Top Papers of the week(Jun 24 - Jun 30)
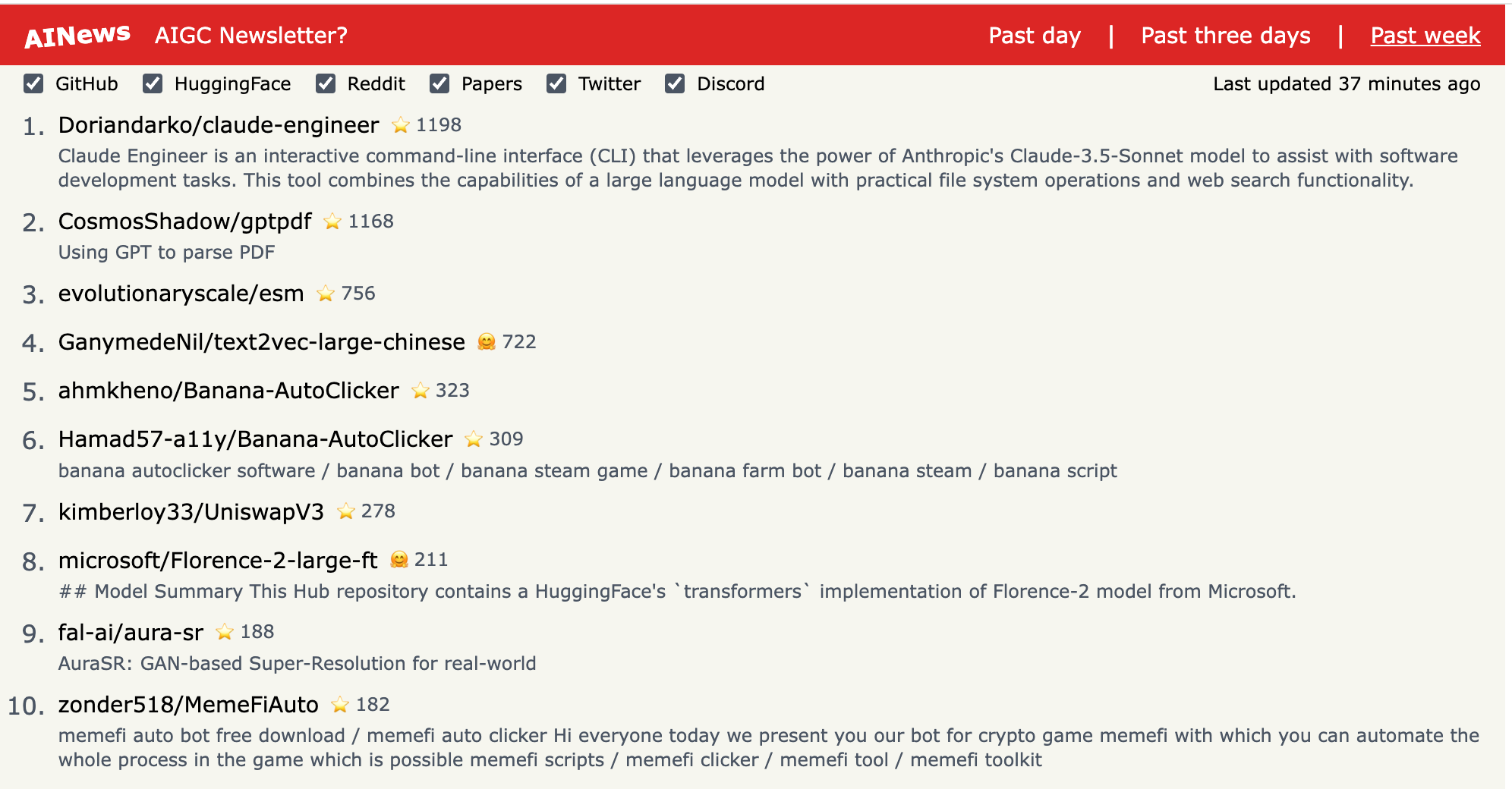
1.) Gemma 2: Improving Open Language Models at a Practical Size ( paper )
In this work, we introduce Gemma 2, a new addition to the Gemma family of lightweight, state-of-the-art open models, ranging in scale from 2 billion to 27 billion parameters. The 9 billion and 27 billion parameter models are available today, with a 2 billion parameter model to be released shortly.
2.) Meta Large Language Model Compiler: Foundation Models of Compiler Optimization ( webpage | paper )
Large Language Models (LLMs) have demonstrated remarkable capabilities across a variety of software engineering and coding tasks. However, their application in the domain of code and compiler optimization remains underexplored. Training LLMs is resource-intensive, requiring substantial GPU hours and extensive data collection, which can be prohibitive. To address this gap, we introduce Meta Large Language Model Compiler (LLM Compiler), a suite of robust, openly available, pre-trained models specifically designed for code optimization tasks.

3.) OpenAI: LLM Critics Help Catch LLM Bugs ( webpage | paper )
We've trained a model, based on GPT-4, called CriticGPT to catch errors in ChatGPT's code output. We found that when people get help from CriticGPT to review ChatGPT code they outperform those without help 60% of the time. We are beginning the work to integrate CriticGPT-like models into our RLHF labeling pipeline, providing our trainers with explicit AI assistance. This is a step towards being able to evaluate outputs from advanced AI systems that can be difficult for people to rate without better tools.

4.) Cambrian-1: A Fully Open, Vision-Centric Exploration of Multimodal LLMs ( paper | webpage )
We introduce Cambrian-1, a family of multimodal LLMs (MLLMs) designed with a vision-centric approach. While stronger language models can enhance multimodal capabilities, the design choices for vision components are often insufficiently explored and disconnected from visual representation learning research. This gap hinders accurate sensory grounding in real-world scenarios. Our study uses LLMs and visual instruction tuning as an interface to evaluate various visual representations, offering new insights into different models and architectures -- self-supervised, strongly supervised, or combinations thereof -- based on experiments with over 20 vision encoders.

5.) Video-Infinity: Distributed Long Video Generation ( paper )
Diffusion models have recently achieved remarkable results for video generation. Despite the encouraging performances, the generated videos are typically constrained to a small number of frames, resulting in clips lasting merely a few seconds. The primary challenges in producing longer videos include the substantial memory requirements and the extended processing time required on a single GPU. A straightforward solution would be to split the workload across multiple GPUs, which, however, leads to two issues: (1) ensuring all GPUs communicate effectively to share timing and context information, and (2) modifying existing video diffusion models, which are usually trained on short sequences, to create longer videos without additional training. To tackle these, in this paper we introduce Video-Infinity, a distributed inference pipeline that enables parallel processing across multiple GPUs for long-form video generation.

6.) On Scaling Up 3D Gaussian Splatting Training ( paper | code )
3D Gaussian Splatting (3DGS) is increasingly popular for 3D reconstruction due to its superior visual quality and rendering speed. However, 3DGS training currently occurs on a single GPU, limiting its ability to handle high-resolution and large-scale 3D reconstruction tasks due to memory constraints. We introduce Grendel, a distributed system designed to partition 3DGS parameters and parallelize computation across multiple GPUs.

7.) Large Language Models are Interpretable Learners ( paper )
The trade-off between expressiveness and interpretability remains a core challenge when building human-centric predictive models for classification and decision-making. While symbolic rules offer interpretability, they often lack expressiveness, whereas neural networks excel in performance but are known for being black boxes. In this paper, we show a combination of Large Language Models (LLMs) and symbolic programs can bridge this gap. In the proposed LLM-based Symbolic Programs (LSPs), the pretrained LLM with natural language prompts provides a massive set of interpretable modules that can transform raw input into natural language concepts. Symbolic programs then integrate these modules into an interpretable decision rule.

8.) Time Matters: Scaling Laws for Any Budget ( paper )
A primary cost driver for training large models is wall-clock training time. We show that popular time estimates based on FLOPs are poor estimates, and construct a more accurate proxy based on memory copies. We show that with some simple accounting, we can estimate the training speed of a transformer model from its hyperparameters. Combined with a scaling law curve like Chinchilla, this lets us estimate the final loss of the model. We fit our estimate to real data with a linear regression, and apply the result to rewrite Chinchilla in terms of a model's estimated training time as opposed to the amount of training data.

9.) RL on Incorrect Synthetic Data Scales the Efficiency of LLM Math Reasoning by Eight-Fold ( paper )
Training on model-generated synthetic data is a promising approach for finetuning LLMs, but it remains unclear when it helps or hurts. In this paper, we investigate this question for math reasoning via an empirical study, followed by building a conceptual understanding of our observations. First, we find that while the typical approach of finetuning a model on synthetic correct or positive problem-solution pairs generated by capable models offers modest performance gains, sampling more correct solutions from the finetuned learner itself followed by subsequent fine-tuning on this self-generated data doubles the efficiency of the same synthetic problems. At the same time, training on model-generated positives can amplify various spurious correlations, resulting in flat or even inverse scaling trends as the amount of data increases.

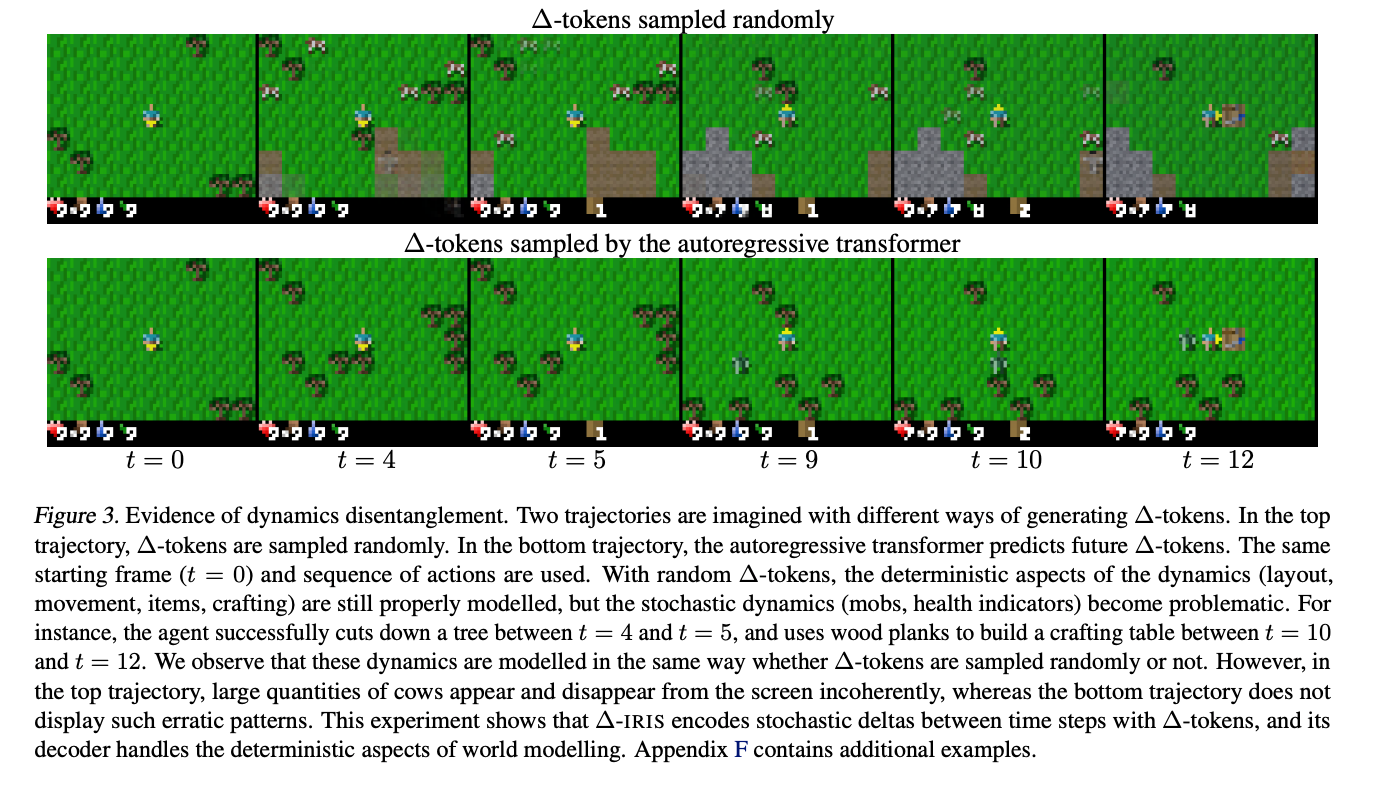
10.) Efficient World Models with Context-Aware Tokenization ( paper | code )
Scaling up deep Reinforcement Learning (RL) methods presents a significant challenge. Following developments in generative modelling, model-based RL positions itself as a strong contender. Recent advances in sequence modelling have led to effective transformer-based world models, albeit at the price of heavy computations due to the long sequences of tokens required to accurately simulate environments. In this work, we propose Δ-IRIS, a new agent with a world model architecture composed of a discrete autoencoder that encodes stochastic deltas between time steps and an autoregressive transformer that predicts future deltas by summarizing the current state of the world with continuous tokens.
other papers:
Simulating 500 million years of evolution with a language model ( paper )
From Artificial Needles to Real Haystacks: Improving Retrieval Capabilities in LLMs by Finetuning on Synthetic Data ( paper )
Scaling Synthetic Data Creation with 1,000,000,000 Personas ( paper )
On LLMs-Driven Synthetic Data Generation, Curation, and Evaluation: A Survey ( paper )
AIGC News of the week(Jun 24 - Jun 30)
1.) gptpdf: Using GPT to parse PDF ( link )
2.) claude-engineer:an interactive command-line interface (CLI) that leverages the power of Anthropic's Claude-3.5-Sonnet model to assist with software development tasks. ( repo )
3.) AuraSR: GAN-based Super-Resolution for real-world ( repo )
4.) SkyPilot: Run LLMs, AI, and Batch jobs on any cloud. ( repo )
5.) unet.cu: UNet diffusion model in pure CUDA ( repo )
more AIGC News: AINews