Top Papers of the week(Jun 17 - Jun 23)
1.) Claude 3.5 Sonnet ( webpage )
we’re launching Claude 3.5 Sonnet—our first release in the forthcoming Claude 3.5 model family. Claude 3.5 Sonnet raises the industry bar for intelligence, outperforming competitor models and Claude 3 Opus on a wide range of evaluations, with the speed and cost of our mid-tier model, Claude 3 Sonnet.

2.) DeepSeek-Coder-V2: Breaking the Barrier of Closed-Source Models in Code Intelligence ( paper | code )
We present DeepSeek-Coder-V2, an open-source Mixture-of-Experts (MoE) code language model that achieves performance comparable to GPT4-Turbo in code-specific tasks. Specifically, DeepSeek-Coder-V2 is further pre-trained from an intermediate checkpoint of DeepSeek-V2 with additional 6 trillion tokens. Through this continued pre-training, DeepSeek-Coder-V2 substantially enhances the coding and mathematical reasoning capabilities of DeepSeek-V2, while maintaining comparable performance in general language tasks. Compared to DeepSeek-Coder-33B, DeepSeek-Coder-V2 demonstrates significant advancements in various aspects of code-related tasks, as well as reasoning and general capabilities. Additionally, DeepSeek-Coder-V2 expands its support for programming languages from 86 to 338, while extending the context length from 16K to 128K.

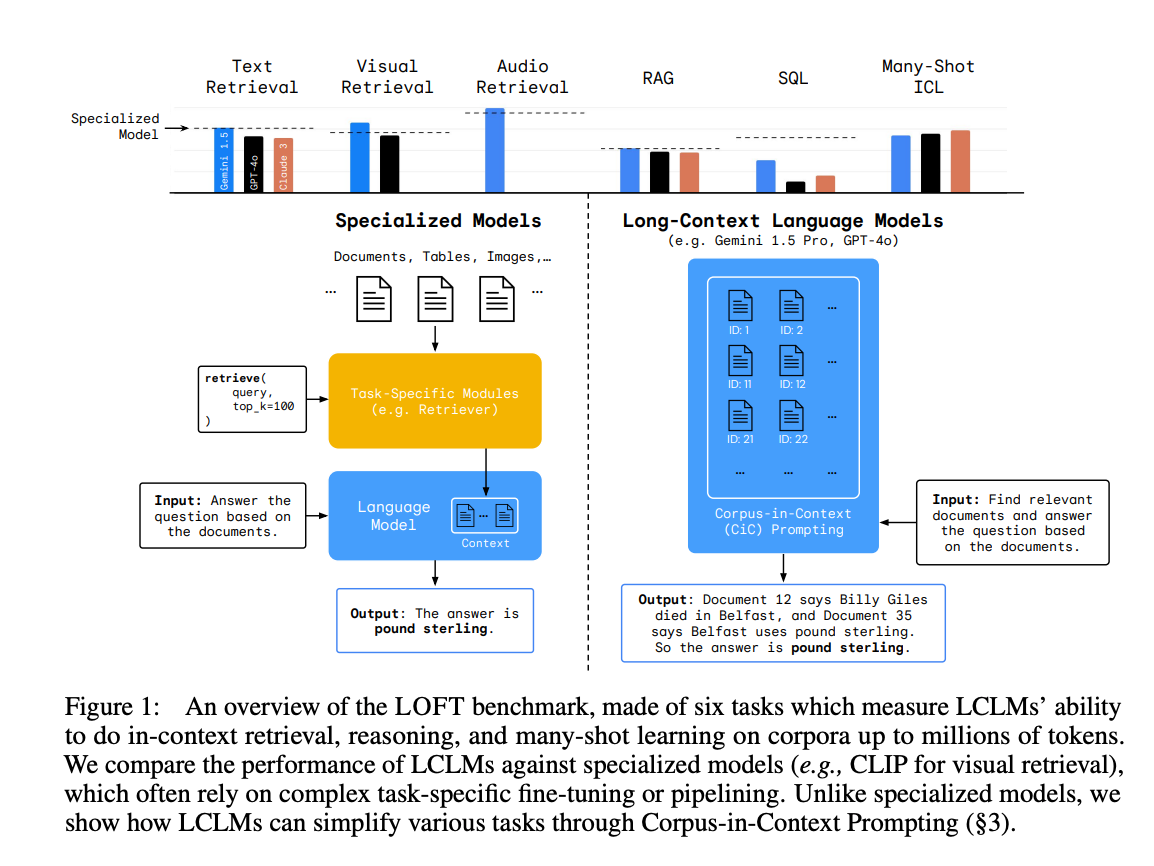
3.) Can Long-Context Language Models Subsume Retrieval, RAG, SQL, and More? ( paper | repo )
Long-context language models (LCLMs) have the potential to revolutionize our approach to tasks traditionally reliant on external tools like retrieval systems or databases. Leveraging LCLMs' ability to natively ingest and process entire corpora of information offers numerous advantages. It enhances user-friendliness by eliminating the need for specialized knowledge of tools, provides robust end-to-end modeling that minimizes cascading errors in complex pipelines, and allows for the application of sophisticated prompting techniques across the entire system.
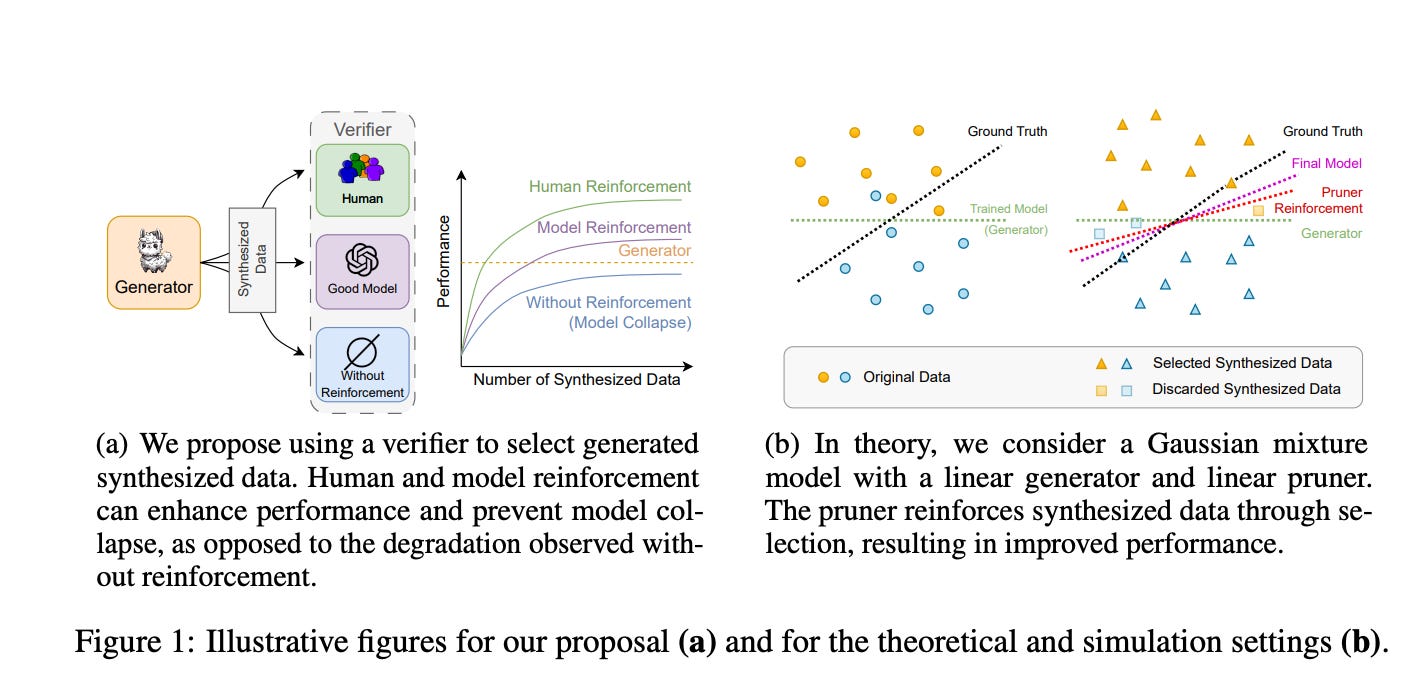
4.) Beyond Model Collapse: Scaling Up with Synthesized Data Requires Reinforcement ( paper )
Synthesized data from generative models is increasingly considered as an alternative to human-annotated data for fine-tuning Large Language Models. This raises concerns about model collapse: a drop in performance of models fine-tuned on generated data. Considering that it is easier for both humans and machines to tell between good and bad examples than to generate high-quality samples, we investigate the use of feedback on synthesized data to prevent model collapse.
5.) Transcendence: Generative Models Can Outperform The Experts That Train Them ( paper )
Generative models are trained with the simple objective of imitating the conditional probability distribution induced by the data they are trained on. Therefore, when trained on data generated by humans, we may not expect the artificial model to outperform the humans on their original objectives. In this work, we study the phenomenon of transcendence: when a generative model achieves capabilities that surpass the abilities of the experts generating its data.
6.) Language Modeling with Editable External Knowledge ( paper | code )
When the world changes, so does the text that humans write about it. How do we build language models that can be easily updated to reflect these changes? One popular approach is retrieval-augmented generation, in which new documents are inserted into a knowledge base and retrieved during prediction for downstream tasks. Most prior work on these systems have focused on improving behavior during prediction through better retrieval or reasoning. This paper introduces ERASE, which instead improves model behavior when new documents are acquired, by incrementally deleting or rewriting other entries in the knowledge base each time a document is added.

7.) VIA: A Spatiotemporal Video Adaptation Framework for Global and Local Video Editing ( webpage | paper )
Video editing stands as a cornerstone of digital media, from entertainment and education to professional communication. However, previous methods often overlook the necessity of comprehensively understanding both global and local contexts, leading to inaccurate and inconsistency edits in the spatiotemporal dimension, especially for long videos. In this paper, we introduce VIA, a unified spatiotemporal VIdeo Adaptation framework for global and local video editing, pushing the limits of consistently editing minute-long videos.
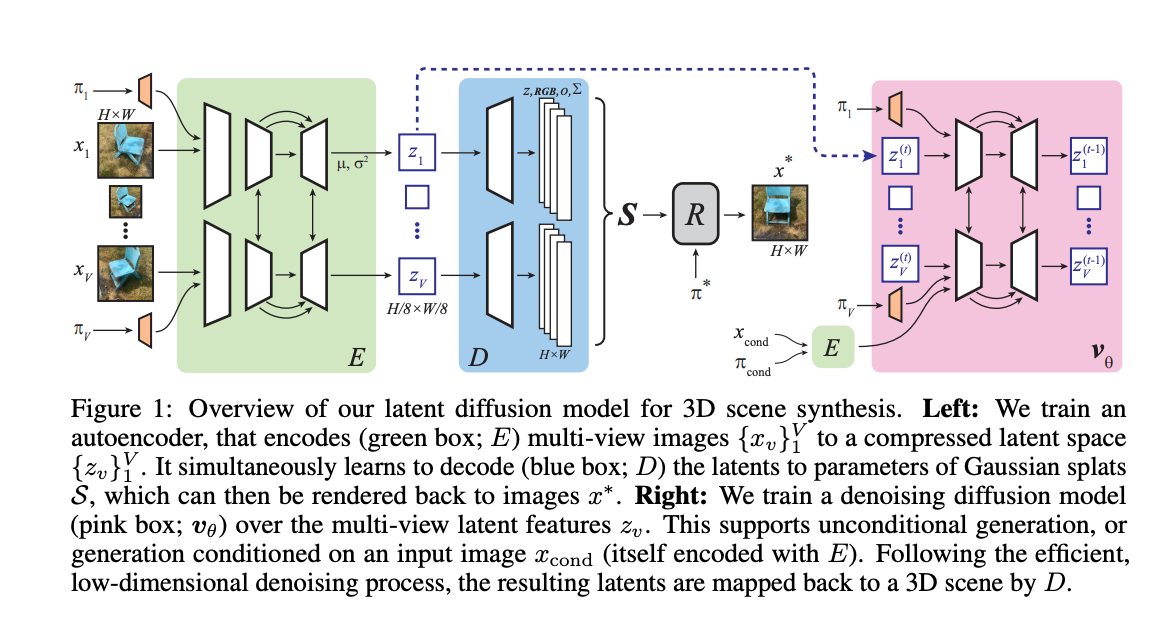
8.) Sampling 3D Gaussian Scenes in Seconds with Latent Diffusion Models ( paper )
We present a latent diffusion model over 3D scenes, that can be trained using only 2D image data. To achieve this, we first design an autoencoder that maps multi-view images to 3D Gaussian splats, and simultaneously builds a compressed latent representation of these splats. Then, we train a multi-view diffusion model over the latent space to learn an efficient generative model. This pipeline does not require object masks nor depths, and is suitable for complex scenes with arbitrary camera positions.
9.) Consistency-diversity-realism Pareto fronts of conditional image generative models ( paper )
Building world models that accurately and comprehensively represent the real world is the utmost aspiration for conditional image generative models as it would enable their use as world simulators. For these models to be successful world models, they should not only excel at image quality and prompt-image consistency but also ensure high representation diversity. However, current research in generative models mostly focuses on creative applications that are predominantly concerned with human preferences of image quality and aesthetics.

10.) Pandora: Towards General World Model with Natural Language Actions and Video States ( webpage | paper )
World models simulate future states of the world in response to different actions. They facilitate interactive content creation and provides a foundation for grounded, long-horizon reasoning. Current foundation models do not fully meet the capabilities of general world models: large language models (LLMs) are constrained by their reliance on language modality and their limited understanding of the physical world, while video models lack interactive action control over the world simulations. This paper makes a step towards building a general world model by introducing Pandora, a hybrid autoregressive-diffusion model that simulates world states by generating videos and allows real-time control with free-text actions.
AIGC News of the week(Jun 17 - Jun 23)
1.) Meta Chameleon:a mixed-modal early-fusion foundation model from FAIR ( repo )
2.) Perplexica: is an AI-powered search engine. It is an Open source alternative to Perplexity AI ( repo )
3.) Optimizing AI Inference at Character.AI ( link )
4.) Yousim: an LLM game( link )
5.) Ilya Sutskever: starting a new company: SSI Inc ( link )
more AIGC News: AINews