the latest generation of Llama will ignite new applications and modeling paradigms, including synthetic data generation to enable the improvement and training of smaller models, as well as model distillation—a capability that has never been achieved at this scale in open source.
2.) Mistral Large 2 ( webpage | model )
we are announcing Mistral Large 2, the new generation of our flagship model. Compared to its predecessor, Mistral Large 2 is significantly more capable in code generation, mathematics, and reasoning. It also provides a much stronger multilingual support, and advanced function calling capabilities.
Mistral Large 2 has a 128k context window and supports dozens of languages including French, German, Spanish, Italian, Portuguese, Arabic, Hindi, Russian, Chinese, Japanese, and Korean, along with 80+ coding languages including Python, Java, C, C++, JavaScript, and Bash.

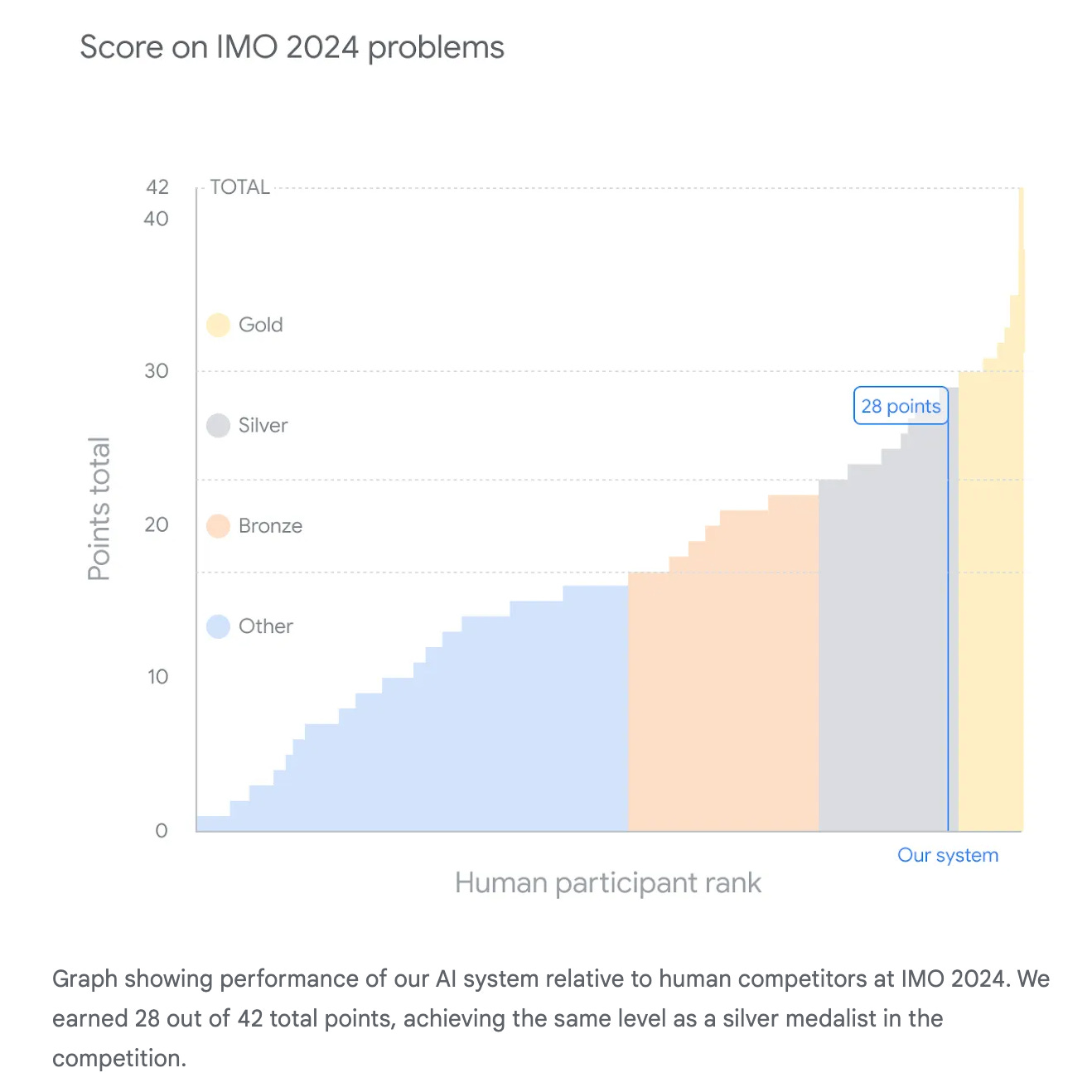
3.) AI achieves silver-medal standard solving International Mathematical Olympiad problems ( webpage )
we present AlphaProof, a new reinforcement-learning based system for formal math reasoning, and AlphaGeometry 2, an improved version of our geometry-solving system. Together, these systems solved four out of six problems from this year’s International Mathematical Olympiad (IMO), achieving the same level as a silver medalist in the competition for the first time.
4.) Imagine yourself: Tuning-Free Personalized Image Generation ( paper )
Diffusion models have demonstrated remarkable efficacy across various image-to-image tasks. In this research, we introduce Imagine yourself, a state-of-the-art model designed for personalized image generation. Unlike conventional tuning-based personalization techniques, Imagine yourself operates as a tuning-free model, enabling all users to leverage a shared framework without individualized adjustments. Moreover, previous work met challenges balancing identity preservation, following complex prompts and preserving good visual quality, resulting in models having strong copy-paste effect of the reference images. Thus, they can hardly generate images following prompts that require significant changes to the reference image, e.g., changing facial expression, head and body poses, and the diversity of the generated images is low.

5.) Stretching Each Dollar: Diffusion Training from Scratch on a Micro-Budget (paper)
As scaling laws in generative AI push performance, they also simultaneously concentrate the development of these models among actors with large computational resources. With a focus on text-to-image (T2I) generative models, we aim to address this bottleneck by demonstrating very low-cost training of large-scale T2I diffusion transformer models. As the computational cost of transformers increases with the number of patches in each image, we propose to randomly mask up to 75% of the image patches during training. We propose a deferred masking strategy that preprocesses all patches using a patch-mixer before masking, thus significantly reducing the performance degradation with masking, making it superior to model downscaling in reducing computational cost. We also incorporate the latest improvements in transformer architecture, such as the use of mixture-of-experts layers, to improve performance and further identify the critical benefit of using synthetic images in micro-budget training. Finally, using only 37M publicly available real and synthetic images, we train a 1.16 billion parameter sparse transformer with only $1,890 economical cost and achieve a 12.7 FID in zero-shot generation on the COCO dataset.

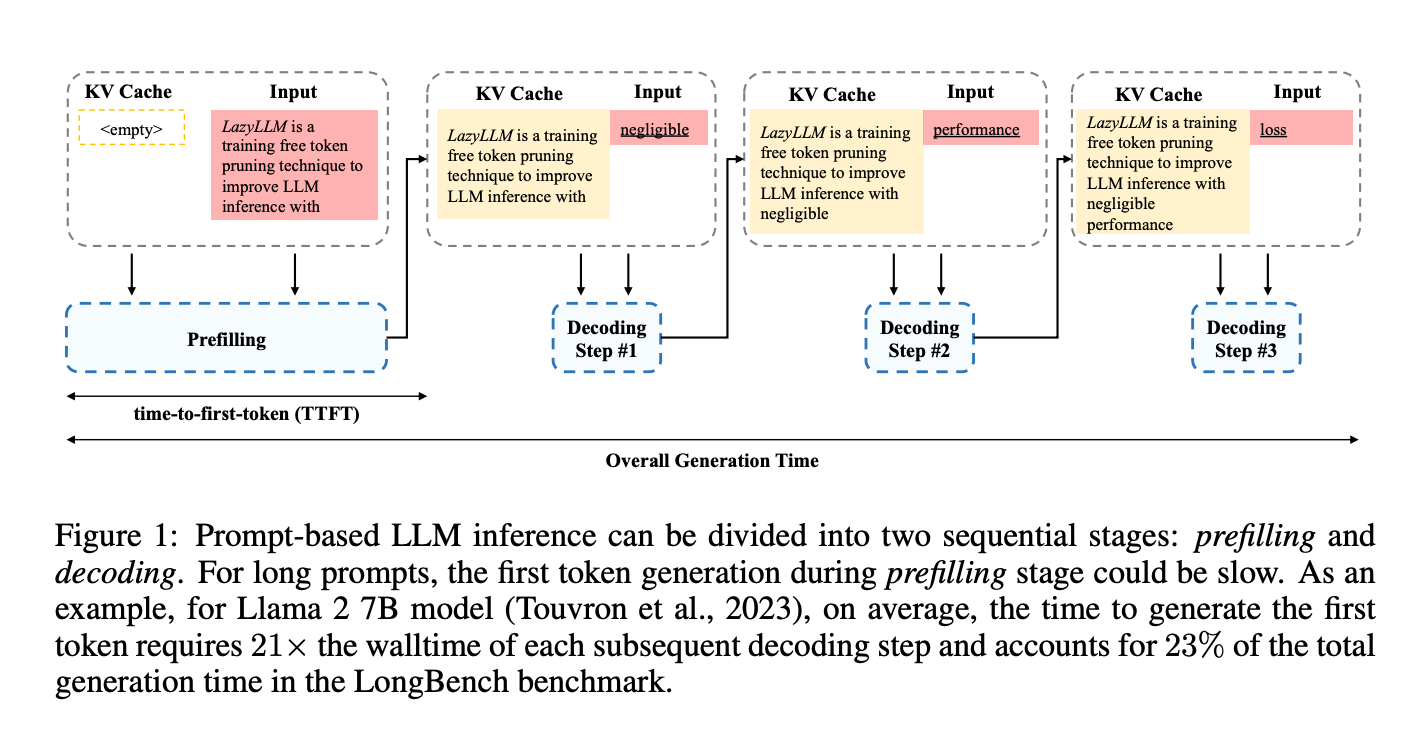
6.) LazyLLM: Dynamic Token Pruning for Efficient Long Context LLM Inference ( paper )
The inference of transformer-based large language models consists of two sequential stages: 1) a prefilling stage to compute the KV cache of prompts and generate the first token, and 2) a decoding stage to generate subsequent tokens. For long prompts, the KV cache must be computed for all tokens during the prefilling stage, which can significantly increase the time needed to generate the first token. Consequently, the prefilling stage may become a bottleneck in the generation process. An open question remains whether all prompt tokens are essential for generating the first token. To answer this, we introduce a novel method, LazyLLM, that selectively computes the KV for tokens important for the next token prediction in both the prefilling and decoding stages. Contrary to static pruning approaches that prune the prompt at once, LazyLLM allows language models to dynamically select different subsets of tokens from the context in different generation steps, even though they might be pruned in previous steps. Extensive experiments on standard datasets across various tasks demonstrate that LazyLLM is a generic method that can be seamlessly integrated with existing language models to significantly accelerate the generation without fine-tuning.For instance, in the multi-document question-answering task, LazyLLM accelerates the prefilling stage of the LLama 2 7B model by 2.34x while maintaining accuracy.
7.) OutfitAnyone: Ultra-high Quality Virtual Try-On for Any Clothing and Any Person ( webpage | paper )
Virtual Try-On (VTON) has become a transformative technology, empowering users to experiment with fashion without ever having to physically try on clothing. However, existing methods often struggle with generating high-fidelity and detail-consistent results. While diffusion models, such as Stable Diffusion series, have shown their capability in creating high-quality and photorealistic images, they encounter formidable challenges in conditional generation scenarios like VTON. Specifically, these models struggle to maintain a balance between control and consistency when generating images for virtual clothing trials. OutfitAnyone addresses these limitations by leveraging a two-stream conditional diffusion model, enabling it to adeptly handle garment deformation for more lifelike results. It distinguishes itself with scalability-modulating factors such as pose, body shape and broad applicability, extending from anime to in-the-wild images.

8.) SV4D: Dynamic 3D Content Generation with Multi-Frame and Multi-View Consistency ( webpage | paper )
We present Stable Video 4D (SV4D), a latent video diffusion model for multi-frame and multi-view consistent dynamic 3D content generation. Unlike previous methods that rely on separately trained generative models for video generation and novel view synthesis, we design a unified diffusion model to generate novel view videos of dynamic 3D objects. Specifically, given a monocular reference video, SV4D generates novel views for each video frame that are temporally consistent. We then use the generated novel view videos to optimize an implicit 4D representation (dynamic NeRF) efficiently, without the need for cumbersome SDS-based optimization used in most prior works. To train our unified novel view video generation model, we curated a dynamic 3D object dataset from the existing Objaverse dataset. Extensive experimental results on multiple datasets and user studies demonstrate SV4D's state-of-the-art performance on novel-view video synthesis as well as 4D generation compared to prior works.
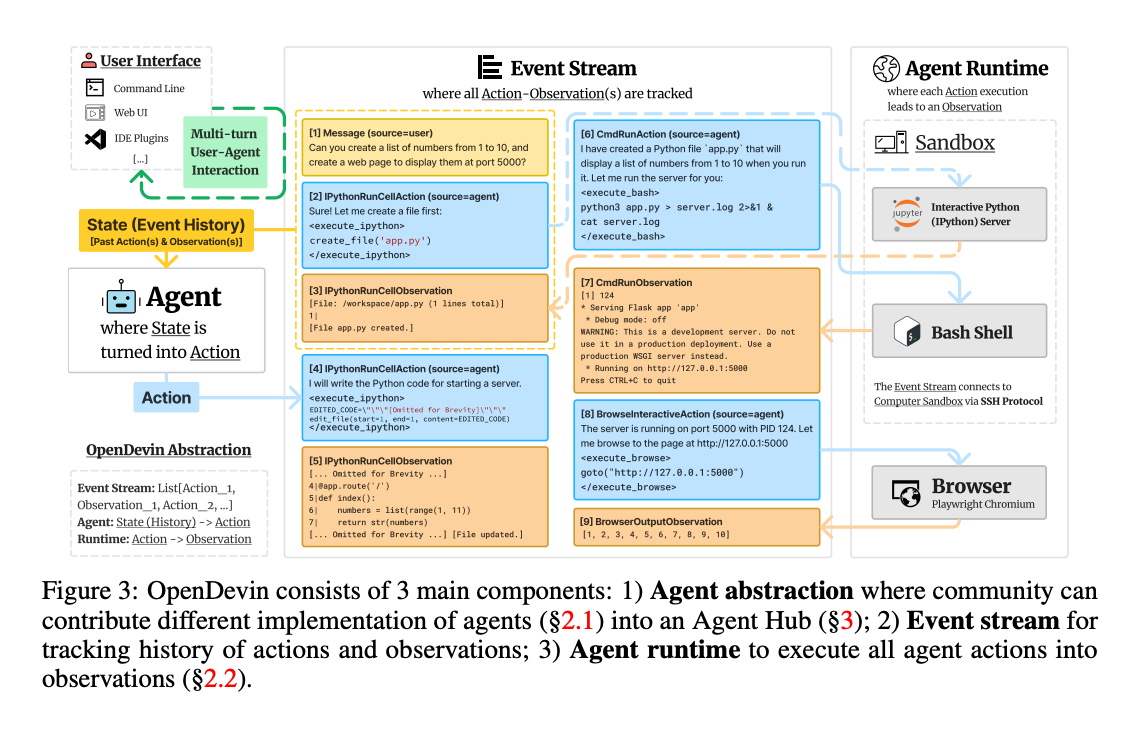
9.) OpenDevin: An Open Platform for AI Software Developers as Generalist Agents ( paper | repo | benchmark )
Software is one of the most powerful tools that we humans have at our disposal; it allows a skilled programmer to interact with the world in complex and profound ways. At the same time, thanks to improvements in large language models (LLMs), there has also been a rapid development in AI agents that interact with and affect change in their surrounding environments. In this paper, we introduce OpenDevin, a platform for the development of powerful and flexible AI agents that interact with the world in similar ways to those of a human developer: by writing code, interacting with a command line, and browsing the web. We describe how the platform allows for the implementation of new agents, safe interaction with sandboxed environments for code execution, coordination between multiple agents, and incorporation of evaluation benchmarks.
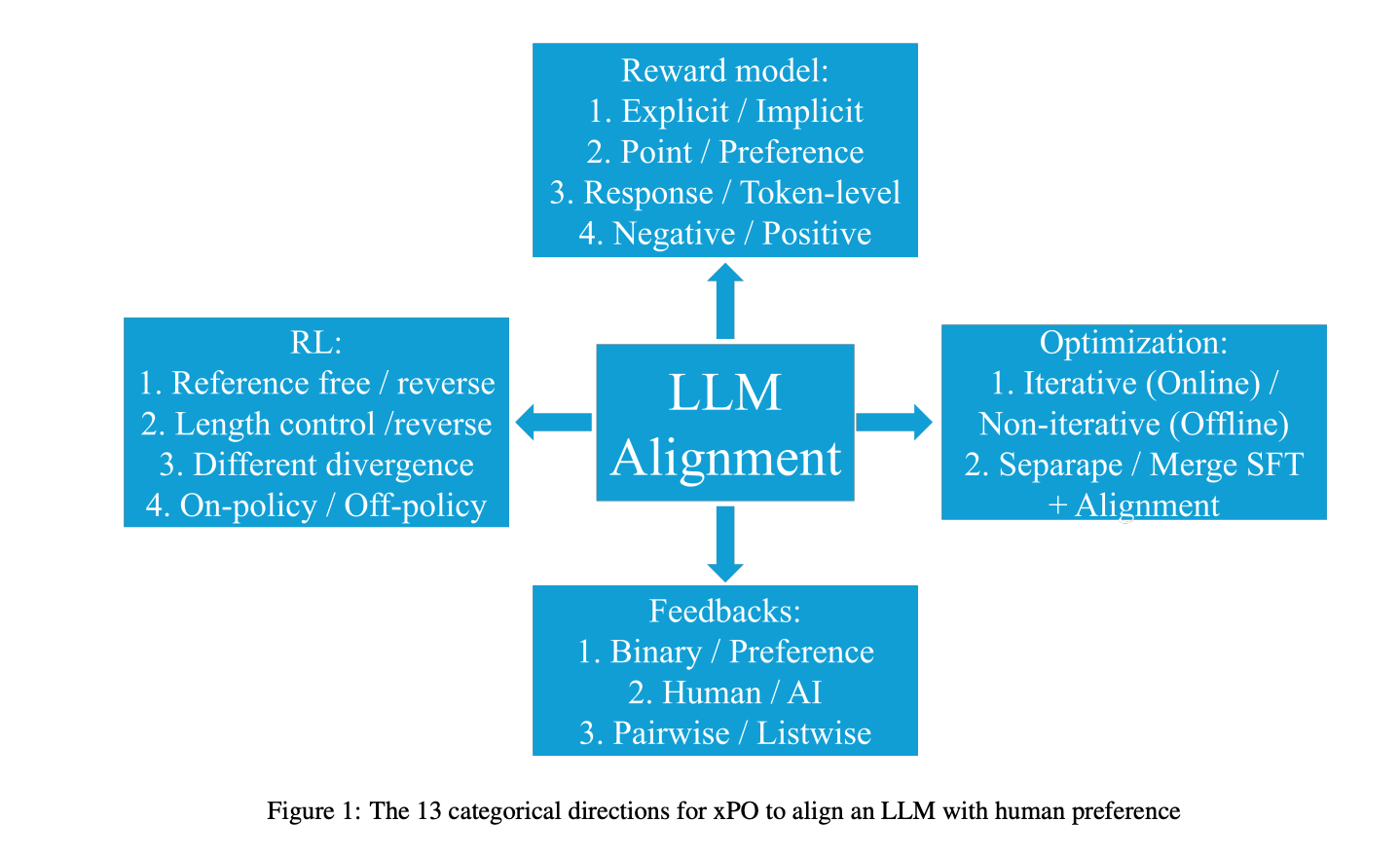
10.) A Comprehensive Survey of LLM Alignment Techniques: RLHF, RLAIF, PPO, DPO and More ( paper )
With advancements in self-supervised learning, the availability of trillions tokens in a pre-training corpus, instruction fine-tuning, and the development of large Transformers with billions of parameters, large language models (LLMs) are now capable of generating factual and coherent responses to human queries. However, the mixed quality of training data can lead to the generation of undesired responses, presenting a significant challenge. Over the past two years, various methods have been proposed from different perspectives to enhance LLMs, particularly in aligning them with human expectation. Despite these efforts, there has not been a comprehensive survey paper that categorizes and details these approaches. In this work, we aim to address this gap by categorizing these papers into distinct topics and providing detailed explanations of each alignment method, thereby helping readers gain a thorough understanding of the current state of the field.
AIGC News of the week(July 22 - July 28)
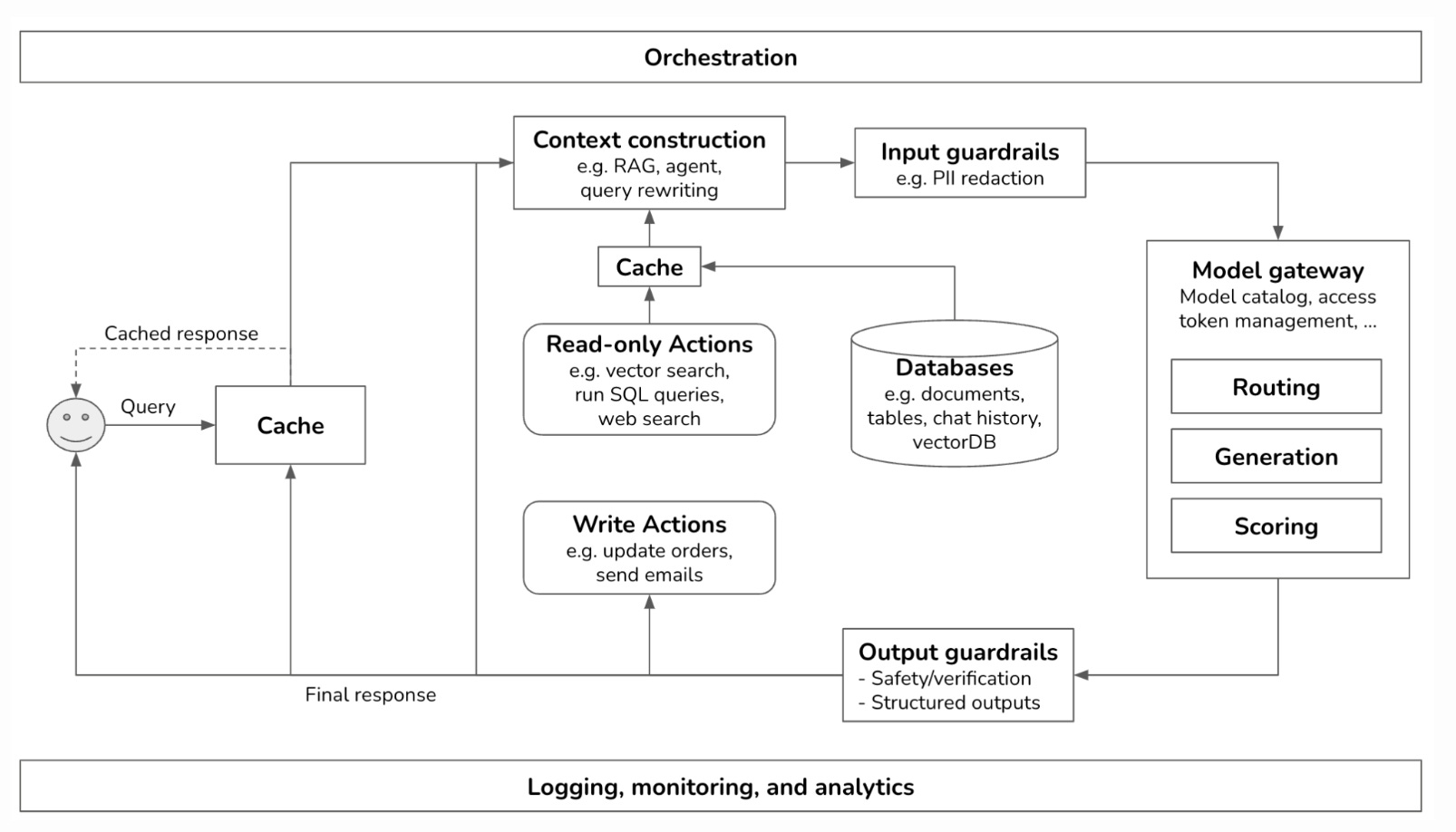
1. ) Building A Generative AI Platform by Chip Huyen ( link )
2.) Audio-Synchronized Visual Animation ( repo )
3.) pptx2md: a pptx to markdown converter ( repo )
4.) ktransformers: a Flexible Framework for Experiencing Cutting-edge LLM Inference Optimizations ( repo )
5.) AI Video Generator Runway Trained on Thousands of YouTube Videos Without Permission ( link )
more AIGC News: AINews