




Top Papers of the week(APR 8 - APR 14)
1.) Leave No Context Behind: Efficient Infinite Context Transformers with Infini-attention ( paper )
This work introduces an efficient method to scale Transformer-based Large Language Models (LLMs) to infinitely long inputs with bounded memory and computation. A key component in our proposed approach is a new attention technique dubbed Infini-attention. The Infini-attention incorporates a compressive memory into the vanilla attention mechanism and builds in both masked local attention and long-term linear attention mechanisms in a single Transformer block. We demonstrate the effectiveness of our approach on long-context language modeling benchmarks, 1M sequence length passkey context block retrieval and 500K length book summarization tasks with 1B and 8B LLMs.

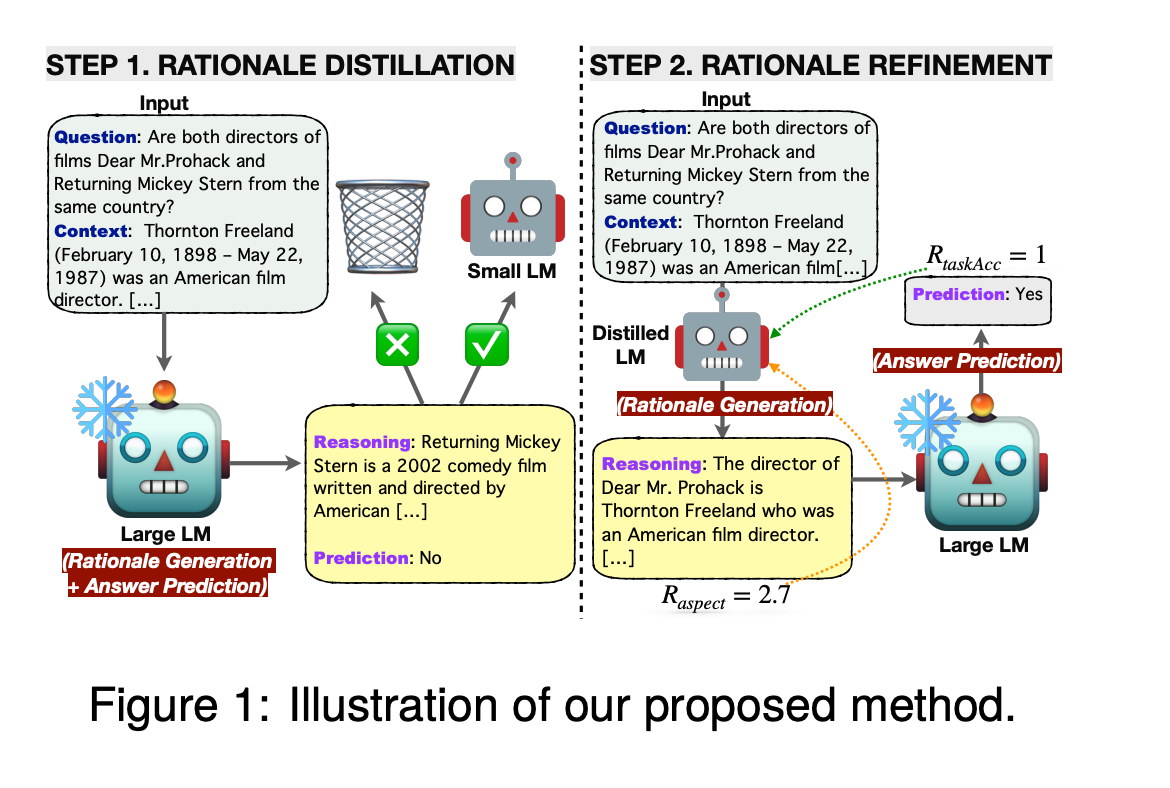
2.) Can Small Language Models Help Large Language Models Reason Better?: LM-Guided Chain-of-Thought ( paper )
We introduce a novel framework, LM-Guided CoT, that leverages a lightweight (i.e., <1B) language model (LM) for guiding a black-box large (i.e., >10B) LM in reasoning tasks. Specifically, the lightweight LM first generates a rationale for each input instance. The Frozen large LM is then prompted to predict a task output based on the rationale generated by the lightweight LM. Our approach is resource-efficient in the sense that it only requires training the lightweight LM. We optimize the model through 1) knowledge distillation and 2) reinforcement learning from rationale-oriented and task-oriented reward signals. We assess our method with multi-hop extractive question answering (QA) benchmarks, HotpotQA, and 2WikiMultiHopQA.
3.) Scaling Laws for Data Filtering -- Data Curation cannot be Compute Agnostic ( paper | code )
Vision-language models (VLMs) are trained for thousands of GPU hours on carefully curated web datasets. In recent times, data curation has gained prominence with several works developing strategies to retain 'high-quality' subsets of 'raw' scraped data. For instance, the LAION public dataset retained only 10% of the total crawled data. However, these strategies are typically developed agnostic of the available compute for training. In this paper, we first demonstrate that making filtering decisions independent of training compute is often suboptimal: the limited high-quality data rapidly loses its utility when repeated, eventually requiring the inclusion of 'unseen' but 'lower-quality' data. To address this quality-quantity tradeoff (𝚀𝚀𝚃), we introduce neural scaling laws that account for the non-homogeneous nature of web data, an angle ignored in existing literature. Our scaling laws (i) characterize the differing 'utility' of various quality subsets of web data; (ii) account for how utility diminishes for a data point at its 'nth' repetition; and (iii) formulate the mutual interaction of various data pools when combined, enabling the estimation of model performance on a combination of multiple data pools without ever jointly training on them.

4.) Scaling (Down) CLIP: A Comprehensive Analysis of Data, Architecture, and Training Strategies ( paper )
This paper investigates the performance of the Contrastive Language-Image Pre-training (CLIP) when scaled down to limited computation budgets. We explore CLIP along three dimensions: data, architecture, and training strategies. With regards to data, we demonstrate the significance of high-quality training data and show that a smaller dataset of high-quality data can outperform a larger dataset with lower quality. We also examine how model performance varies with different dataset sizes, suggesting that smaller ViT models are better suited for smaller datasets, while larger models perform better on larger datasets with fixed compute. Additionally, we provide guidance on when to choose a CNN-based architecture or a ViT-based architecture for CLIP training.

5.) Rho-1: Not All Tokens Are What You Need ( paper )
Previous language model pre-training methods have uniformly applied a next-token prediction loss to all training tokens. Challenging this norm, we posit that "Not all tokens in a corpus are equally important for language model training". Our initial analysis delves into token-level training dynamics of language model, revealing distinct loss patterns for different tokens. Leveraging these insights, we introduce a new language model called Rho-1. Unlike traditional LMs that learn to predict every next token in a corpus, Rho-1 employs Selective Language Modeling (SLM), which selectively trains on useful tokens that aligned with the desired distribution. This approach involves scoring pretraining tokens using a reference model, and then training the language model with a focused loss on tokens with higher excess loss.

6.) ControlNet++: Improving Conditional Controls with Efficient Consistency Feedback ( webpage | paper )
To enhance the controllability of text-to-image diffusion models, existing efforts like ControlNet incorporated image-based conditional controls. In this paper, we reveal that existing methods still face significant challenges in generating images that align with the image conditional controls. To this end, we propose ControlNet++, a novel approach that improves controllable generation by explicitly optimizing pixel-level cycle consistency between generated images and conditional controls. Specifically, for an input conditional control, we use a pre-trained discriminative reward model to extract the corresponding condition of the generated images, and then optimize the consistency loss between the input conditional control and extracted condition. A straightforward implementation would be generating images from random noises and then calculating the consistency loss, but such an approach requires storing gradients for multiple sampling timesteps, leading to considerable time and memory costs.

7.RULER: What's the Real Context Size of Your Long-Context Language Models?( paper )
The needle-in-a-haystack (NIAH) test, which examines the ability to retrieve a piece of information (the "needle") from long distractor texts (the "haystack"), has been widely adopted to evaluate long-context language models (LMs). However, this simple retrieval-based test is indicative of only a superficial form of long-context understanding. To provide a more comprehensive evaluation of long-context LMs, we create a new synthetic benchmark RULER with flexible configurations for customized sequence length and task complexity. RULER expands upon the vanilla NIAH test to encompass variations with diverse types and quantities of needles. Moreover, RULER introduces new task categories multi-hop tracing and aggregation to test behaviors beyond searching from context. We evaluate ten long-context LMs with 13 representative tasks in RULER. Despite achieving nearly perfect accuracy in the vanilla NIAH test, all models exhibit large performance drops as the context length increases.

8.) OpenEQA: Embodied Question Answering in the Era of Foundation Models ( webpage | blog | code )
We present a modern formulation of Embodied Question Answering (EQA) as the task of understanding an environment well enough to answer questions about it in natural language. An agent can achieve such an understanding by either drawing upon episodic memory, exemplified by agents on smart glasses, or by actively exploring the environment, as in the case of mobile robots. We accompany our formulation with OpenEQA - the first open-vocabulary benchmark dataset for EQA supporting both episodic memory and active exploration use cases. OpenEQA contains over 1600 high-quality human generated questions drawn from over 180 real-world environments.
9.) Multilingual Large Language Model: A Survey of Resources, Taxonomy and Frontiers ( paper )
Multilingual Large Language Models are capable of using powerful Large Language Models to handle and respond to queries in multiple languages, which achieves remarkable success in multilingual natural language processing tasks. Despite these breakthroughs, there still remains a lack of a comprehensive survey to summarize existing approaches and recent developments in this field. To this end, in this paper, we present a thorough review and provide a unified perspective to summarize the recent progress as well as emerging trends in multilingual large language models (MLLMs) literature.

10.) Ferret-UI: Grounded Mobile UI Understanding with Multimodal LLMs ( paper )
Recent advancements in multimodal large language models (MLLMs) have been noteworthy, yet, these general-domain MLLMs often fall short in their ability to comprehend and interact effectively with user interface (UI) screens. In this paper, we present Ferret-UI, a new MLLM tailored for enhanced understanding of mobile UI screens, equipped with referring, grounding, and reasoning capabilities. Given that UI screens typically exhibit a more elongated aspect ratio and contain smaller objects of interest (e.g., icons, texts) than natural images, we incorporate "any resolution" on top of Ferret to magnify details and leverage enhanced visual features. Specifically, each screen is divided into 2 sub-images based on the original aspect ratio (i.e., horizontal division for portrait screens and vertical division for landscape screens). Both sub-images are encoded separately before being sent to LLMs.

AIGC News of the week(APR 8 - APR 14)
1.) Grok-1.5 Vision Preview ( link )

2.) OpenAI simple-evals: a lightweight library for evaluating language models ( repo )
3.) InstantMesh: Efficient 3D Mesh Generation from a Single Image with Sparse-view Large Reconstruction Models ( repo )
4.) Meta confirms that its Llama 3 open source LLM is coming in the next month ( link)
5.) Introducing Udio, an app for music creation and sharing that allows you to generate amazing music ( link )
more AIGC News: AINews
