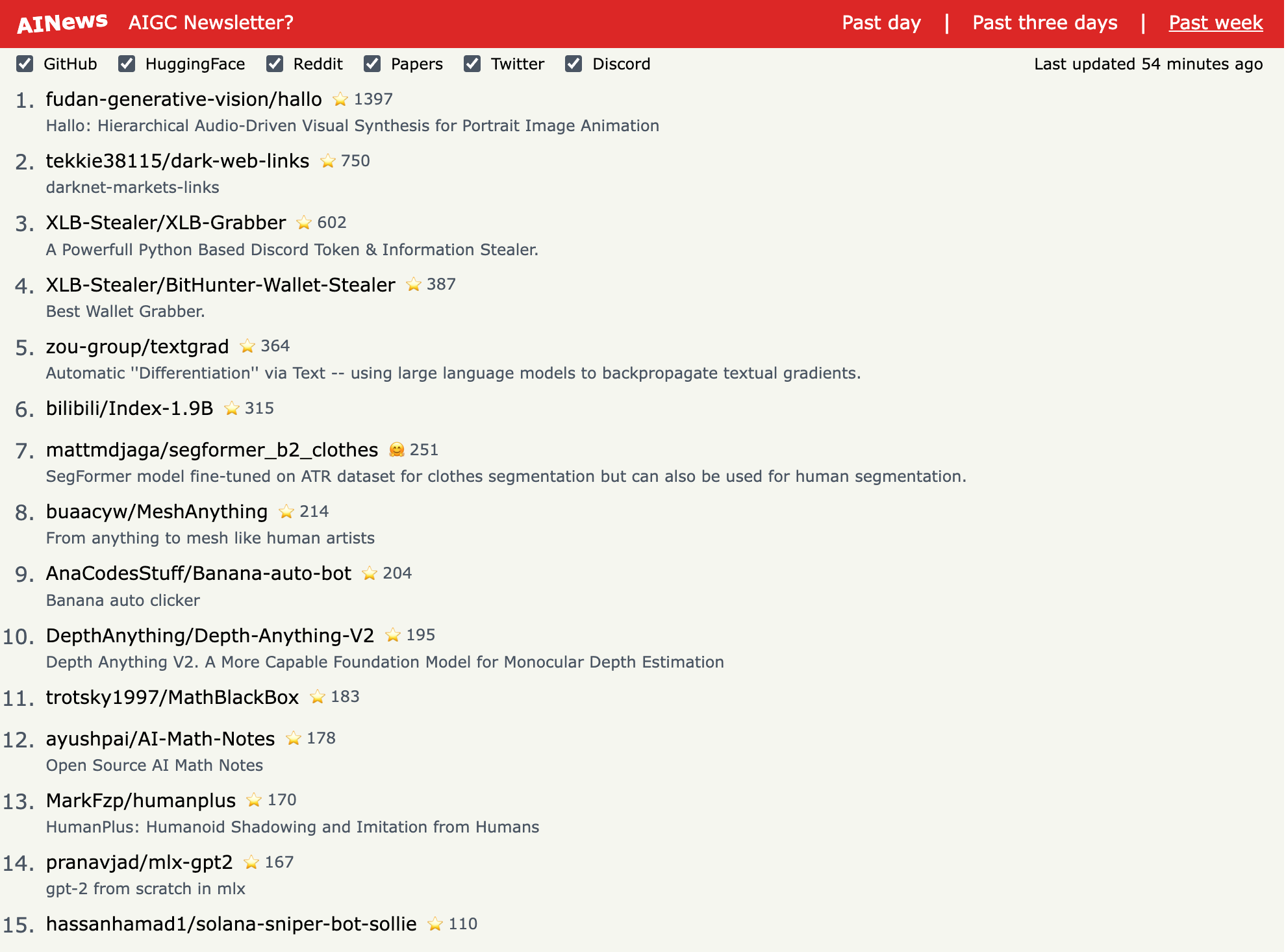
Top Papers of the week(Jun 10 - Jun 16)
1.) Nvidia: Nemotron-4 340B ( webpage | model | Technical Report )
Nvidia has released an open-source toolkit for generating synthetic data to train Large Language Models (LLMs). This new series of models, Nemotron-4 340B, offers a free and scalable solution to a significant challenge in AI development: the scarcity of high-quality, readily accessible training data. Nemotron-4 340B models not only produce synthetic data but also evaluate its quality to build robust and reliable Large Language Models.
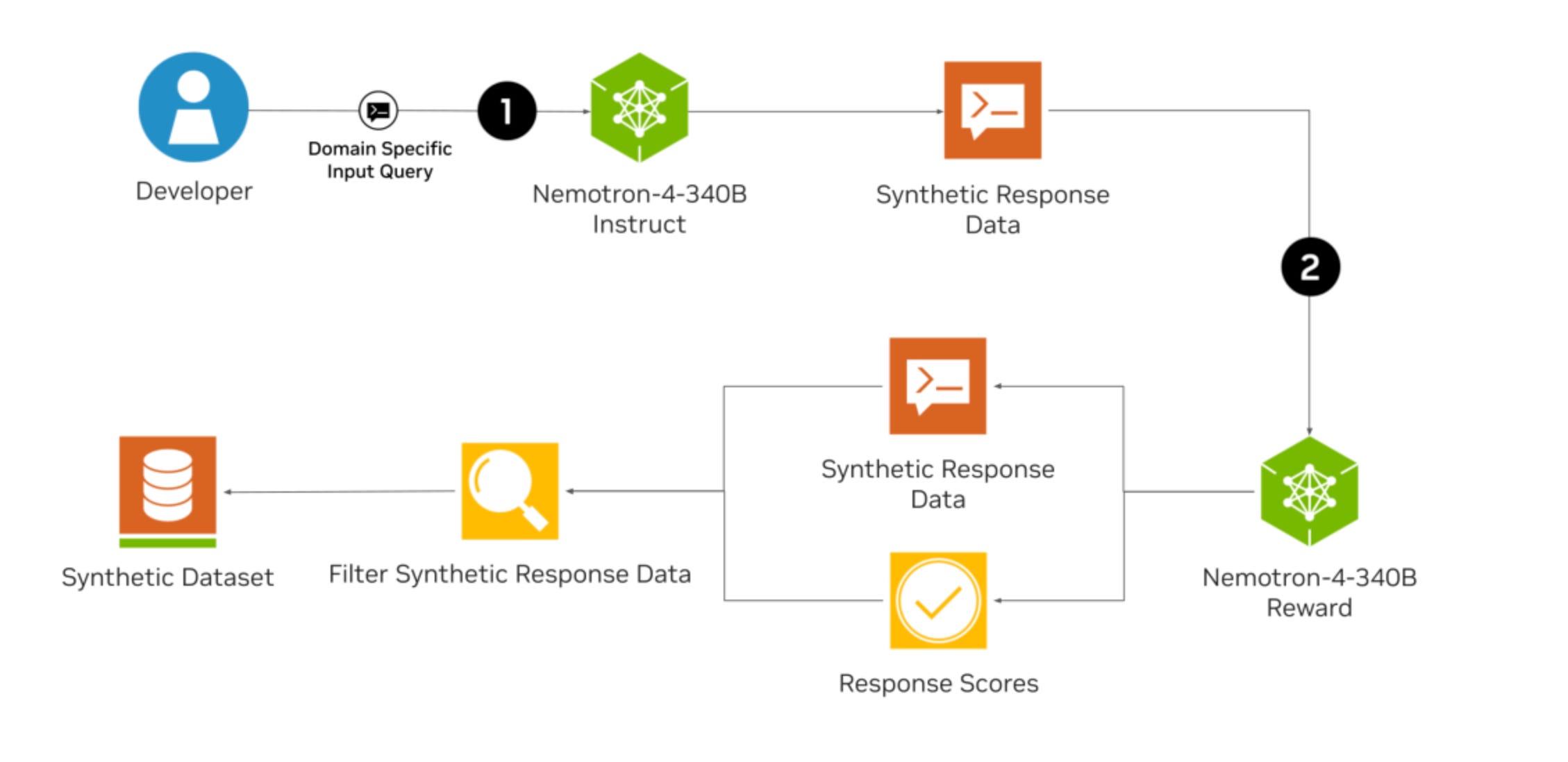
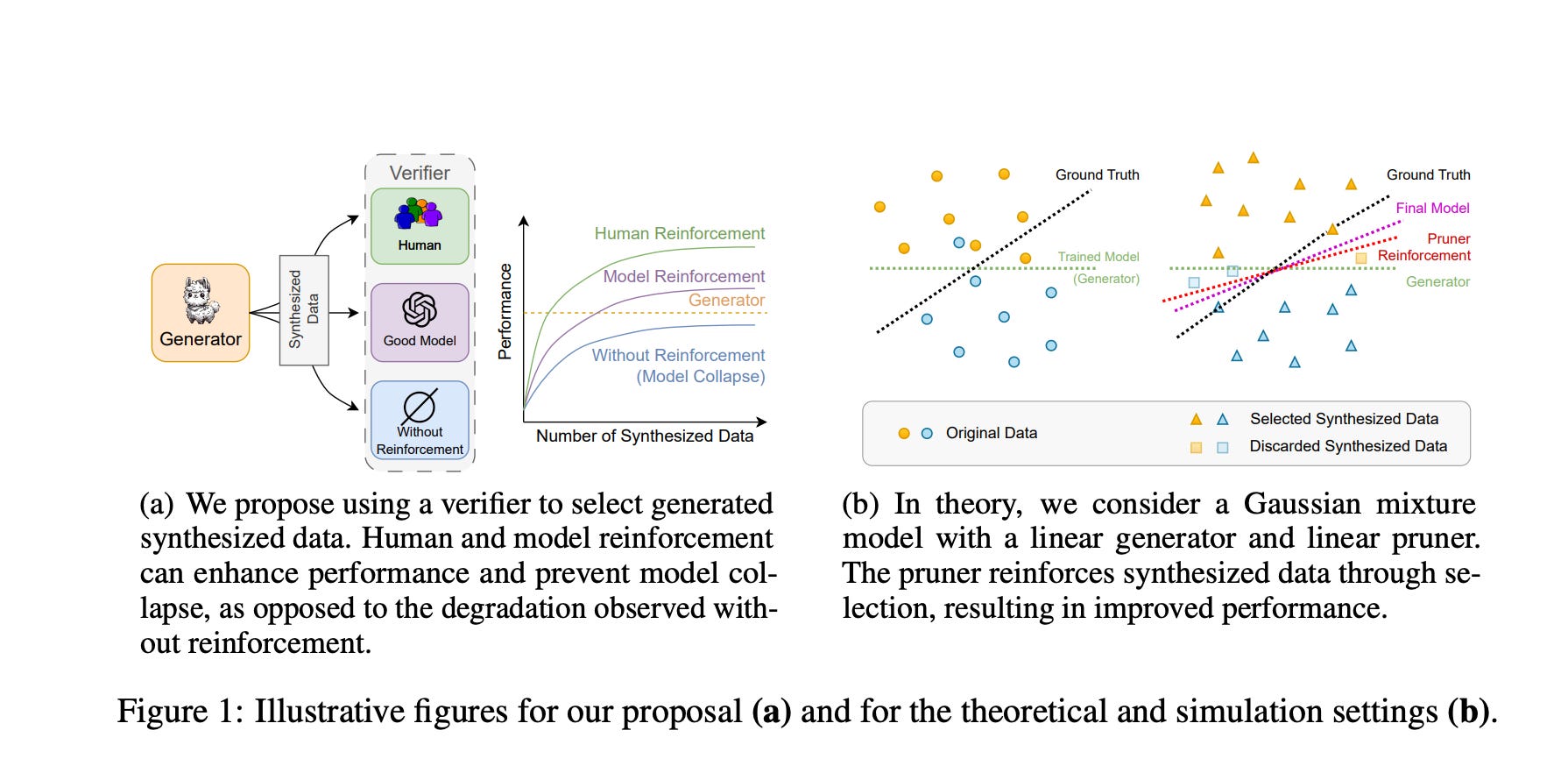
2.) Beyond Model Collapse: Scaling Up with Synthesized Data Requires Reinforcement ( paper )
Synthesized data from generative models is increasingly considered as an alternative to human-annotated data for fine-tuning Large Language Models. This raises concerns about model collapse: a drop in performance of models fine-tuned on generated data. Considering that it is easier for both humans and machines to tell between good and bad examples than to generate high-quality samples, we investigate the use of feedback on synthesized data to prevent model collapse. We derive theoretical conditions under which a Gaussian mixture classification model can achieve asymptotically optimal performance when trained on feedback-augmented synthesized data, and provide supporting simulations for finite regimes.
3.) MATES: Model-Aware Data Selection for Efficient Pretraining with Data Influence Models ( paper | code )
Pretraining data selection has the potential to improve language model pretraining efficiency by utilizing higher-quality data from massive web data corpora. Current data selection methods, which rely on either hand-crafted rules or larger reference models, are conducted statically and do not capture the evolving data preferences during pretraining. In this paper, we introduce model-aware data selection with data influence models (MATES), where a data influence model continuously adapts to the evolving data preferences of the pretraining model and then selects the data most effective for the current pretraining progress. Specifically, we fine-tune a small data influence model to approximate oracle data preference signals collected by locally probing the pretraining model and to select data accordingly for the next pretraining stage.

4.) LLM Dataset Inference: Did you train on my dataset? ( paper | code )
The proliferation of large language models (LLMs) in the real world has come with a rise in copyright cases against companies for training their models on unlicensed data from the internet. Recent works have presented methods to identify if individual text sequences were members of the model's training data, known as membership inference attacks (MIAs). We demonstrate that the apparent success of these MIAs is confounded by selecting non-members (text sequences not used for training) belonging to a different distribution from the members (e.g., temporally shifted recent Wikipedia articles compared with ones used to train the model).

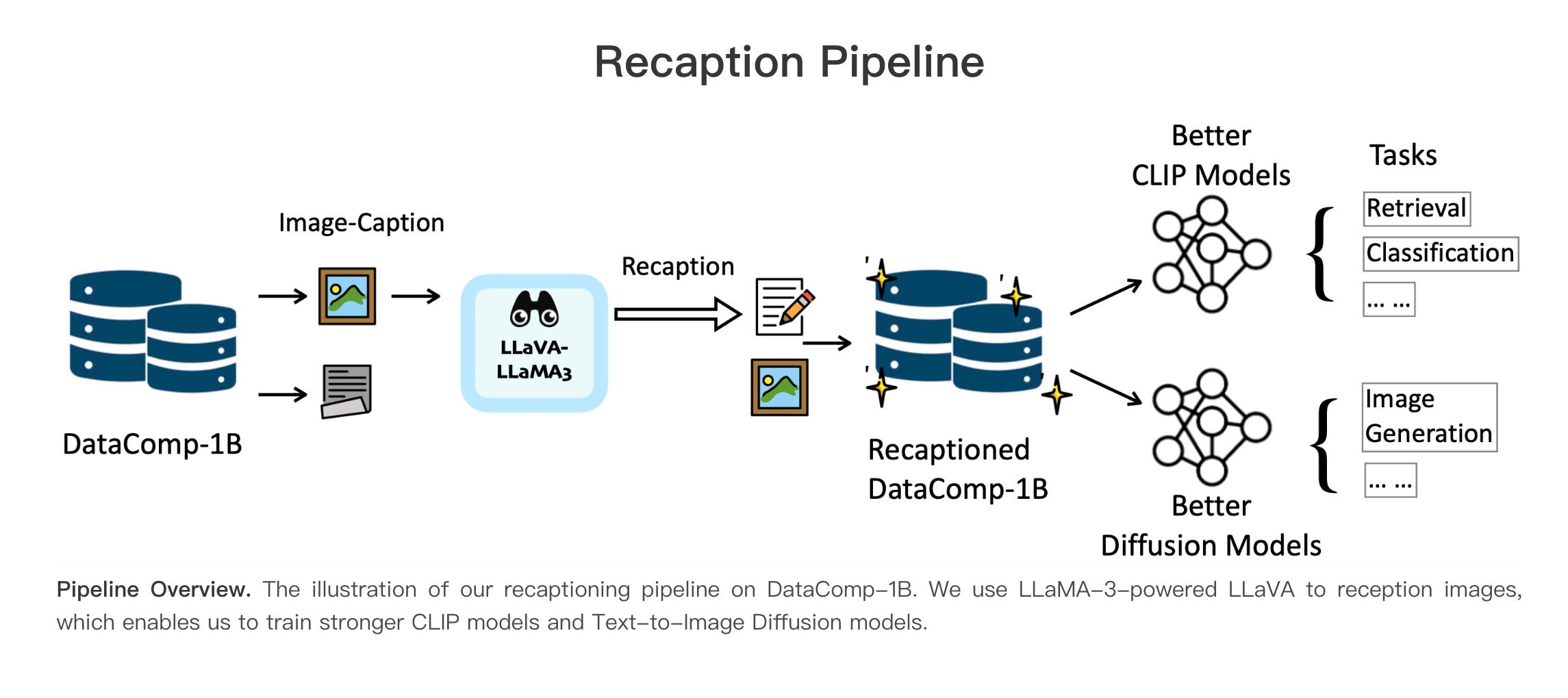
5.) What If We Recaption Billions of Web Images with LLaMA-3? ( webpage | paper )
Web-crawled image-text pairs are inherently noisy. Prior studies demonstrate that semantically aligning and enriching textual descriptions of these pairs can significantly enhance model training across various vision-language tasks, particularly text-to-image generation. However, large-scale investigations in this area remain predominantly closed-source. Our paper aims to bridge this community effort, leveraging the powerful and \textit{open-sourced} LLaMA-3, a GPT-4 level LLM.
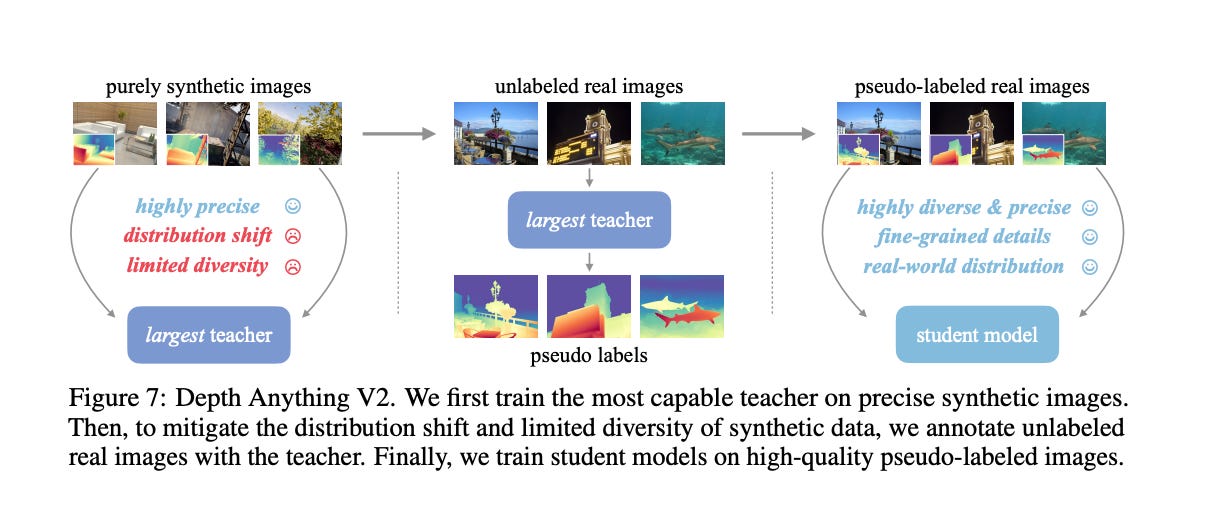
6.) Depth Anything V2 ( paper )
This work presents Depth Anything V2. Without pursuing fancy techniques, we aim to reveal crucial findings to pave the way towards building a powerful monocular depth estimation model. Notably, compared with V1, this version produces much finer and more robust depth predictions through three key practices: 1) replacing all labeled real images with synthetic images, 2) scaling up the capacity of our teacher model, and 3) teaching student models via the bridge of large-scale pseudo-labeled real images. Compared with the latest models built on Stable Diffusion, our models are significantly more efficient (more than 10x faster) and more accurate. We offer models of different scales (ranging from 25M to 1.3B params) to support extensive scenarios.
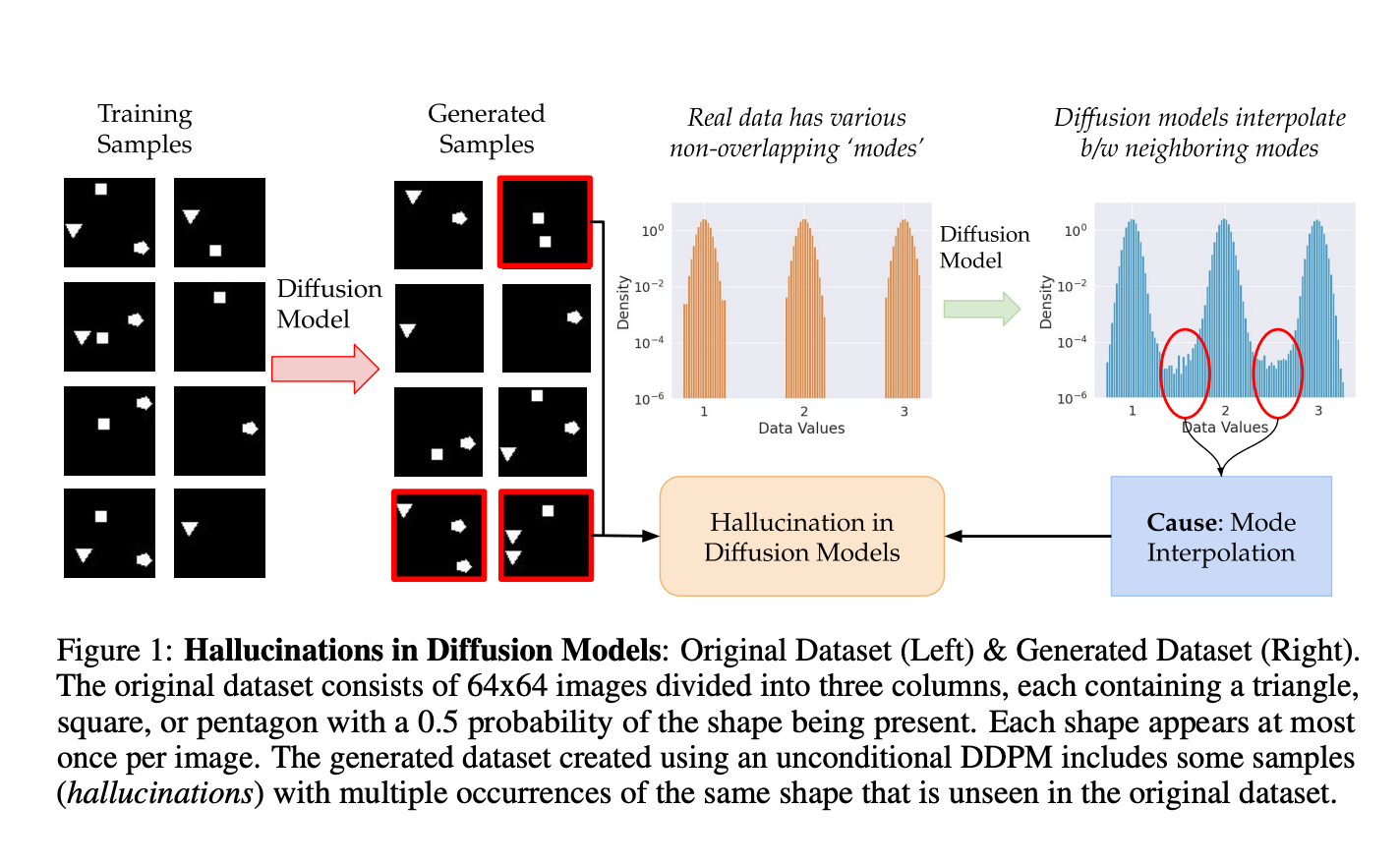
7.) Understanding Hallucinations in Diffusion Models through Mode Interpolation ( paper )
Colloquially speaking, image generation models based upon diffusion processes are frequently said to exhibit "hallucinations," samples that could never occur in the training data. But where do such hallucinations come from? In this paper, we study a particular failure mode in diffusion models, which we term mode interpolation. Specifically, we find that diffusion models smoothly "interpolate" between nearby data modes in the training set, to generate samples that are completely outside the support of the original training distribution; this phenomenon leads diffusion models to generate artifacts that never existed in real data (i.e., hallucinations).
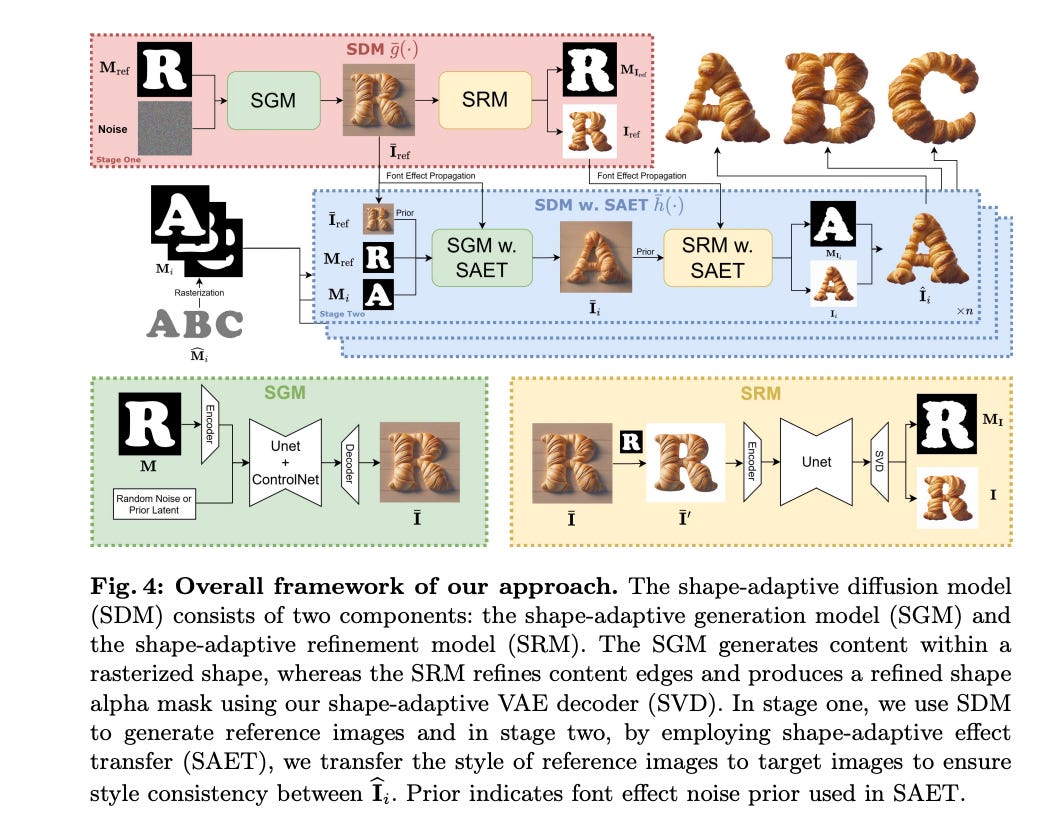
8.) FontStudio: Shape-Adaptive Diffusion Model for Coherent and Consistent Font Effect Generation ( webpage | paper )
Recently, the application of modern diffusion-based text-to-image generation models for creating artistic fonts, traditionally the domain of professional designers, has garnered significant interest. Diverging from the majority of existing studies that concentrate on generating artistic typography, our research aims to tackle a novel and more demanding challenge: the generation of text effects for multilingual fonts. This task essentially requires generating coherent and consistent visual content within the confines of a font-shaped canvas, as opposed to a traditional rectangular canvas. To address this task, we introduce a novel shape-adaptive diffusion model capable of interpreting the given shape and strategically planning pixel distributions within the irregular canvas.
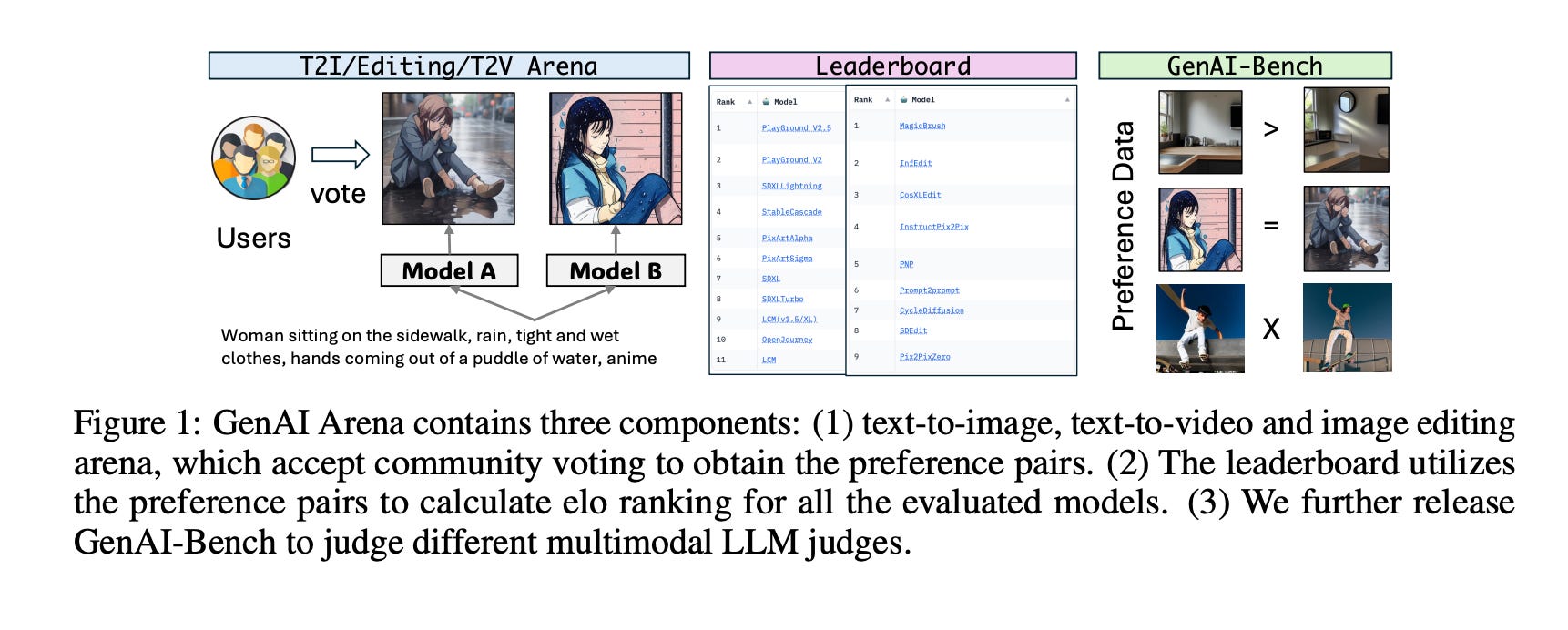
9.) GenAI Arena: An Open Evaluation Platform for Generative Models ( paper | space )
Generative AI has made remarkable strides to revolutionize fields such as image and video generation. These advancements are driven by innovative algorithms, architecture, and data. However, the rapid proliferation of generative models has highlighted a critical gap: the absence of trustworthy evaluation metrics. Current automatic assessments such as FID, CLIP, FVD, etc often fail to capture the nuanced quality and user satisfaction associated with generative outputs. This paper proposes an open platform GenAI-Arena to evaluate different image and video generative models, where users can actively participate in evaluating these models.
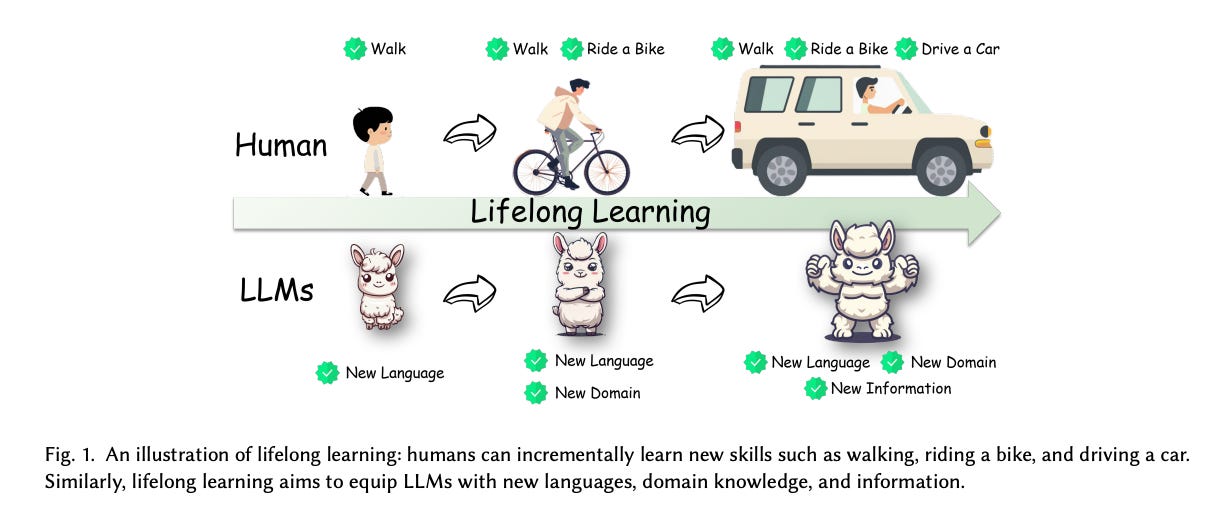
10.) Towards Lifelong Learning of Large Language Models: A Survey ( paper )
As the applications of large language models (LLMs) expand across diverse fields, the ability of these models to adapt to ongoing changes in data, tasks, and user preferences becomes crucial. Traditional training methods, relying on static datasets, are increasingly inadequate for coping with the dynamic nature of real-world information. Lifelong learning, also known as continual or incremental learning, addresses this challenge by enabling LLMs to learn continuously and adaptively over their operational lifetime, integrating new knowledge while retaining previously learned information and preventing catastrophic forgetting. This survey delves into the sophisticated landscape of lifelong learning, categorizing strategies into two primary groups: Internal Knowledge and External Knowledge. Internal Knowledge includes continual pretraining and continual finetuning, each enhancing the adaptability of LLMs in various scenarios.
Other papers:
Magpie: Alignment Data Synthesis from Scratch by Prompting Aligned LLMs with Nothing( paper )
Simple and Effective Masked Diffusion Language Models ( paper | code )
SELF-TUNING: Instructing LLMs to Effectively Acquire New Knowledge through Self-Teaching ( paper )
AIGC News of the week(Jun 10 - Jun 16)
1.) Luma Labs has released Dream Machine, a new AI video model that lets you create realistic videos from text descriptions and images ( link )
2.) Stable Diffusion 3 Medium Open Release ( webpage | model )

3.) LayerDiffuse_DiffusersCLI: LayerDiffuse in pure diffusers without any GUI ( repo )
4.) GPT from Scratch with MLX:Define and train GPT-2 on your MacBook( link )
5.) awesome-llm-apps ( repo )
more AIGC News: AINews