Top Papers of the week(July 01 - July 07)
1.) MInference 1.0: Accelerating Pre-filling for Long-Context LLMs via Dynamic Sparse Attention ( webpage | paper )
The computational challenges of Large Language Model (LLM) inference remain a significant barrier to their widespread deployment, especially as prompt lengths continue to increase. Due to the quadratic complexity of the attention computation, it takes 30 minutes for an 8B LLM to process a prompt of 1M tokens (i.e., the pre-filling stage) on a single A100 GPU. Existing methods for speeding up prefilling often fail to maintain acceptable accuracy or efficiency when applied to long-context LLMs. To address this gap, we introduce MInference (Milliontokens Inference), a sparse calculation method designed to accelerate pre-filling of long-sequence processing.
2.) Segment Anything without Supervision ( paper | code )
The Segmentation Anything Model (SAM) requires labor-intensive data labeling. We present Unsupervised SAM (UnSAM) for promptable and automatic whole-image segmentation that does not require human annotations. UnSAM utilizes a divide-and-conquer strategy to "discover" the hierarchical structure of visual scenes. We first leverage top-down clustering methods to partition an unlabeled image into instance/semantic level segments. For all pixels within a segment, a bottom-up clustering method is employed to iteratively merge them into larger groups, thereby forming a hierarchical structure.

3.) DisCo-Diff: Enhancing Continuous Diffusion Models with Discrete Latents ( webpage | paper )
Diffusion models (DMs) have revolutionized generative learning. They utilize a diffusion process to encode data into a simple Gaussian distribution. However, encoding a complex, potentially multimodal data distribution into a single continuous Gaussian distribution arguably represents an unnecessarily challenging learning problem. We propose Discrete-Continuous Latent Variable Diffusion Models (DisCo-Diff) to simplify this task by introducing complementary discrete latent variables. We augment DMs with learnable discrete latents, inferred with an encoder, and train DM and encoder end-to-end. DisCo-Diff does not rely on pre-trained networks, making the framework universally applicable.

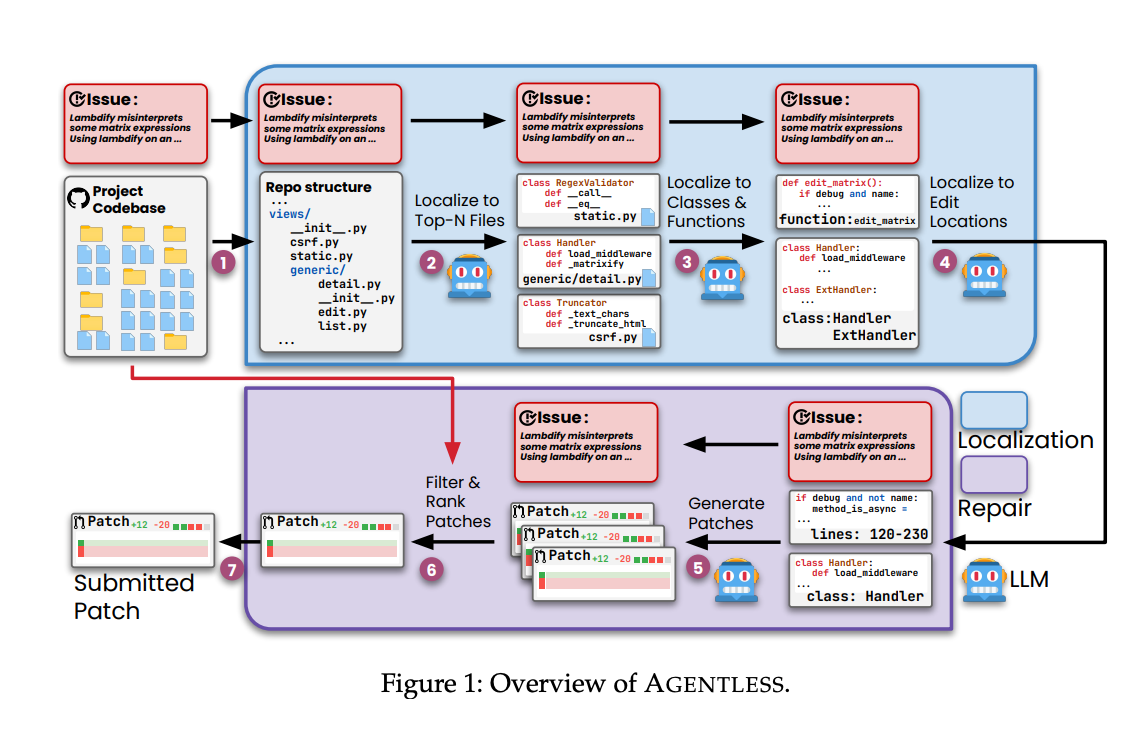
4.) Agentless: Demystifying LLM-based Software Engineering Agents ( paper )
Recent advancements in large language models (LLMs) have significantly advanced the automation of software development tasks, including code synthesis, program repair, and test generation. More recently, researchers and industry practitioners have developed various autonomous LLM agents to perform end-to-end software development tasks. These agents are equipped with the ability to use tools, run commands, observe feedback from the environment, and plan for future actions. However, the complexity of these agent-based approaches, together with the limited abilities of current LLMs, raises the following question: Do we really have to employ complex autonomous software agents? To attempt to answer this question, we build Agentless -- an agentless approach to automatically solve software development problems. Compared to the verbose and complex setup of agent-based approaches, Agentless employs a simplistic two-phase process of localization followed by repair, without letting the LLM decide future actions or operate with complex tools.
5.) Summary of a Haystack: A Challenge to Long-Context LLMs and RAG Systems ( paper )
LLMs and RAG systems are now capable of handling millions of input tokens or more. However, evaluating the output quality of such systems on long-context tasks remains challenging, as tasks like Needle-in-a-Haystack lack complexity. In this work, we argue that summarization can play a central role in such evaluation. We design a procedure to synthesize Haystacks of documents, ensuring that specific \textit{insights} repeat across documents. The "Summary of a Haystack" (SummHay) task then requires a system to process the Haystack and generate, given a query, a summary that identifies the relevant insights and precisely cites the source documents. Since we have precise knowledge of what insights should appear in a haystack summary and what documents should be cited, we implement a highly reproducible automatic evaluation that can score summaries on two aspects - Coverage and Citation.

6.) On scalable oversight with weak LLMs judging strong LLMs ( paper )
Scalable oversight protocols aim to enable humans to accurately supervise superhuman AI. In this paper we study debate, where two AI's compete to convince a judge; consultancy, where a single AI tries to convince a judge that asks questions; and compare to a baseline of direct question-answering, where the judge just answers outright without the AI. We use large language models (LLMs) as both AI agents and as stand-ins for human judges, taking the judge models to be weaker than agent models.

7.) LLM-Select: Feature Selection with Large Language Models ( paper )
In this paper, we demonstrate a surprising capability of large language models (LLMs): given only input feature names and a description of a prediction task, they are capable of selecting the most predictive features, with performance rivaling the standard tools of data science. Remarkably, these models exhibit this capacity across various query mechanisms.

8.) LLM See, LLM Do: Guiding Data Generation to Target Non-Differentiable Objectives ( paper )
The widespread adoption of synthetic data raises new questions about how models generating the data can influence other large language models (LLMs) via distilled data. To start, our work exhaustively characterizes the impact of passive inheritance of model properties by systematically studying the consequences of synthetic data integration. We provide one of the most comprehensive studies to-date of how the source of synthetic data shapes models' internal biases, calibration and generations' textual attributes and preferences. We find that models are surprisingly sensitive towards certain attributes even when the synthetic data prompts appear "neutral". which invites the question whether this sensitivity can be exploited for good.

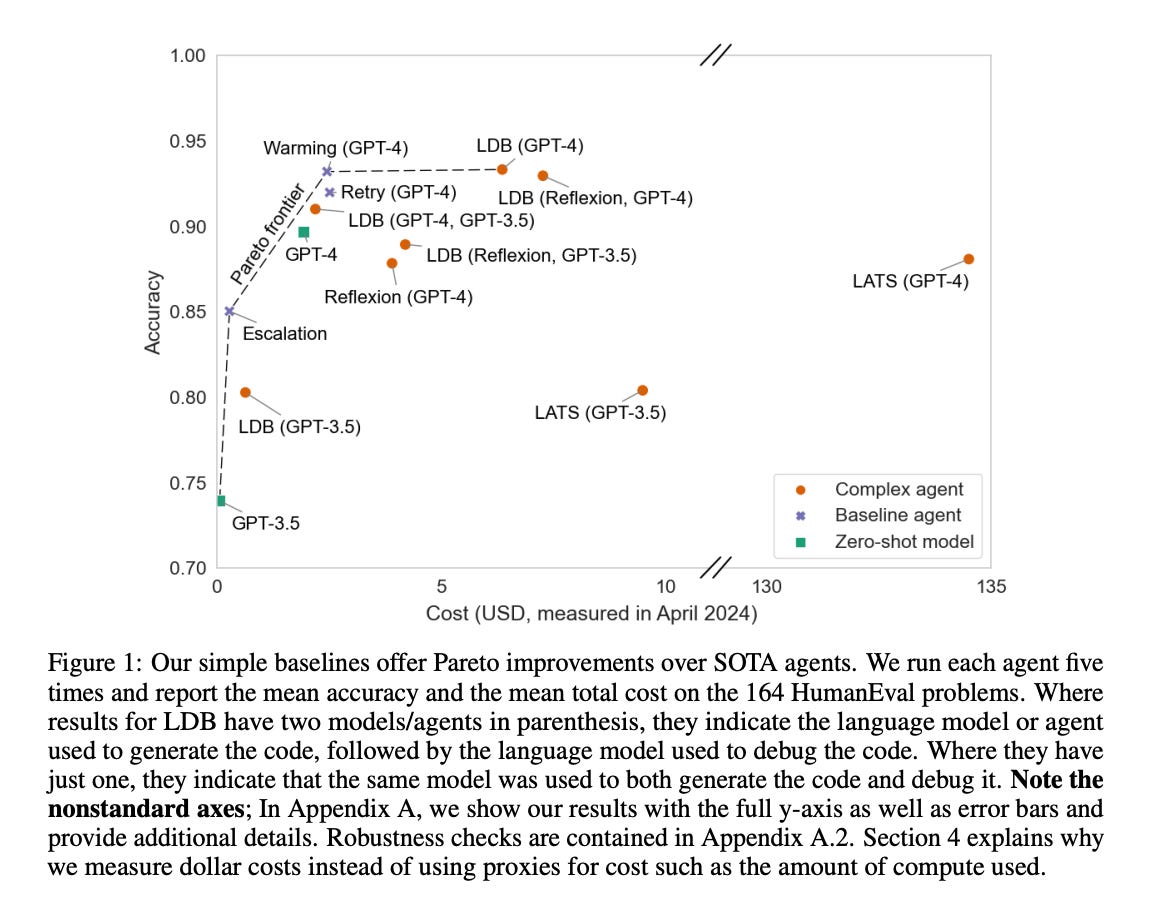
9.) AI Agents That Matter ( paper )
AI agents are an exciting new research direction, and agent development is driven by benchmarks. Our analysis of current agent benchmarks and evaluation practices reveals several shortcomings that hinder their usefulness in real-world applications. First, there is a narrow focus on accuracy without attention to other metrics. As a result, SOTA agents are needlessly complex and costly, and the community has reached mistaken conclusions about the sources of accuracy gains. Our focus on cost in addition to accuracy motivates the new goal of jointly optimizing the two metrics. We design and implement one such optimization, showing its potential to greatly reduce cost while maintaining accuracy.
10.) When Search Engine Services meet Large Language Models: Visions and Challenges ( paper )
Combining Large Language Models (LLMs) with search engine services marks a significant shift in the field of services computing, opening up new possibilities to enhance how we search for and retrieve information, understand content, and interact with internet services. This paper conducts an in-depth examination of how integrating LLMs with search engines can mutually benefit both technologies. We focus on two main areas: using search engines to improve LLMs (Search4LLM) and enhancing search engine functions using LLMs (LLM4Search).

AIGC News of the week(July 01 - July 07)
1.) LivePortrait:Make one portrait alive! ( repo | ComfyUI)

2.) Kolors: Effective Training of Diffusion Model for Photorealistic Text-to-Image Synthesis ( repo )

3.) CosyVoice: Multi-lingual large voice generation model, providing inference, training and deployment full-stack ability. ( repo )
4.) SenseVoice: Multilingual Voice Understanding Model ( repo )
5.) OmAgent: A multimodal agent framework for solving complex tasks ( repo )
more AIGC News: AINews