Top Papers of the week(APR 15 - APR 21)
1.) Introducing Meta Llama 3: The most capable openly available LLM to date( webpage | try | model | model card )
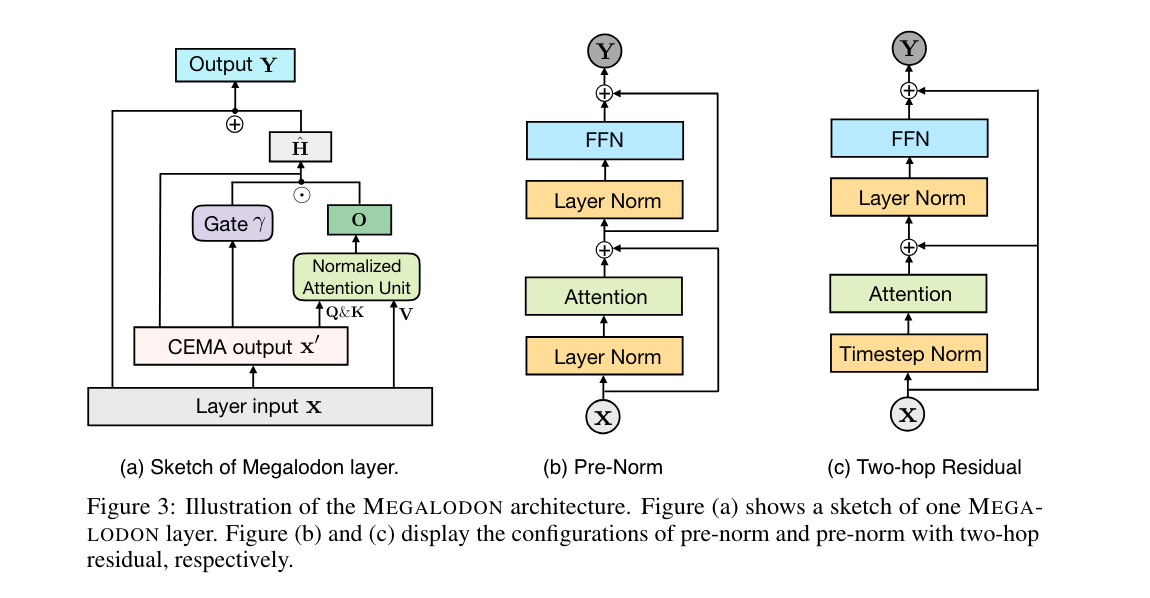
2.) Megalodon: Efficient LLM Pretraining and Inference with Unlimited Context Length ( paper | code )
The quadratic complexity and weak length extrapolation of Transformers limits their ability to scale to long sequences, and while sub-quadratic solutions like linear attention and state space models exist, they empirically underperform Transformers in pretraining efficiency and downstream task accuracy. We introduce Megalodon, a neural architecture for efficient sequence modeling with unlimited context length.
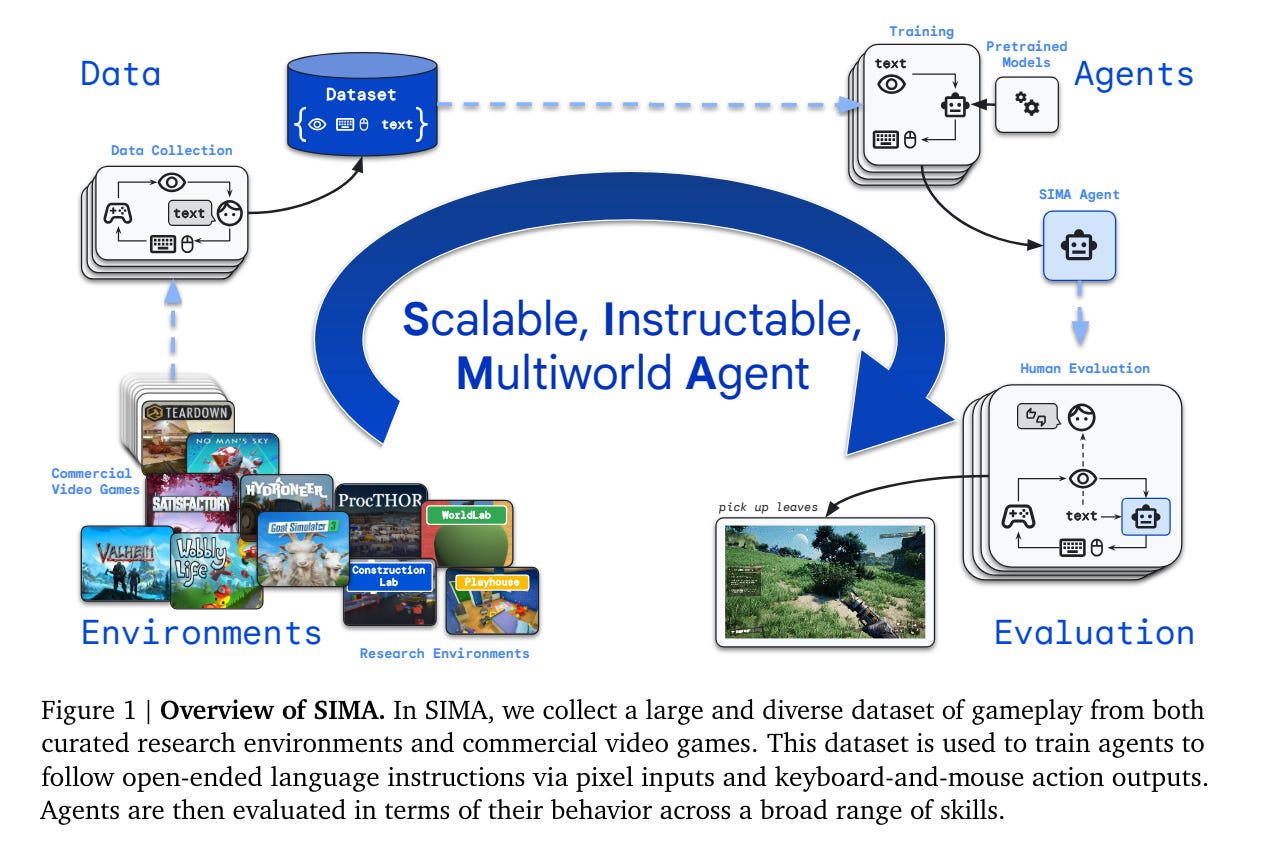
3.) Scaling Instructable Agents Across Many Simulated Worlds ( paper )
Building embodied AI systems that can follow arbitrary language instructions in any 3D environment is a key challenge for creating general AI. Accomplishing this goal requires learning to ground language in perception and embodied actions, in order to accomplish complex tasks. The Scalable, Instructable, Multiworld Agent (SIMA) project tackles this by training agents to follow free-form instructions across a diverse range of virtual 3D environments, including curated research environments as well as open-ended, commercial video games. Our goal is to develop an instructable agent that can accomplish anything a human can do in any simulated 3D environment.
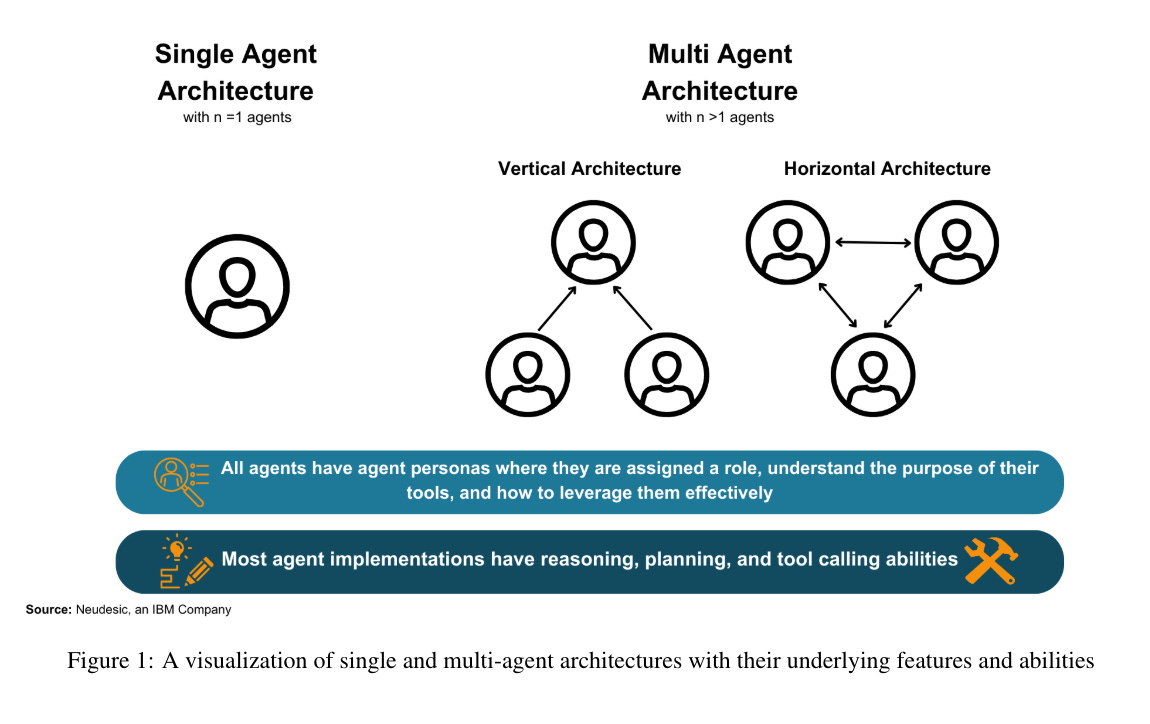
4.) The Landscape of Emerging AI Agent Architectures for Reasoning, Planning, and Tool Calling: A Survey ( paper )
This survey paper examines the recent advancements in AI agent implementations, with a focus on their ability to achieve complex goals that require enhanced reasoning, planning, and tool execution capabilities. The primary objectives of this work are to a) communicate the current capabilities and limitations of existing AI agent implementations, b) share insights gained from our observations of these systems in action, and c) suggest important considerations for future developments in AI agent design.
5.)VASA-1: Lifelike Audio-Driven Talking Faces Generated in Real Time ( webpage | paper )
We introduce VASA, a framework for generating lifelike talking faces with appealing visual affective skills (VAS) given a single static image and a speech audio clip. Our premiere model, VASA-1, is capable of not only producing lip movements that are exquisitely synchronized with the audio, but also capturing a large spectrum of facial nuances and natural head motions that contribute to the perception of authenticity and liveliness. The core innovations include a holistic facial dynamics and head movement generation model that works in a face latent space, and the development of such an expressive and disentangled face latent space using videos.
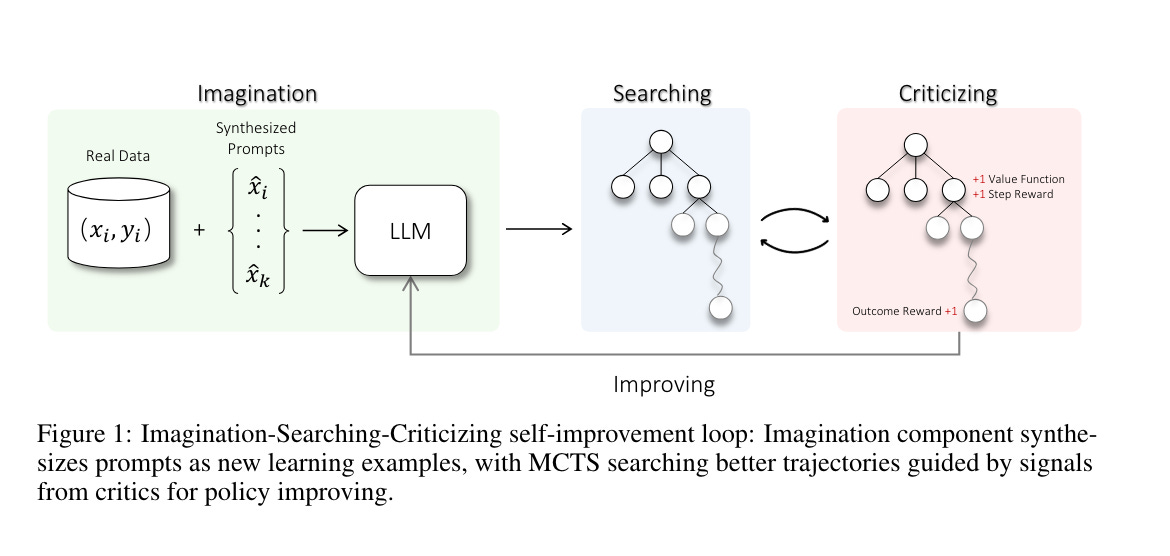
6.) Toward Self-Improvement of LLMs via Imagination, Searching, and Criticizing( paper )
Despite the impressive capabilities of Large Language Models (LLMs) on various tasks, they still struggle with scenarios that involves complex reasoning and planning. Recent work proposed advanced prompting techniques and the necessity of fine-tuning with high-quality data to augment LLMs' reasoning abilities. However, these approaches are inherently constrained by data availability and quality. In light of this, self-correction and self-learning emerge as viable solutions, employing strategies that allow LLMs to refine their outputs and learn from self-assessed rewards. Yet, the efficacy of LLMs in self-refining its response, particularly in complex reasoning and planning task, remains dubious. In this paper, we introduce AlphaLLM for the self-improvements of LLMs, which integrates Monte Carlo Tree Search (MCTS) with LLMs to establish a self-improving loop, thereby enhancing the capabilities of LLMs without additional annotations.
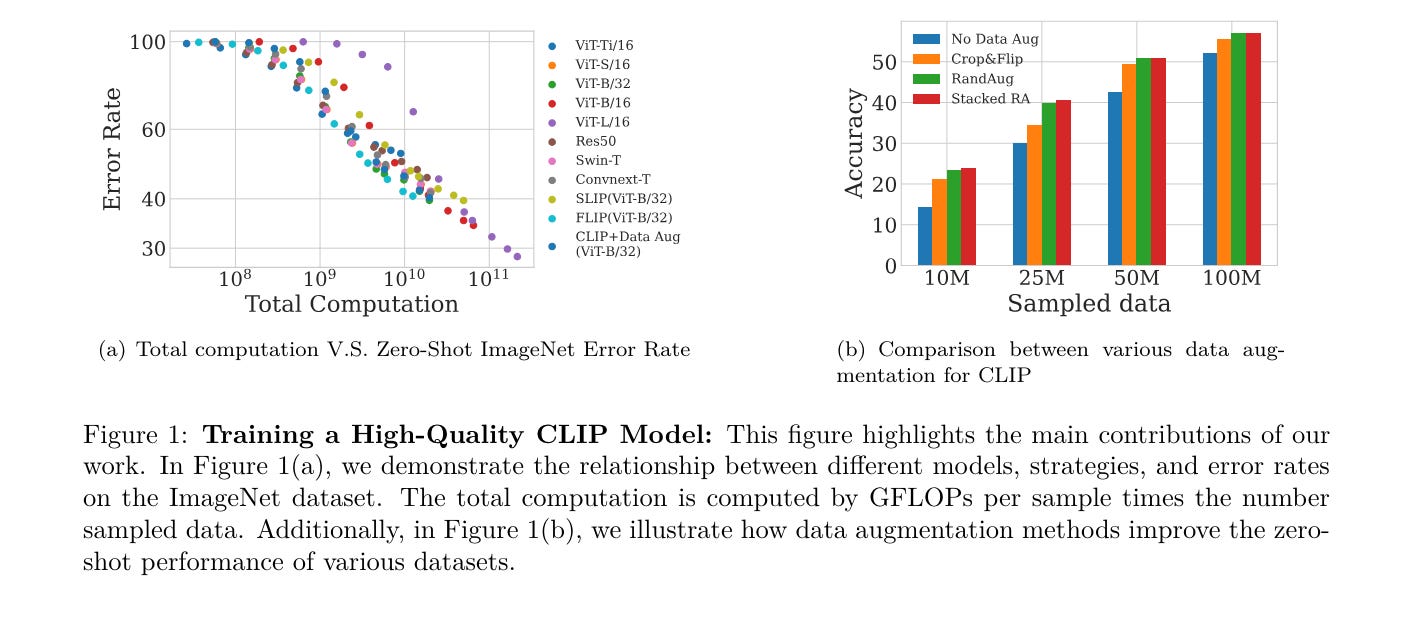
7.) Scaling (Down) CLIP: A Comprehensive Analysis of Data, Architecture, and Training Strategies( paper )
This paper investigates the performance of the Contrastive Language-Image Pre-training (CLIP) when scaled down to limited computation budgets. We explore CLIP along three dimensions: data, architecture, and training strategies. With regards to data, we demonstrate the significance of high-quality training data and show that a smaller dataset of high-quality data can outperform a larger dataset with lower quality. We also examine how model performance varies with different dataset sizes, suggesting that smaller ViT models are better suited for smaller datasets, while larger models perform better on larger datasets with fixed compute.
8.) Video2Game: Real-time, Interactive, Realistic and Browser-Compatible Environment from a Single Video( webpage | paper )
Creating high-quality and interactive virtual environments, such as games and simulators, often involves complex and costly manual modeling processes. In this paper, we present Video2Game, a novel approach that automatically converts videos of real-world scenes into realistic and interactive game environments. At the heart of our system are three core components:(i) a neural radiance fields (NeRF) module that effectively captures the geometry and visual appearance of the scene; (ii) a mesh module that distills the knowledge from NeRF for faster rendering; and (iii) a physics module that models the interactions and physical dynamics among the objects. By following the carefully designed pipeline, one can construct an interactable and actionable digital replica of the real world.
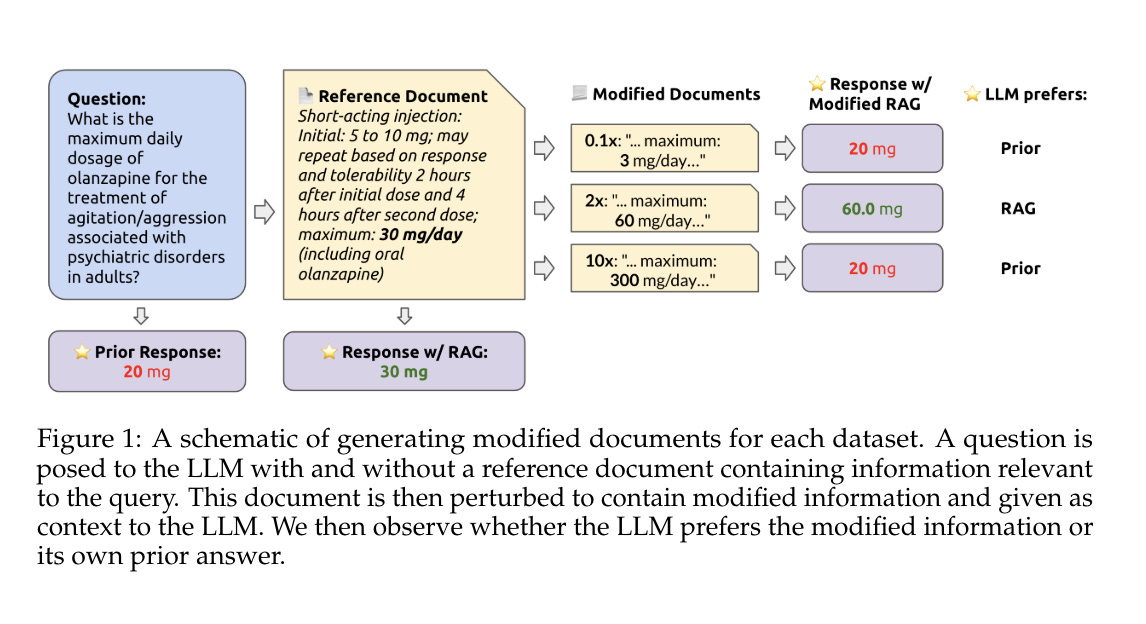
9.) How faithful are RAG models? Quantifying the tug-of-war between RAG and LLMs' internal prior ( paper )
Retrieval augmented generation (RAG) is often used to fix hallucinations and provide up-to-date knowledge for large language models (LLMs). However, in cases when the LLM alone incorrectly answers a question, does providing the correct retrieved content always fix the error? Conversely, in cases where the retrieved content is incorrect, does the LLM know to ignore the wrong information, or does it recapitulate the error? To answer these questions, we systematically analyze the tug-of-war between a LLM's internal knowledge (i.e. its prior) and the retrieved information in settings when they disagree. We test GPT-4 and other LLMs on question-answering abilities across datasets with and without reference documents.
10.) Introducing v0.5 of the AI Safety Benchmark from MLCommons ( paper )
This paper introduces v0.5 of the AI Safety Benchmark, which has been created by the MLCommons AI Safety Working Group. The AI Safety Benchmark has been designed to assess the safety risks of AI systems that use chat-tuned language models. We introduce a principled approach to specifying and constructing the benchmark, which for v0.5 covers only a single use case (an adult chatting to a general-purpose assistant in English), and a limited set of personas (i.e., typical users, malicious users, and vulnerable users). We created a new taxonomy of 13 hazard categories, of which 7 have tests in the v0.5 benchmark. We plan to release version 1.0 of the AI Safety Benchmark by the end of 2024.

AIGC News of the week(APR 15 - APR 21)
1.) AgentKit: Flow Engineering with Graphs, not Coding ( repo )
2.) SkillDiffuser on LOReL Compositional Tasks ( repo )
3.) Moving Object Segmentation: All You Need Is SAM ( repo )
4.) FineWeb: 15 trillion tokens of high quality web data. ( link )
5.) Artificial Intelligence Index Report 2024 ( link )
more AIGC News: AINews