Top Papers of the week(MAY 6 - MAY 12)
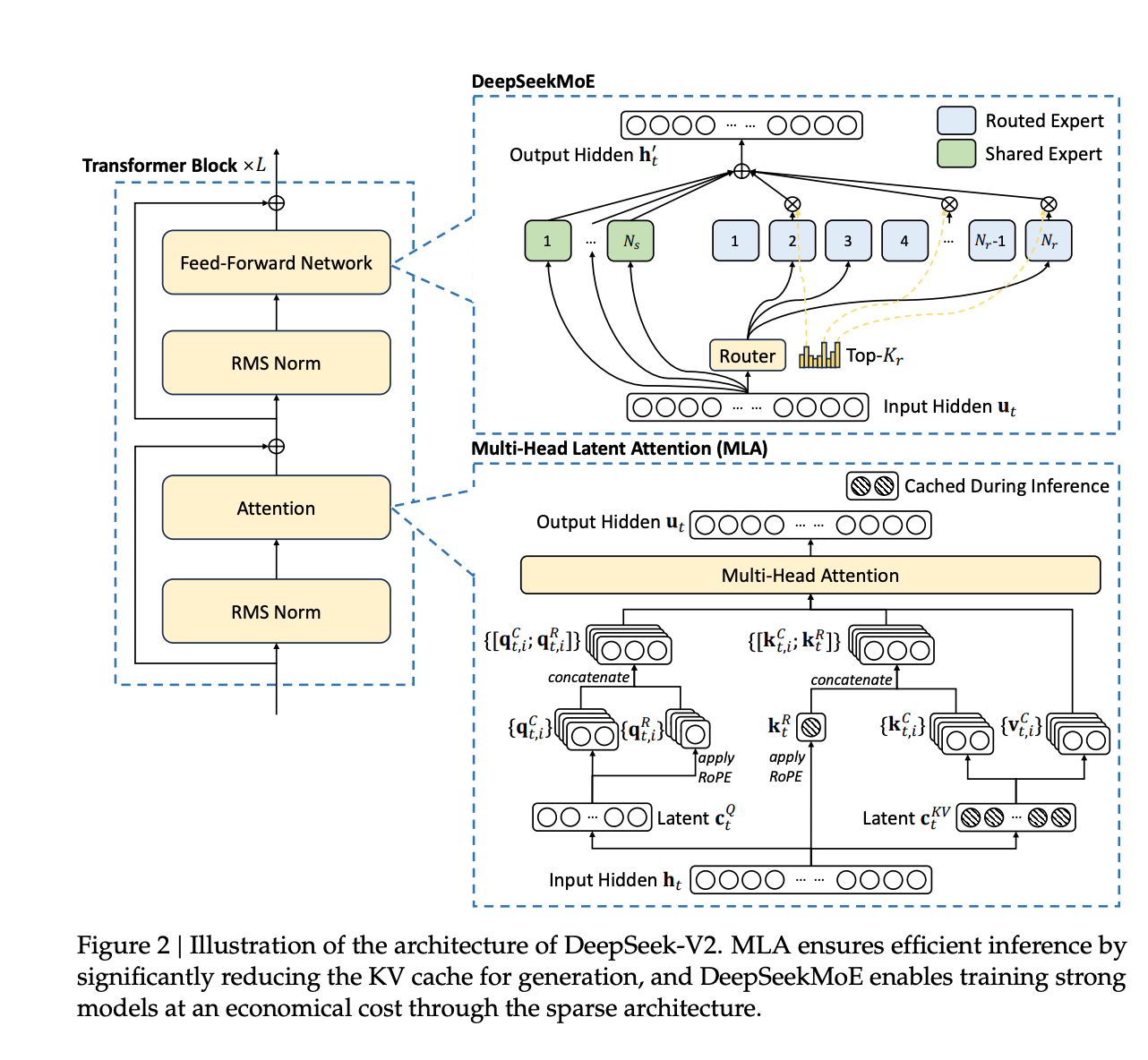
1.) DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model ( paper | model )
We present DeepSeek-V2, a strong Mixture-of-Experts (MoE) language model characterized by economical training and efficient inference. It comprises 236B total parameters, of which 21B are activated for each token, and supports a context length of 128K tokens. DeepSeek-V2 adopts innovative architectures including Multi-head Latent Attention (MLA) and DeepSeekMoE. MLA guarantees efficient inference through significantly compressing the Key-Value (KV) cache into a latent vector, while DeepSeekMoE enables training strong models at an economical cost through sparse computation.
2.) Accurate structure prediction of biomolecular interactions with AlphaFold 3 ( webpage | paper )
The introduction of AlphaFold 21 has spurred a revolution in modelling the structure of proteins and their interactions, enabling a huge range of applications in protein modelling and design2–6. In this paper, we describe our AlphaFold 3 model with a substantially updated diffusion-based architecture, which is capable of joint structure prediction of complexes including proteins, nucleic acids, small molecules, ions, and modified residues. The new AlphaFold model demonstrates significantly improved accuracy over many previous specialised tools: far greater accuracy on protein-ligand interactions than state of the art docking tools, much higher accuracy on protein-nucleic acid interactions than nucleic-acid-specific predictors, and significantly higher antibody-antigen prediction accuracy than AlphaFold-Multimer v2.37,8. Together these results show that high accuracy modelling across biomolecular space is possible within a single unified deep learning framework.

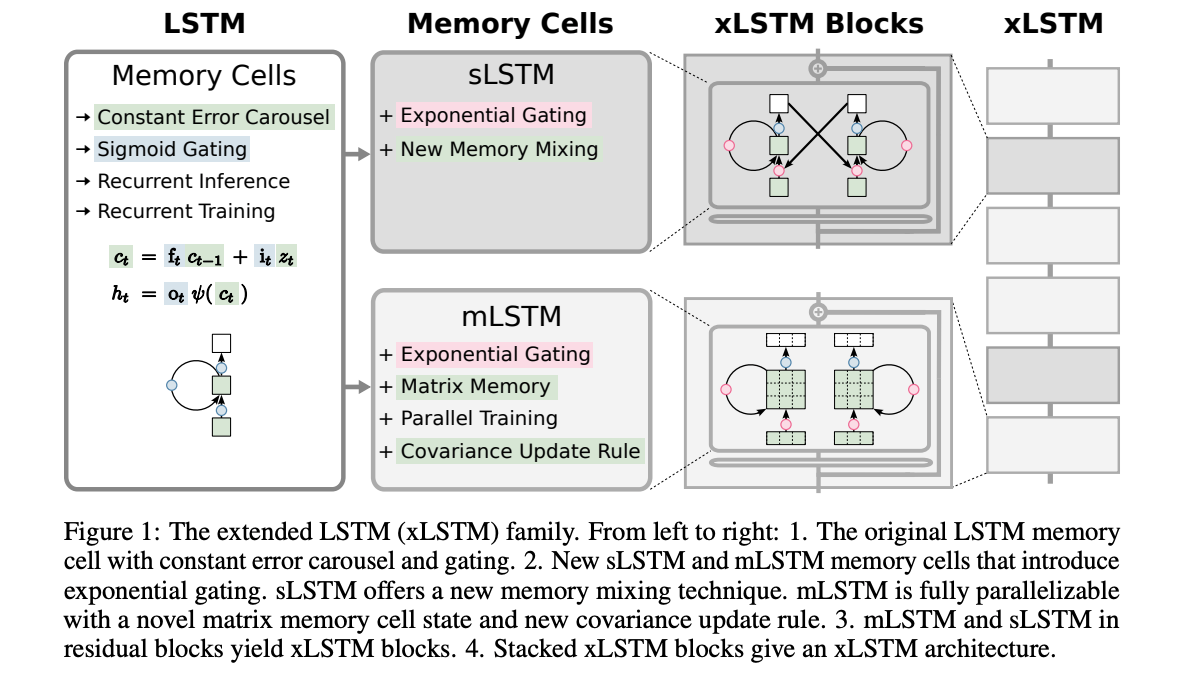
3.) xLSTM: Extended Long Short-Term Memory ( paper )
In the 1990s, the constant error carousel and gating were introduced as the central ideas of the Long Short-Term Memory (LSTM). Since then, LSTMs have stood the test of time and contributed to numerous deep learning success stories, in particular they constituted the first Large Language Models (LLMs). However, the advent of the Transformer technology with parallelizable self-attention at its core marked the dawn of a new era, outpacing LSTMs at scale. We now raise a simple question: How far do we get in language modeling when scaling LSTMs to billions of parameters, leveraging the latest techniques from modern LLMs, but mitigating known limitations of LSTMs? Firstly, we introduce exponential gating with appropriate normalization and stabilization techniques. Secondly, we modify the LSTM memory structure, obtaining: (i) sLSTM with a scalar memory, a scalar update, and new memory mixing, (ii) mLSTM that is fully parallelizable with a matrix memory and a covariance update rule. Integrating these LSTM extensions into residual block backbones yields xLSTM blocks that are then residually stacked into xLSTM architectures.
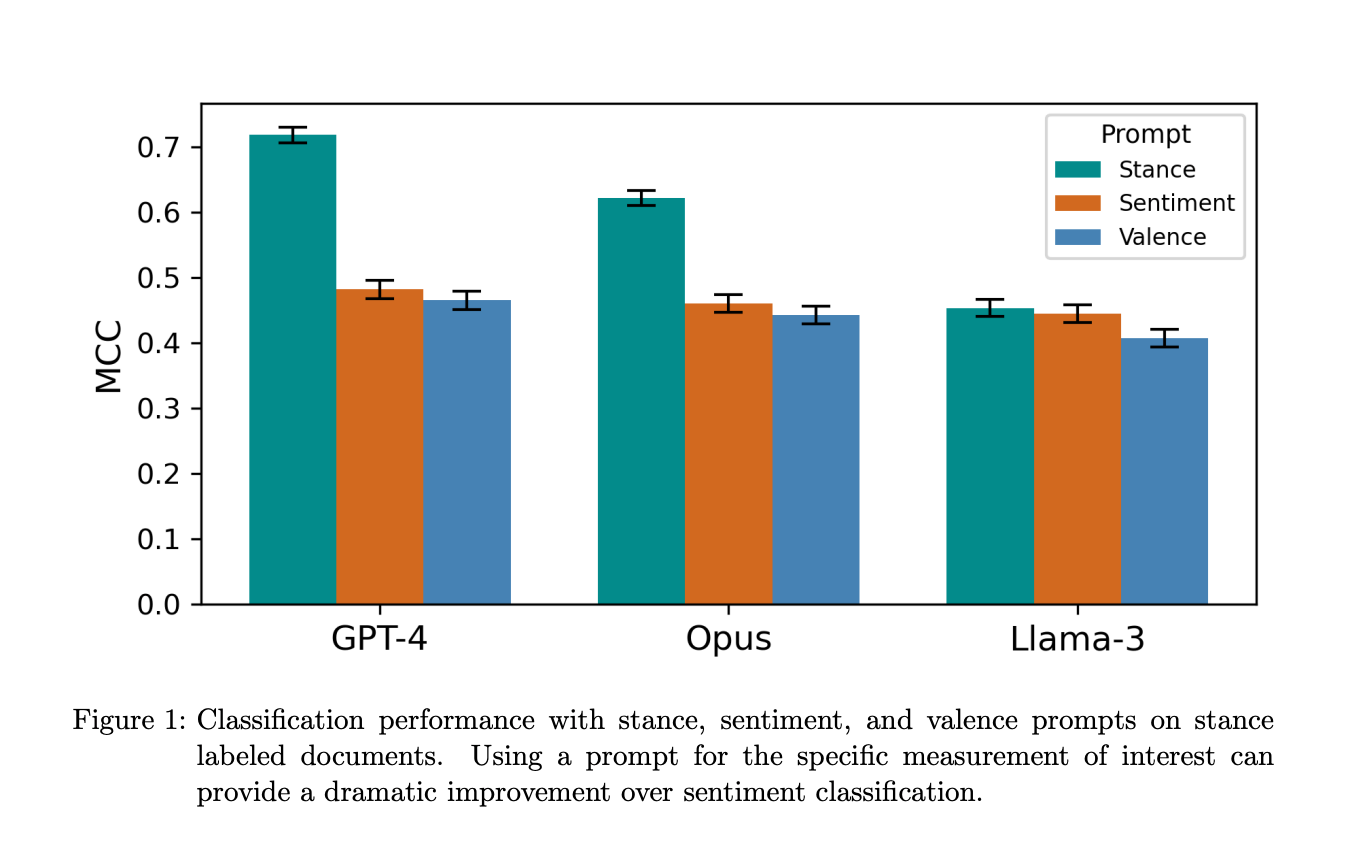
4.) What is Sentiment Meant to Mean to Language Models? ( paper )
Sentiment analysis is one of the most widely used techniques in text analysis. Recent advancements with Large Language Models have made it more accurate and accessible than ever, allowing researchers to classify text with only a plain English prompt. However, "sentiment" entails a wide variety of concepts depending on the domain and tools used. It has been used to mean emotion, opinions, market movements, or simply a general ``good-bad'' dimension. This raises a question: What exactly are language models doing when prompted to label documents by sentiment?
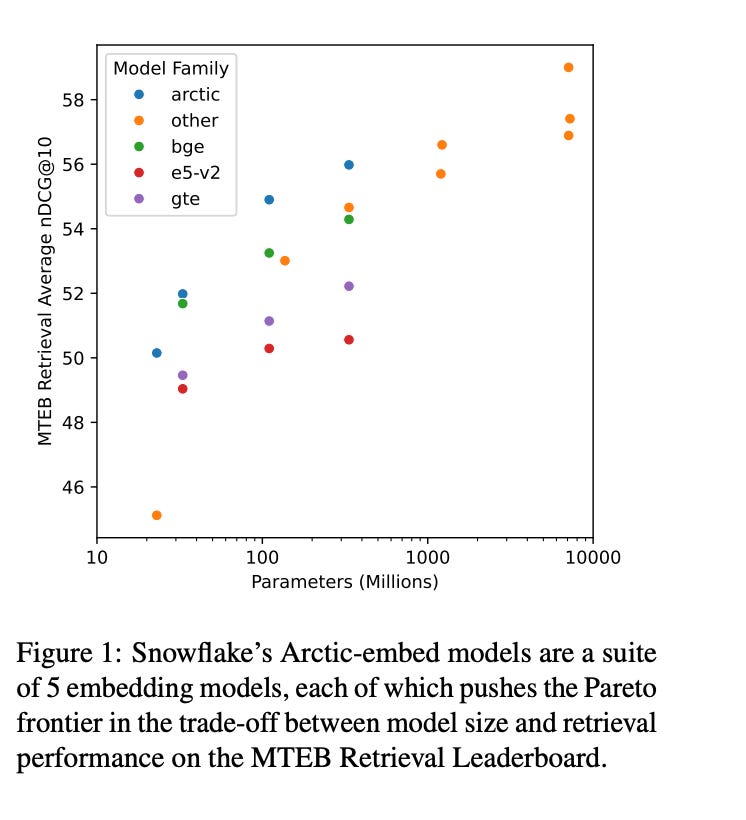
5.) Arctic-Embed: Scalable, Efficient, and Accurate Text Embedding Models ( paper )
This report describes the training dataset creation and recipe behind the family of \texttt{arctic-embed} text embedding models (a set of five models ranging from 22 to 334 million parameters with weights open-sourced under an Apache-2 license). At the time of their release, each model achieved state-of-the-art retrieval accuracy for models of their size on the MTEB Retrieval leaderboard, with the largest model, arctic-embed-l outperforming closed source embedding models such as Cohere's embed-v3 and Open AI's text-embed-3-large. In addition to the details of our training recipe, we have provided several informative ablation studies, which we believe are the cause of our model performance.
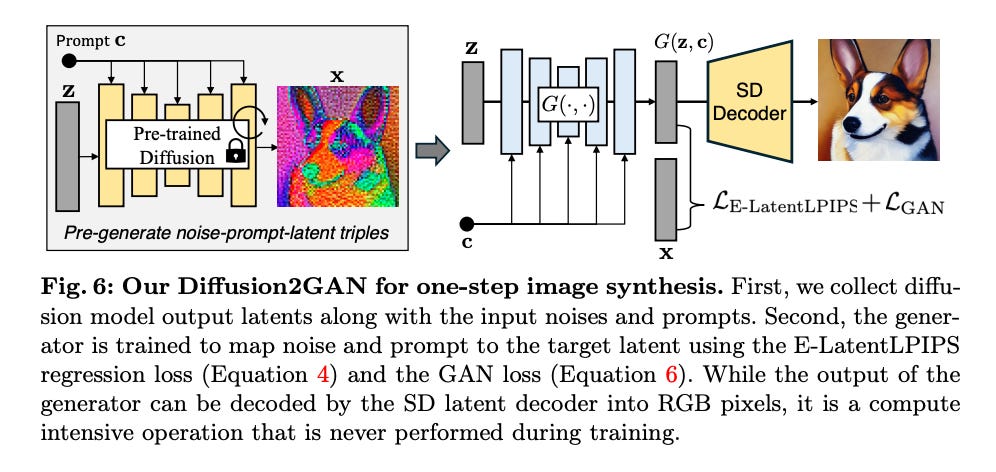
6.) Distilling Diffusion Models into Conditional GANs ( paper )
We propose a method to distill a complex multistep diffusion model into a single-step conditional GAN student model, dramatically accelerating inference, while preserving image quality. Our approach interprets diffusion distillation as a paired image-to-image translation task, using noise-to-image pairs of the diffusion model's ODE trajectory. For efficient regression loss computation, we propose E-LatentLPIPS, a perceptual loss operating directly in diffusion model's latent space, utilizing an ensemble of augmentations. Furthermore, we adapt a diffusion model to construct a multi-scale discriminator with a text alignment loss to build an effective conditional GAN-based formulation.
7.) Attention-Driven Training-Free Efficiency Enhancement of Diffusion Models ( webpage | paper )
Diffusion Models (DMs) have exhibited superior performance in generating high-quality and diverse images. However, this exceptional performance comes at the cost of expensive architectural design, particularly due to the attention module heavily used in leading models. Existing works mainly adopt a retraining process to enhance DM efficiency. This is computationally expensive and not very scalable. To this end, we introduce the Attention-driven Training-free Efficient Diffusion Model (AT-EDM) framework that leverages attention maps to perform run-time pruning of redundant tokens, without the need for any retraining. Specifically, for single-denoising-step pruning, we develop a novel ranking algorithm, Generalized Weighted Page Rank (G-WPR), to identify redundant tokens, and a similarity-based recovery method to restore tokens for the convolution operation.

8.) Stylus: Automatic Adapter Selection for Diffusion Models ( webpage | paper )
Beyond scaling base models with more data or parameters, fine-tuned adapters provide an alternative way to generate high fidelity, custom images at reduced costs. As such, adapters have been widely adopted by open-source communities, accumulating a database of over 100K adapters-most of which are highly customized with insufficient descriptions. This paper explores the problem of matching the prompt to a set of relevant adapters, built on recent work that highlight the performance gains of composing adapters.

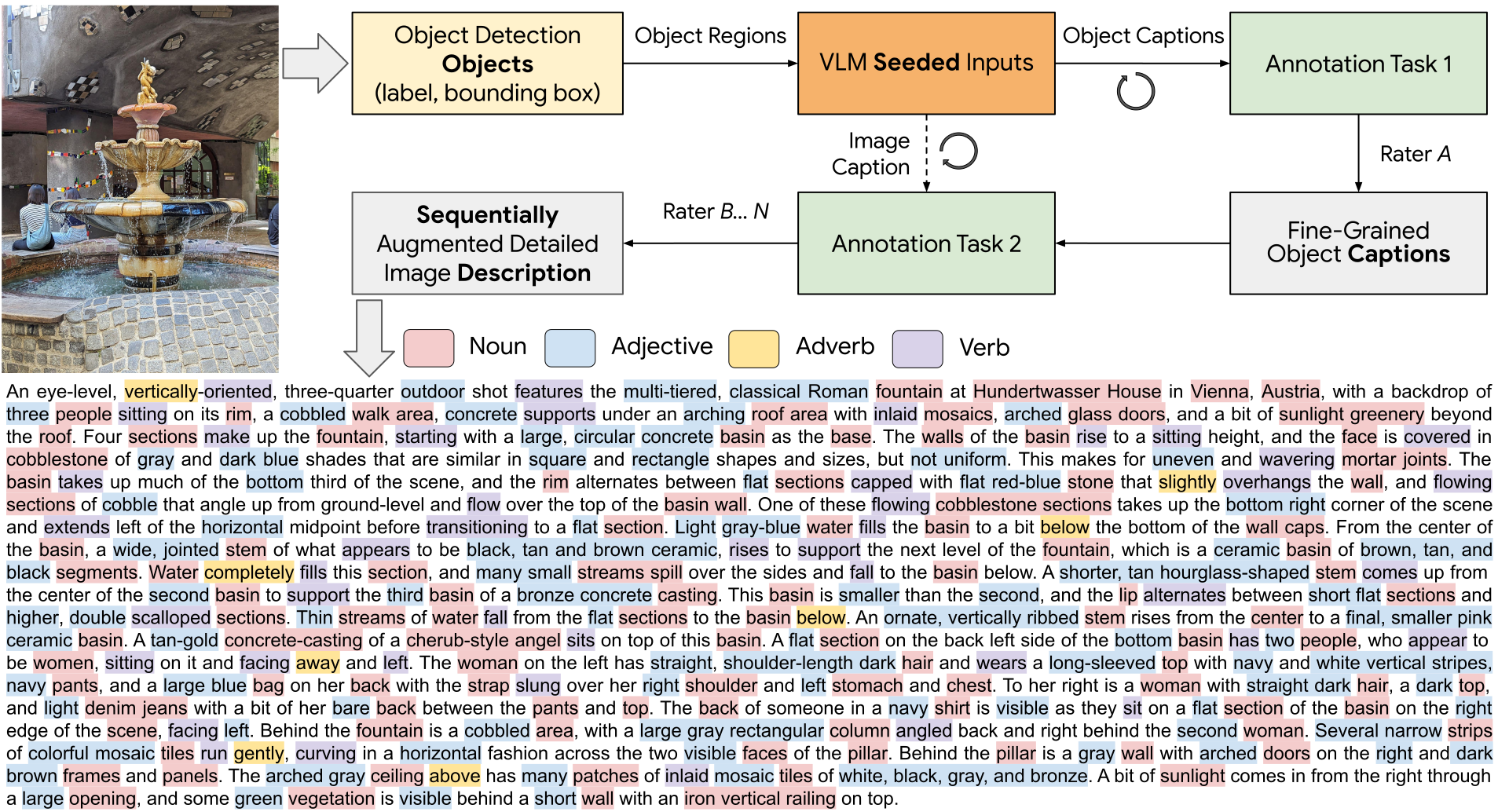
9.) ImageInWords: Unlocking Hyper-Detailed Image Descriptions ( webpage | paper | model | code )
Despite the longstanding adage "an image is worth a thousand words," creating accurate and hyper-detailed image descriptions for training Vision-Language models remains challenging. Current datasets typically have web-scraped descriptions that are short, low-granularity, and often contain details unrelated to the visual content. As a result, models trained on such data generate descriptions replete with missing information, visual inconsistencies, and hallucinations. To address these issues, we introduce ImageInWords (IIW), a carefully designed human-in-the-loop annotation framework for curating hyper-detailed image descriptions and a new dataset resulting from this process. We validate the framework through evaluations focused on the quality of the dataset and its utility for fine-tuning with considerations for readability, comprehensiveness, specificity, hallucinations, and human-likeness.
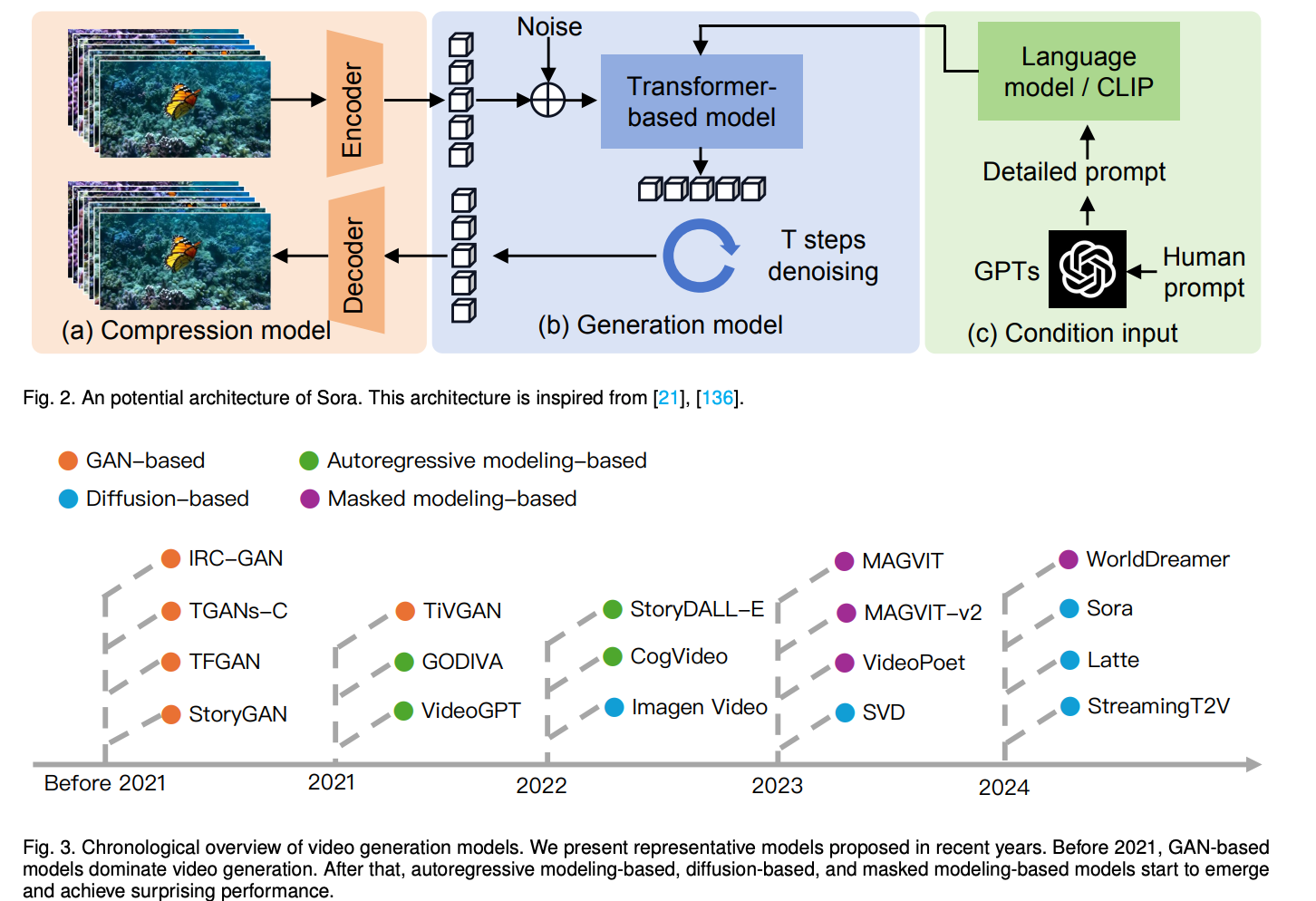
10.) Is Sora a World Simulator? A Comprehensive Survey on General World Models and Beyond ( paper | repo )
General world models represent a crucial pathway toward achieving Artificial General Intelligence (AGI), serving as the cornerstone for various applications ranging from virtual environments to decision-making systems. Recently, the emergence of the Sora model has attained significant attention due to its remarkable simulation capabilities, which exhibits an incipient comprehension of physical laws. In this survey, we embark on a comprehensive exploration of the latest advancements in world models. Our analysis navigates through the forefront of generative methodologies in video generation, where world models stand as pivotal constructs facilitating the synthesis of highly realistic visual content.
AIGC News of the week(MAY 6 - MAY 12)
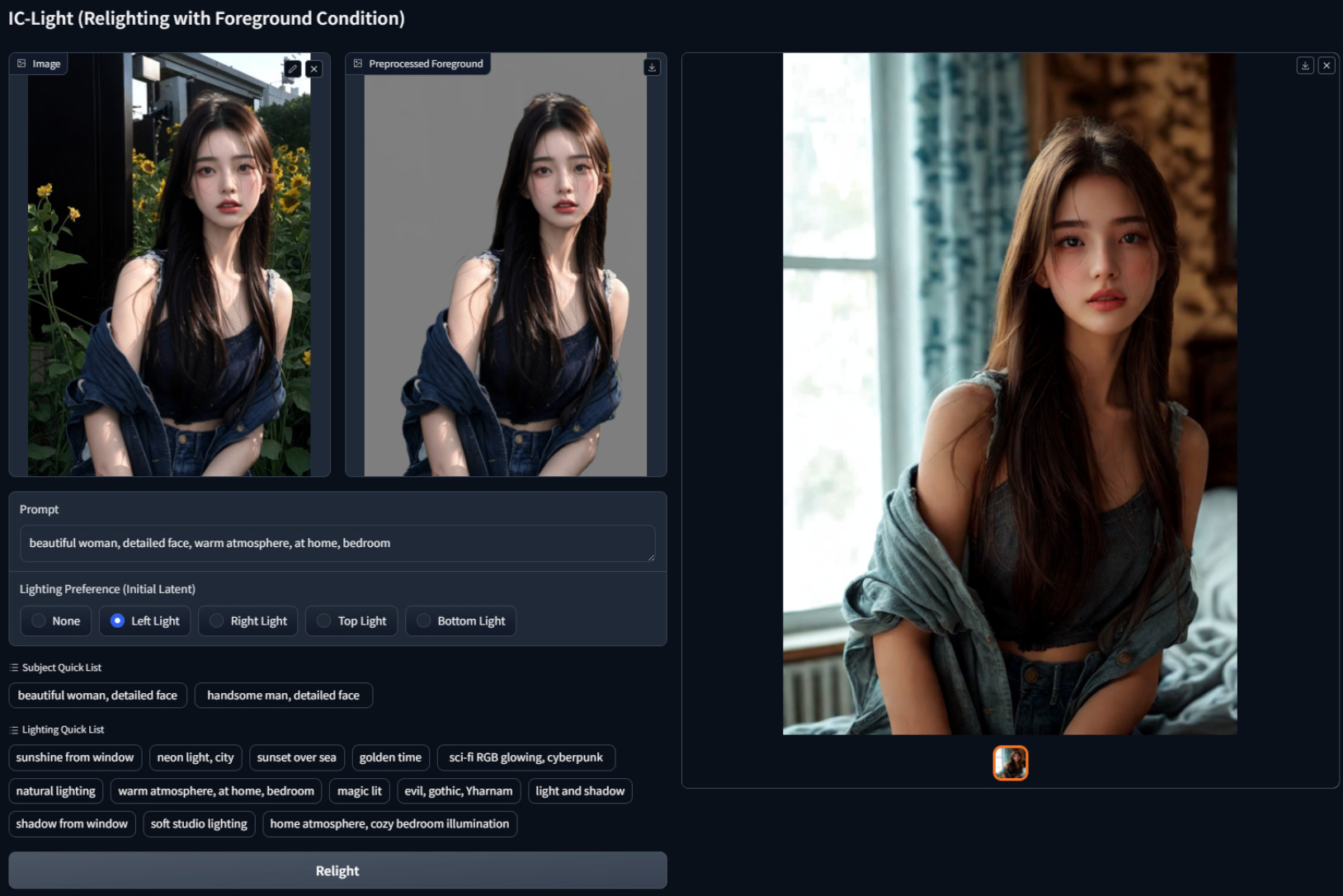
1.IC-Light is a project to manipulate the illumination of images.( repo )
2.) Gemma 2B with 10M context length using Infini-attention. ( repo )
3.) AI Agents are disrupting automation: Current approaches, market solutions and recommendations ( link )
4.) short-courses: Getting Started with Mistral ( link )
5.) OpenAI Spring Update ( webpage | live )

This newsletter's AI startup column is starting to update. Welcome everyone to subscribe: AI Startup
more AIGC News: AINews