Top Papers of the week(APR 22 - APR 28)
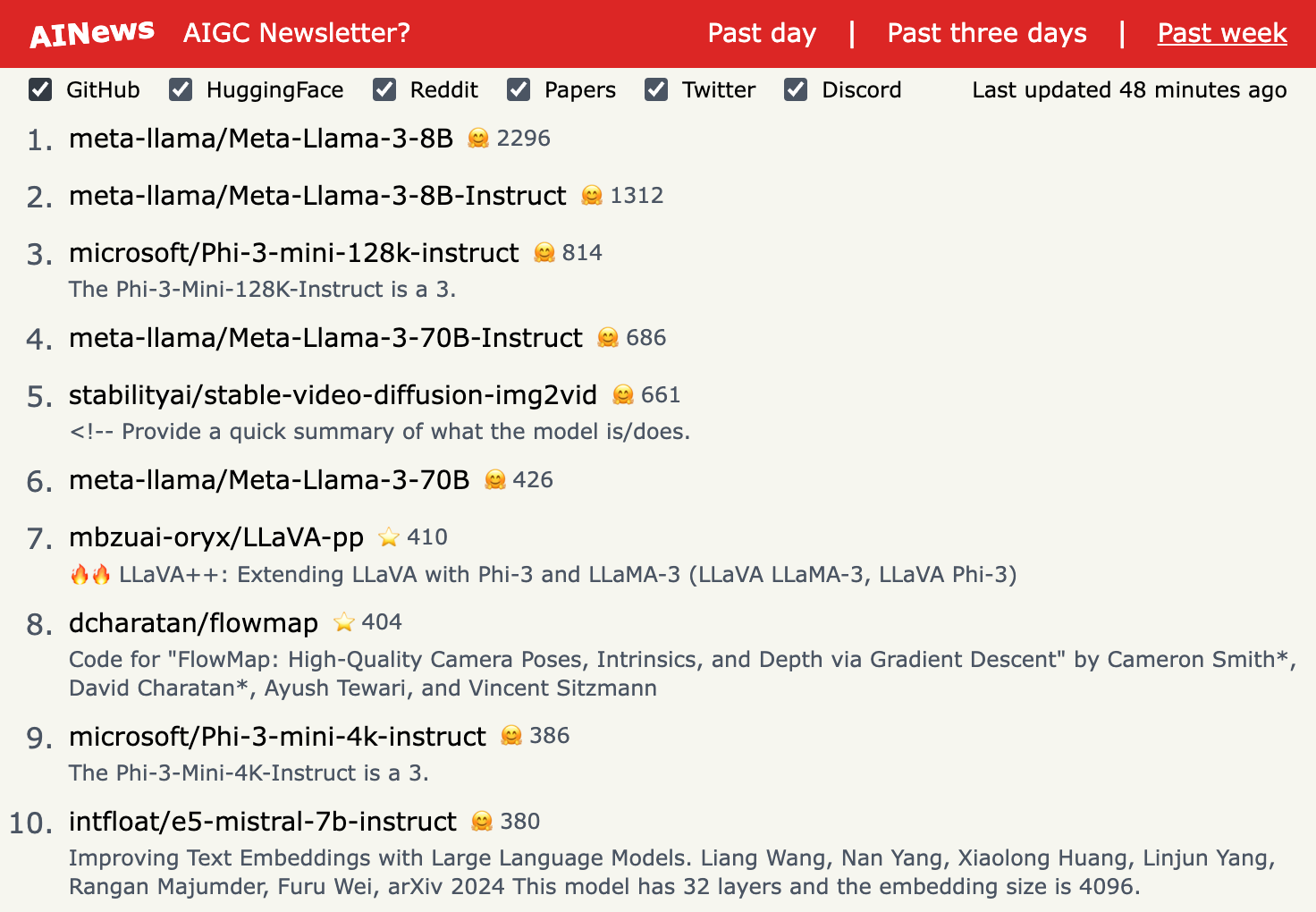
1.) OpenELM: An Efficient Language Model Family with Open-source Training and Inference Framework ( paper | code | model )
The reproducibility and transparency of large language models are crucial for advancing open research, ensuring the trustworthiness of results, and enabling investigations into data and model biases, as well as potential risks. To this end, we release OpenELM, a state-of-the-art open language model. OpenELM uses a layer-wise scaling strategy to efficiently allocate parameters within each layer of the transformer model, leading to enhanced accuracy. For example, with a parameter budget of approximately one billion parameters, OpenELM exhibits a 2.36% improvement in accuracy compared to OLMo while requiring 2× fewer pre-training tokens.
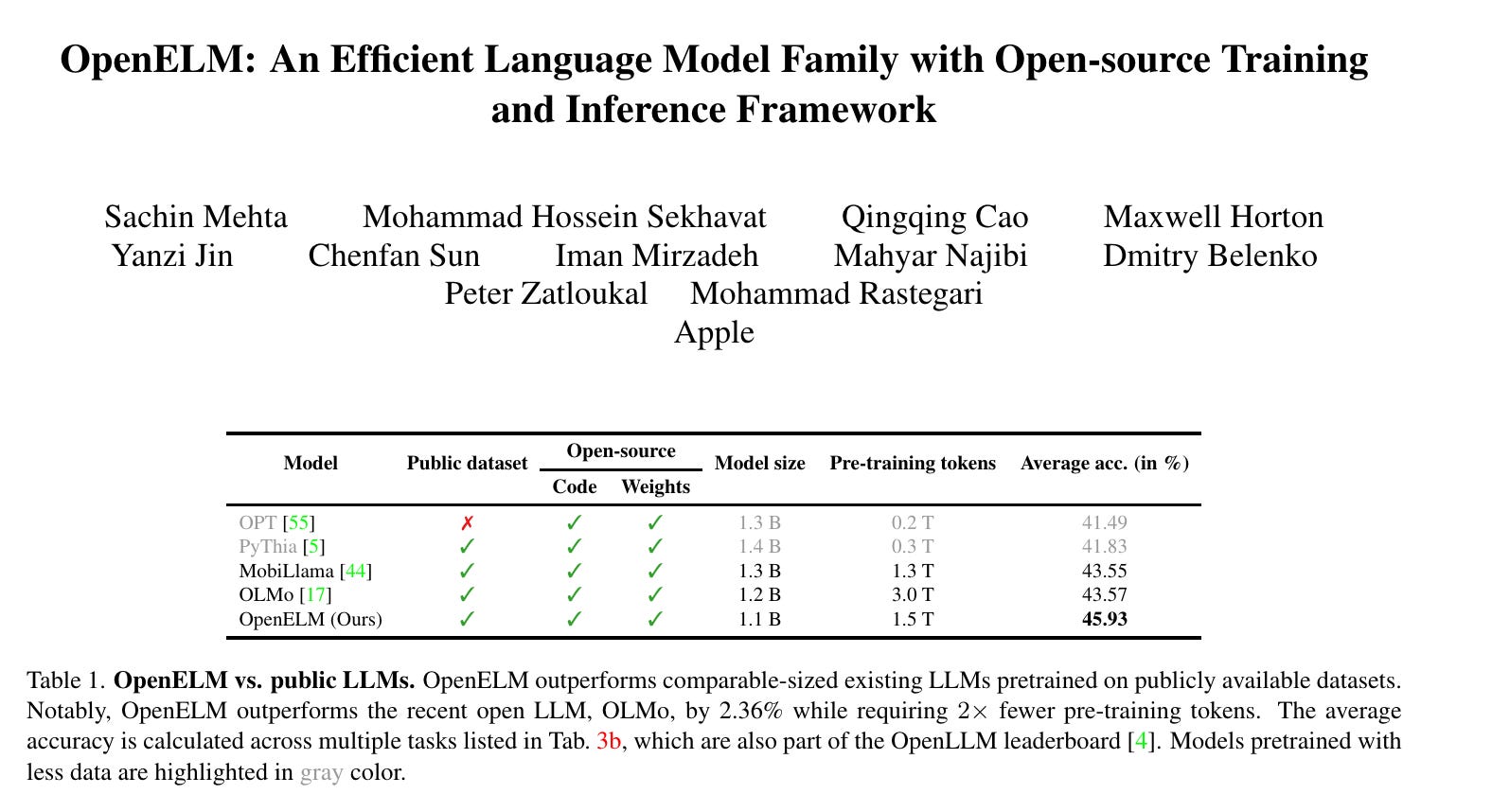
2.) Make Your LLM Fully Utilize the Context ( paper | code )
While many contemporary large language models (LLMs) can process lengthy input, they still struggle to fully utilize information within the long context, known as the lost-in-the-middle challenge. We hypothesize that it stems from insufficient explicit supervision during the long-context training, which fails to emphasize that any position in a long context can hold crucial information.
3.) FlowMind: Automatic Workflow Generation with LLMs ( paper )
The rapidly evolving field of Robotic Process Automation (RPA) has made significant strides in automating repetitive processes, yet its effectiveness diminishes in scenarios requiring spontaneous or unpredictable tasks demanded by users. This paper introduces a novel approach, FlowMind, leveraging the capabilities of Large Language Models (LLMs) such as Generative Pretrained Transformer (GPT), to address this limitation and create an automatic workflow generation system. In FlowMind, we propose a generic prompt recipe for a lecture that helps ground LLM reasoning with reliable Application Programming Interfaces (APIs).

4.) Transformers Can Represent n-gram Language Models ( paper )
Plenty of existing work has analyzed the abilities of the transformer architecture by describing its representational capacity with formal models of computation. However, the focus so far has been on analyzing the architecture in terms of language \emph{acceptance}. We contend that this is an ill-suited problem in the study of \emph{language models} (LMs), which are definitionally \emph{probability distributions} over strings. In this paper, we focus on the relationship between transformer LMs and n-gram LMs, a simple and historically relevant class of language models.

5.) Align Your Steps: Optimizing Sampling Schedules in Diffusion Models ( webpage | paper )
Diffusion models (DMs) have established themselves as the state-of-the-art generative modeling approach in the visual domain and beyond. A crucial drawback of DMs is their slow sampling speed, relying on many sequential function evaluations through large neural networks. Sampling from DMs can be seen as solving a differential equation through a discretized set of noise levels known as the sampling schedule. While past works primarily focused on deriving efficient solvers, little attention has been given to finding optimal sampling schedules, and the entire literature relies on hand-crafted heuristics.
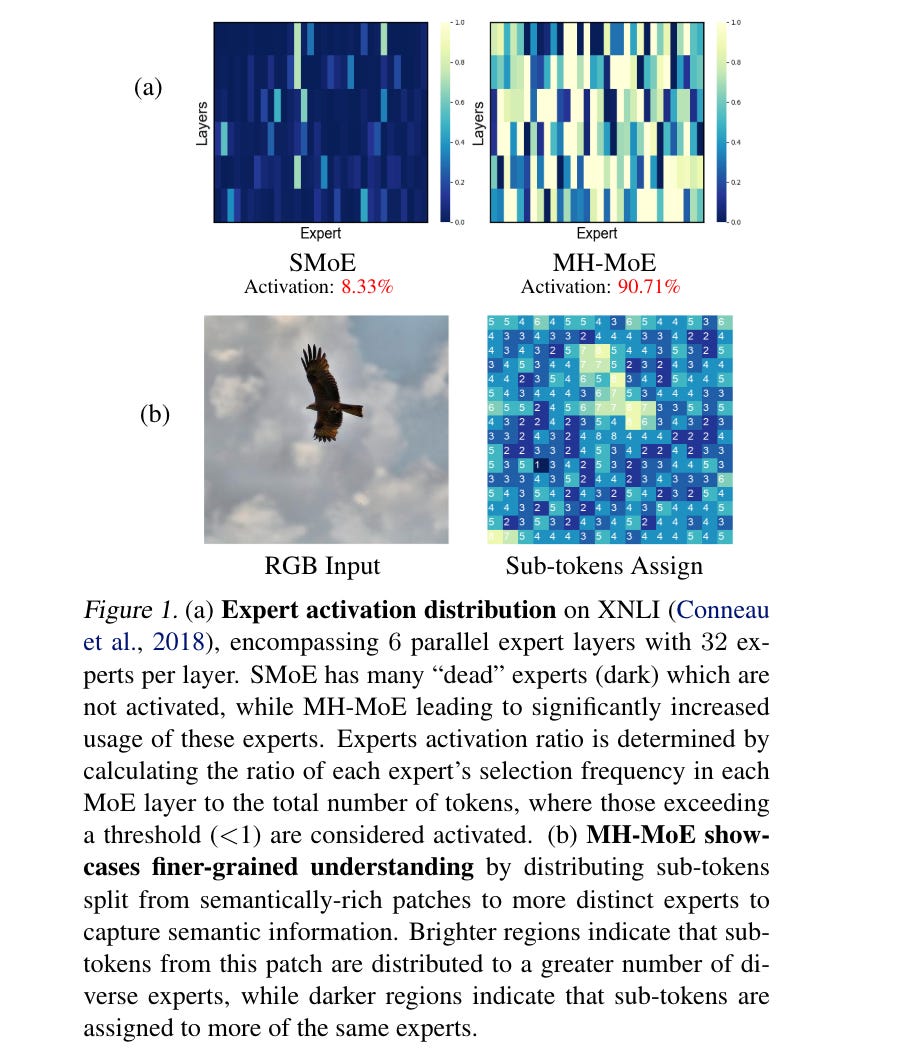
6.) Multi-Head Mixture-of-Experts ( paper )
Sparse Mixtures of Experts (SMoE) scales model capacity without significant increases in training and inference costs, but exhibits the following two issues: (1) Low expert activation, where only a small subset of experts are activated for optimization. (2) Lacking fine-grained analytical capabilities for multiple semantic concepts within individual tokens. We propose Multi-Head Mixture-of-Experts (MH-MoE), which employs a multi-head mechanism to split each token into multiple sub-tokens. These sub-tokens are then assigned to and processed by a diverse set of experts in parallel, and seamlessly reintegrated into the original token form.
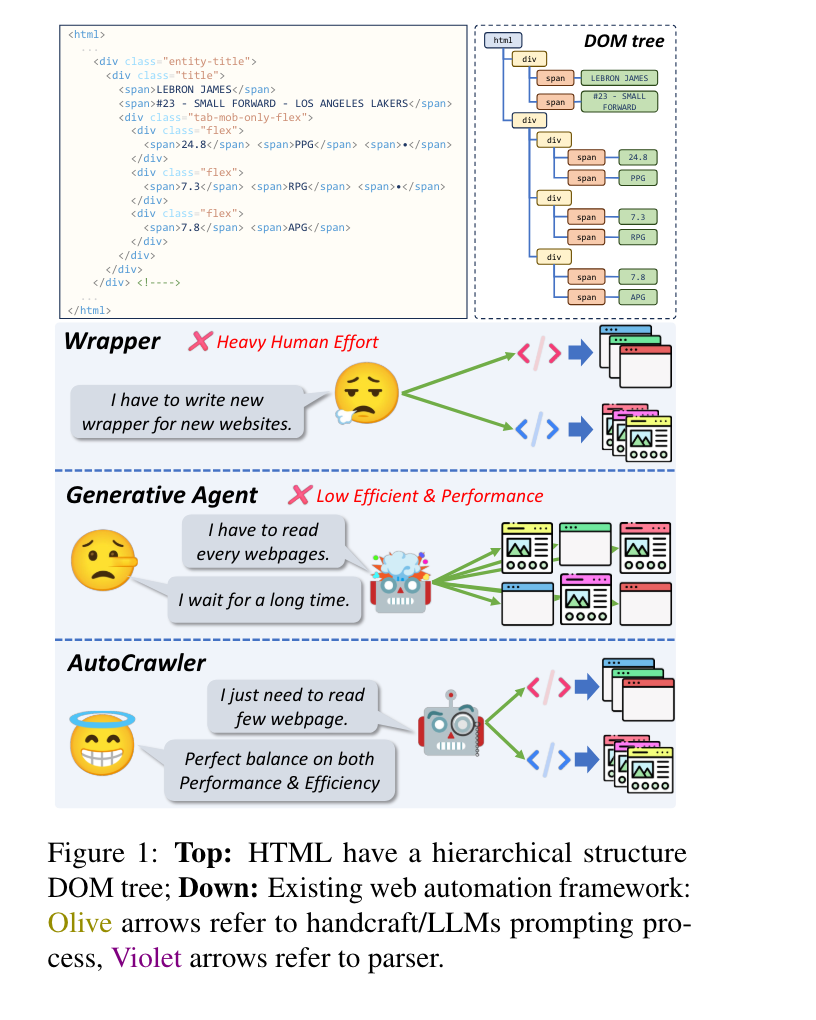
7.) AutoCrawler: A Progressive Understanding Web Agent for Web Crawler Generation ( paper | code )
Web automation is a significant technique that accomplishes complicated web tasks by automating common web actions, enhancing operational efficiency, and reducing the need for manual intervention. Traditional methods, such as wrappers, suffer from limited adaptability and scalability when faced with a new website. On the other hand, generative agents empowered by large language models (LLMs) exhibit poor performance and reusability in open-world scenarios. In this work, we introduce a crawler generation task for vertical information web pages and the paradigm of combining LLMs with crawlers, which helps crawlers handle diverse and changing web environments more efficiently.
8.) Editable Image Elements for Controllable Synthesis ( webpage | paper )
Diffusion models have made significant advances in text-guided synthesis tasks. However, editing user-provided images remains challenging, as the high dimensional noise input space of diffusion models is not naturally suited for image inversion or spatial editing. In this work, we propose an image representation that promotes spatial editing of input images using a diffusion model. Concretely, we learn to encode an input into "image elements" that can faithfully reconstruct an input image.
9.) PhysDreamer: Physics-Based Interaction with 3D Objects via Video Generation ( webpage | paper )
Realistic object interactions are crucial for creating immersive virtual experiences, yet synthesizing realistic 3D object dynamics in response to novel interactions remains a significant challenge. Unlike unconditional or text-conditioned dynamics generation, action-conditioned dynamics requires perceiving the physical material properties of objects and grounding the 3D motion prediction on these properties, such as object stiffness. However, estimating physical material properties is an open problem due to the lack of material ground-truth data, as measuring these properties for real objects is highly difficult. We present PhysDreamer, a physics-based approach that endows static 3D objects with interactive dynamics by leveraging the object dynamics priors learned by video generation models.
10.) Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone ( paper )
We introduce phi-3-mini, a 3.8 billion parameter language model trained on 3.3 trillion tokens, whose overall performance, as measured by both academic benchmarks and internal testing, rivals that of models such as Mixtral 8x7B and GPT-3.5 (e.g., phi-3-mini achieves 69% on MMLU and 8.38 on MT-bench), despite being small enough to be deployed on a phone.

AIGC News of the week(APR 22 - APR 28)
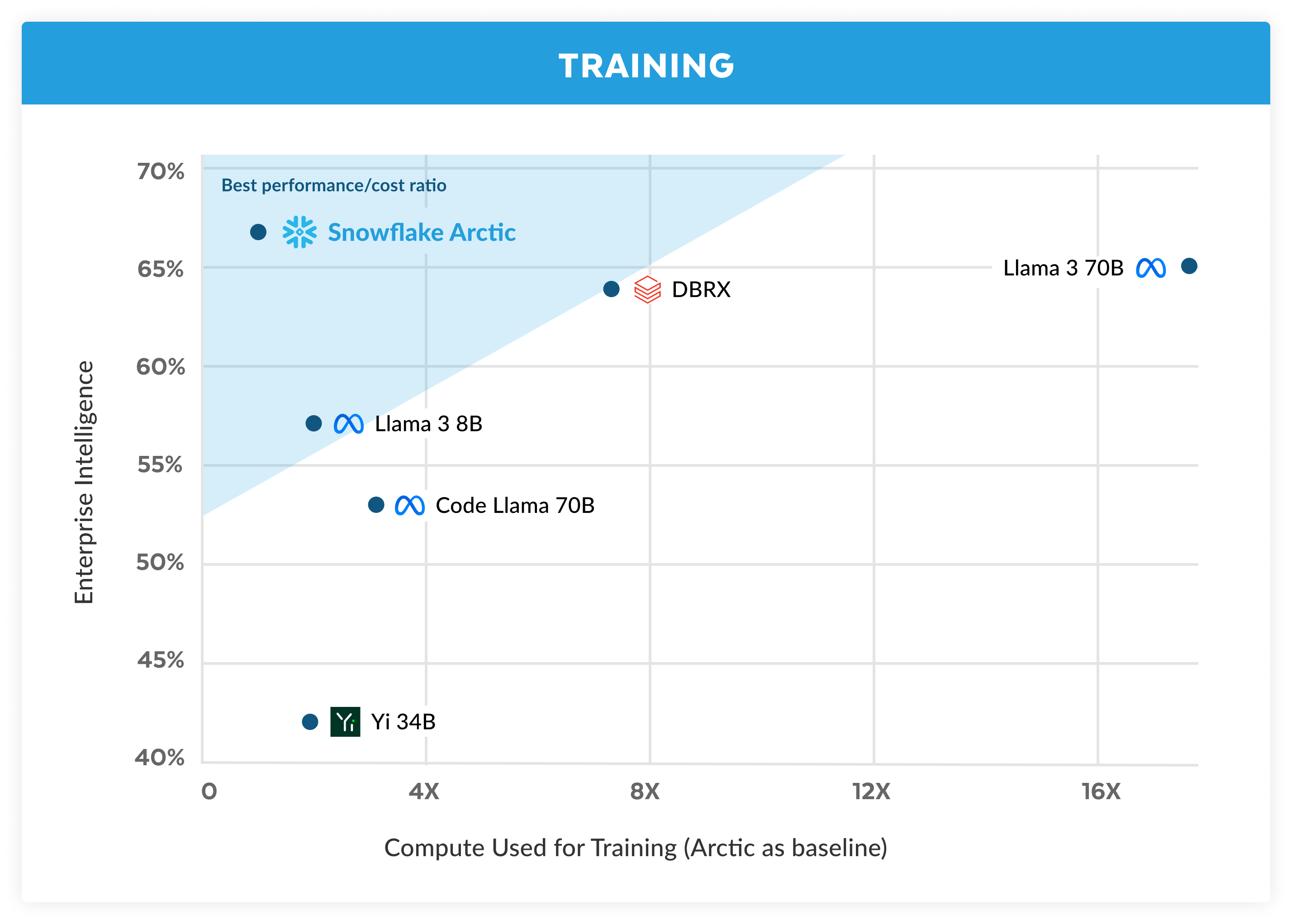
1.) Snowflake Arctic: The Best LLM for Enterprise AI — Efficiently Intelligent, Truly Open ( link )
2.) DreamPhysics: Learning Physical Properties of Dynamic 3D Gaussians from Video Diffusion Priors ( repo )
3.) LLaVA++: Extending LLaVA with Phi-3 and LLaMA-3 (LLaVA LLaMA-3, LLaVA Phi-3) ( repo )
4.) ConsistentID: Customized ID Consistent for human ( repo )
5.) Kosmos-G: Generating Images in Context with Multimodal Large Language Models ( repo )
more AIGC News: AINews