Top Papers of the week(July 08 - July 14)
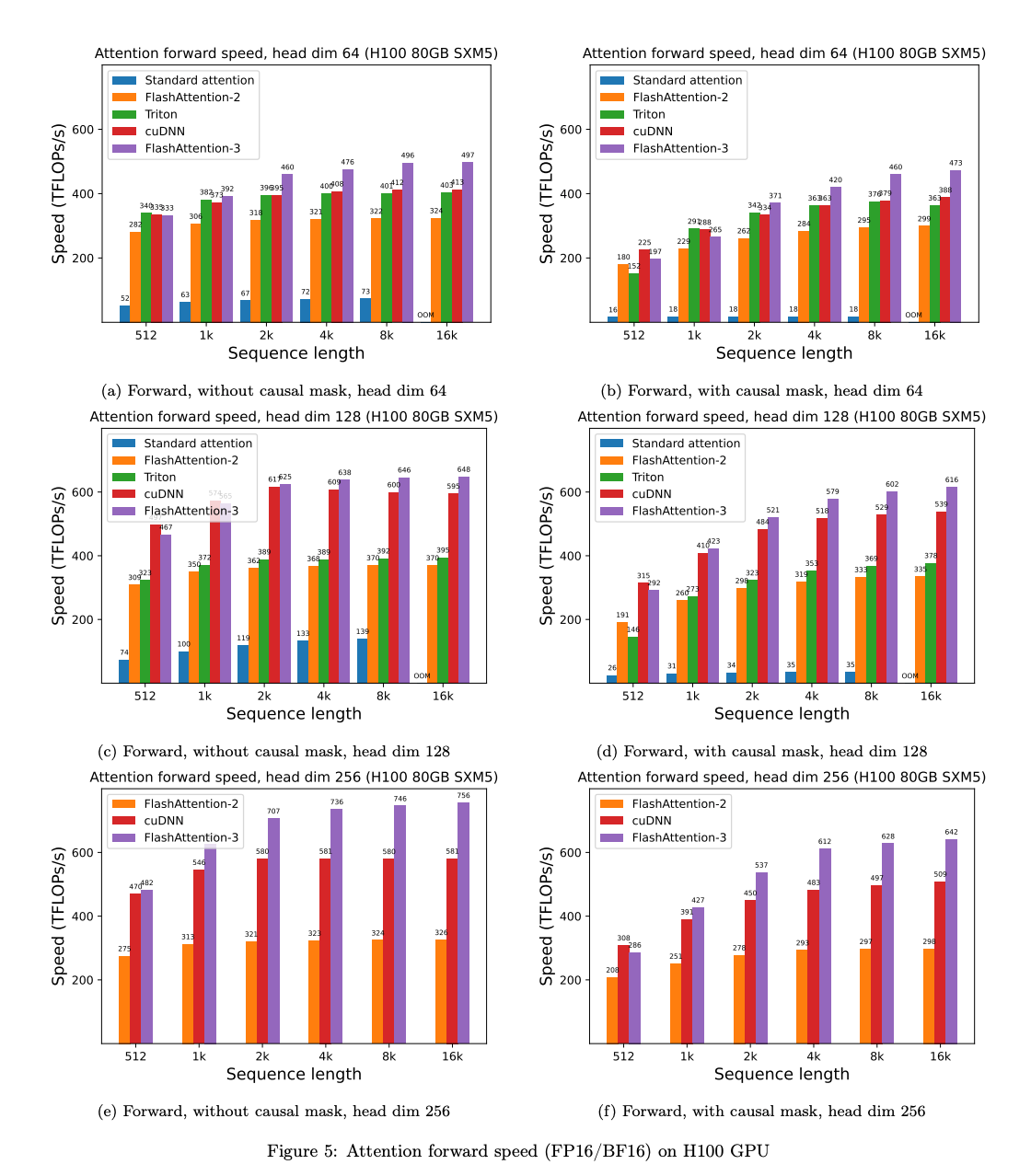
1.) FlashAttention-3: Fast and Accurate Attention with Asynchrony and Low-precision ( paper )
Attention, as a core layer of the ubiquitous Transformer architecture, is the bottleneck for large language models and long-context applications. FlashAttention elaborated an approach to speed up attention on GPUs through minimizing memory reads/writes. However, it has yet to take advantage of new capabilities present in recent hardware, with FlashAttention-2 achieving only 35% utilization on the H100 GPU. We develop three main techniques to speed up attention on Hopper GPUs: exploiting asynchrony of the Tensor Cores and TMA to (1) overlap overall computation and data movement via warp-specialization and (2) interleave block-wise matmul and softmax operations, and (3) block quantization and incoherent processing that leverages hardware support for FP8 low-precision. We demonstrate that our method, FlashAttention-3, achieves speedup on H100 GPUs by 1.5-2.0× with FP16 reaching up to 740 TFLOPs/s (75% utilization), and with FP8 reaching close to 1.2 PFLOPs/s. We validate that FP8 FlashAttention-3 achieves 2.6× lower numerical error than a baseline FP8 attention.
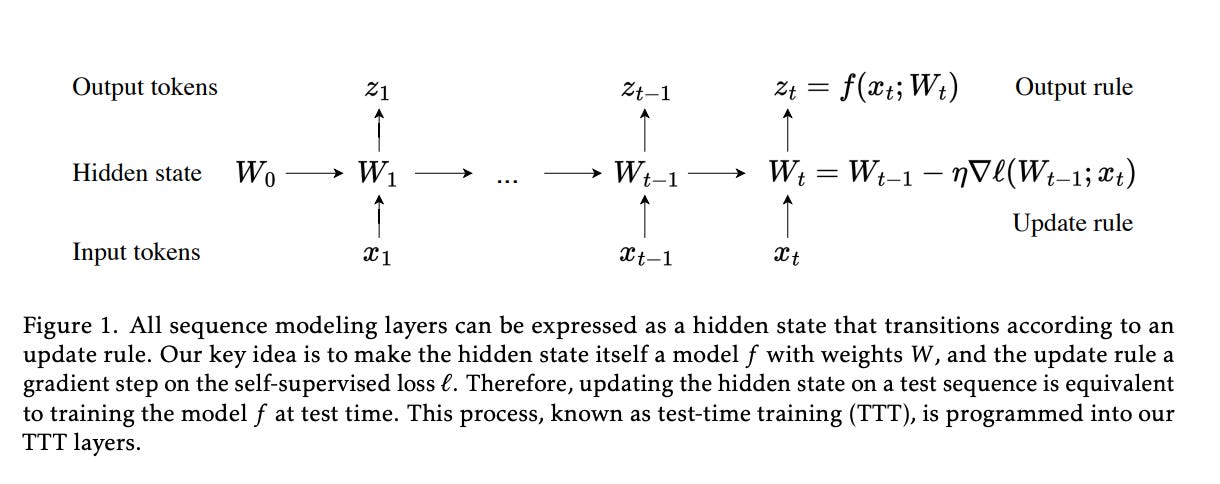
2.) Learning to (Learn at Test Time): RNNs with Expressive Hidden States ( paper )
Self-attention performs well in long context but has quadratic complexity. Existing RNN layers have linear complexity, but their performance in long context is limited by the expressive power of their hidden state. We propose a new class of sequence modeling layers with linear complexity and an expressive hidden state. The key idea is to make the hidden state a machine learning model itself, and the update rule a step of self-supervised learning. Since the hidden state is updated by training even on test sequences, our layers are called Test-Time Training (TTT) layers. We consider two instantiations: TTT-Linear and TTT-MLP, whose hidden state is a linear model and a two-layer MLP respectively.
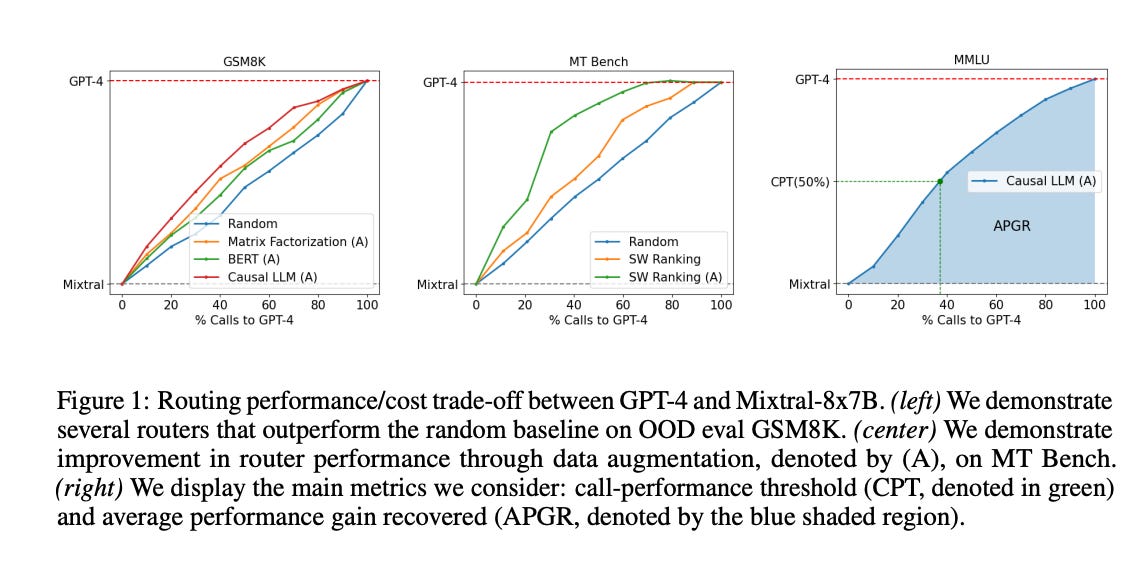
3.) RouteLLM: Learning to Route LLMs with Preference Data ( paper )
Large language models (LLMs) exhibit impressive capabilities across a wide range of tasks, yet the choice of which model to use often involves a trade-off between performance and cost. More powerful models, though effective, come with higher expenses, while less capable models are more cost-effective. To address this dilemma, we propose several efficient router models that dynamically select between a stronger and a weaker LLM during inference, aiming to optimize the balance between cost and response quality. We develop a training framework for these routers leveraging human preference data and data augmentation techniques to enhance performance.
4.) MiraData: A Large-Scale Video Dataset with Long Durations and Structured Captions ( paper | repo )
Sora's high-motion intensity and long consistent videos have significantly impacted the field of video generation, attracting unprecedented attention. However, existing publicly available datasets are inadequate for generating Sora-like videos, as they mainly contain short videos with low motion intensity and brief captions. To address these issues, we propose MiraData, a high-quality video dataset that surpasses previous ones in video duration, caption detail, motion strength, and visual quality. We curate MiraData from diverse, manually selected sources and meticulously process the data to obtain semantically consistent clips.

5.) FACTS About Building Retrieval Augmented Generation-based Chatbots ( paper )
Enterprise chatbots, powered by generative AI, are emerging as key applications to enhance employee productivity. Retrieval Augmented Generation (RAG), Large Language Models (LLMs), and orchestration frameworks like Langchain and Llamaindex are crucial for building these chatbots. However, creating effective enterprise chatbots is challenging and requires meticulous RAG pipeline engineering. This includes fine-tuning embeddings and LLMs, extracting documents from vector databases, rephrasing queries, reranking results, designing prompts, honoring document access controls, providing concise responses, including references, safeguarding personal information, and building orchestration agents. We present a framework for building RAG-based chatbots based on our experience with three NVIDIA chatbots: for IT/HR benefits, financial earnings, and general content.
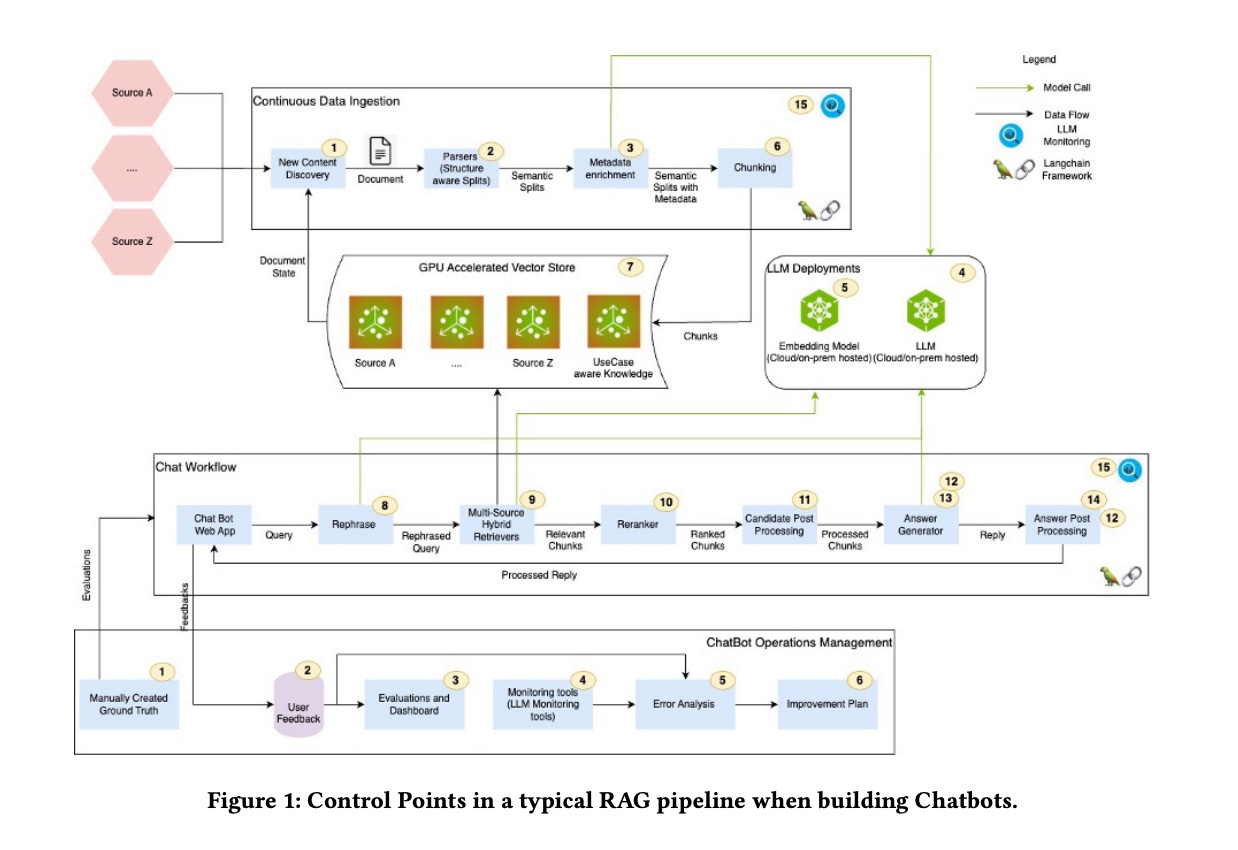
6.) Distilling System 2 into System 1 ( paper )
Large language models (LLMs) can spend extra compute during inference to generate intermediate thoughts, which helps to produce better final responses. Since Chain-of-Thought (Wei et al., 2022), many such System 2 techniques have been proposed such as Rephrase and Respond (Deng et al., 2023a), System 2 Attention (Weston and Sukhbaatar, 2023) and Branch-Solve-Merge (Saha et al., 2023). In this work we investigate self-supervised methods to ``compile'' (distill) higher quality outputs from System 2 techniques back into LLM generations without intermediate reasoning token sequences, as this reasoning has been distilled into System 1. We show that several such techniques can be successfully distilled, resulting in improved results compared to the original System 1 performance, and with less inference cost than System 2. We posit that such System 2 distillation will be an important feature of future continually learning AI systems, enabling them to focus System 2 capabilities on the reasoning tasks that they cannot yet do well.
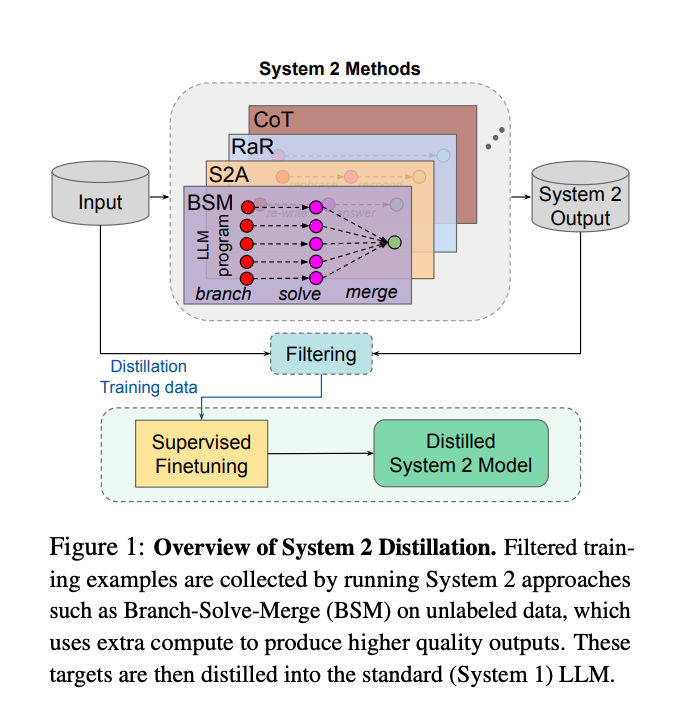
7.) Data, Data Everywhere: A Guide for Pretraining Dataset Construction ( paper )
The impressive capabilities of recent language models can be largely attributed to the multi-trillion token pretraining datasets that they are trained on. However, model developers fail to disclose their construction methodology which has lead to a lack of open information on how to develop effective pretraining sets. To address this issue, we perform the first systematic study across the entire pipeline of pretraining set construction. First, we run ablations on existing techniques for pretraining set development to identify which methods translate to the largest gains in model accuracy on downstream evaluations. Then, we categorize the most widely used data source, web crawl snapshots, across the attributes of toxicity, quality, type of speech, and domain. Finally, we show how such attribute information can be used to further refine and improve the quality of a pretraining set.
8.) Vision language models are blind ( webpage | paper )
Large language models with vision capabilities (VLMs), e.g., GPT-4o and Gemini-1.5 Pro are powering countless image-text applications and scoring high on many vision-understanding benchmarks. We propose BlindTest, a suite of 7 visual tasks absurdly easy to humans such as identifying (a) whether two circles overlap; (b) whether two lines intersect; (c) which letter is being circled in a word; and (d) counting the number of circles in a Olympic-like logo. Surprisingly, four state-of-theart VLMs are, on average, only 56.20% accurate on our benchmark, with Sonnet-3.5 being the best (73.77% accuracy). On BlindTest, VLMs struggle with tasks that requires precise spatial information and counting (from 0 to 10), sometimes providing an impression of a person with myopia seeing fine details as blurry and making educated guesses.

9.) BM25S: Orders of magnitude faster lexical search via eager sparse scoring ( paper | code )
We introduce BM25S, an efficient Python-based implementation of BM25 that only depends on Numpy and Scipy. BM25S achieves up to a 500x speedup compared to the most popular Python-based framework by eagerly computing BM25 scores during indexing and storing them into sparse matrices. It also achieves considerable speedups compared to highly optimized Java-based implementations, which are used by popular commercial products. Finally, BM25S reproduces the exact implementation of five BM25 variants based on Kamphuis et al. (2020) by extending eager scoring to non-sparse variants using a novel score shifting method.

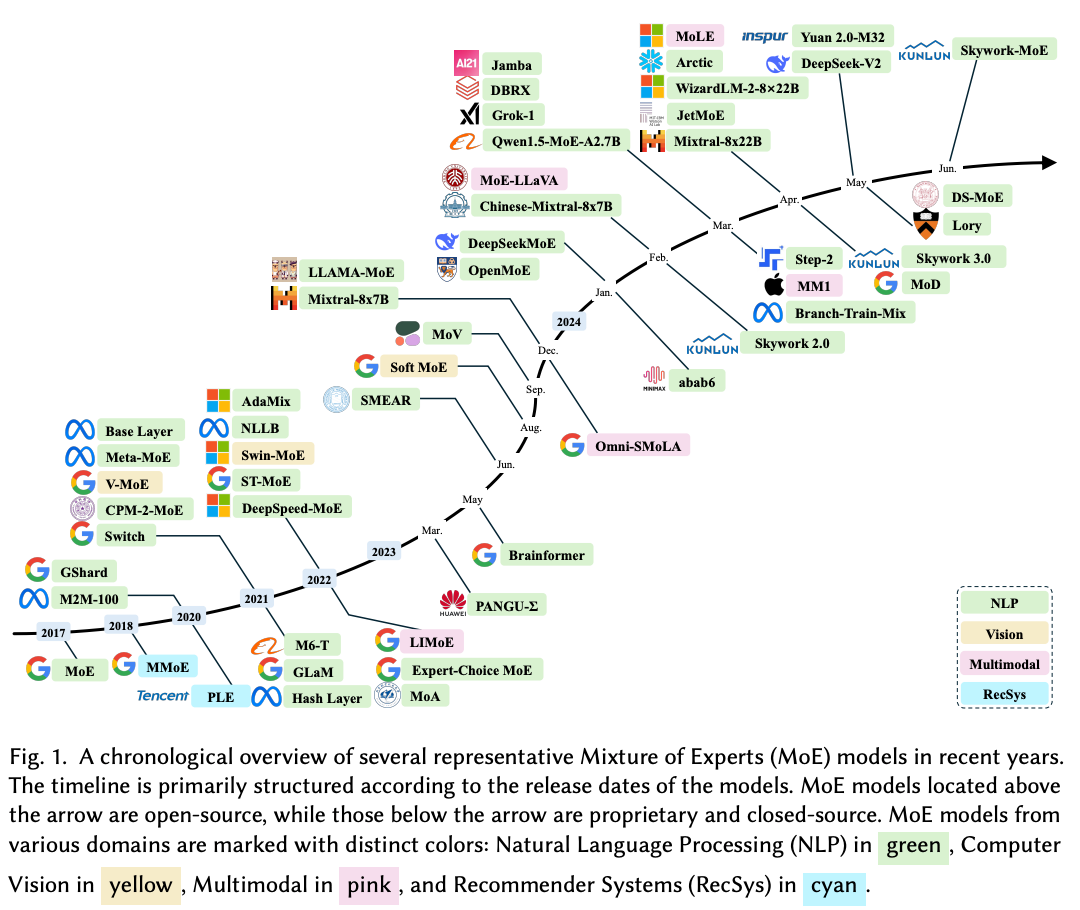
10.) A Survey on Mixture of Experts ( paper )
Large language models (LLMs) have garnered unprecedented advancements across diverse fields, ranging from natural language processing to computer vision and beyond. The prowess of LLMs is underpinned by their substantial model size, extensive and diverse datasets, and the vast computational power harnessed during training, all of which contribute to the emergent abilities of LLMs (e.g., in-context learning) that are not present in small models. Within this context, the mixture of experts (MoE) has emerged as an effective method for substantially scaling up model capacity with minimal computation overhead, gaining significant attention from academia and industry.
AIGC News of the week(July 08 - July 14)
1.) MobileLLM:Optimizing Sub-billion Parameter Language Models for On-Device Use Cases ( repo )
2.) SEED-Story: Multimodal Long Story Generation with Large Language Model ( repo )
3.) e2-tts-pytorch: Embarrassingly Easy Fully Non-Autoregressive Zero-Shot TTS ( repo )
4.) stabilityai/stable-audio-open-1.0 ( repo )
5.) Exclusive: OpenAI working on new reasoning technology under code name ‘Strawberry’ ( link )
more AIGC News: AINews