Top Papers of the week(April 1 - April 7)
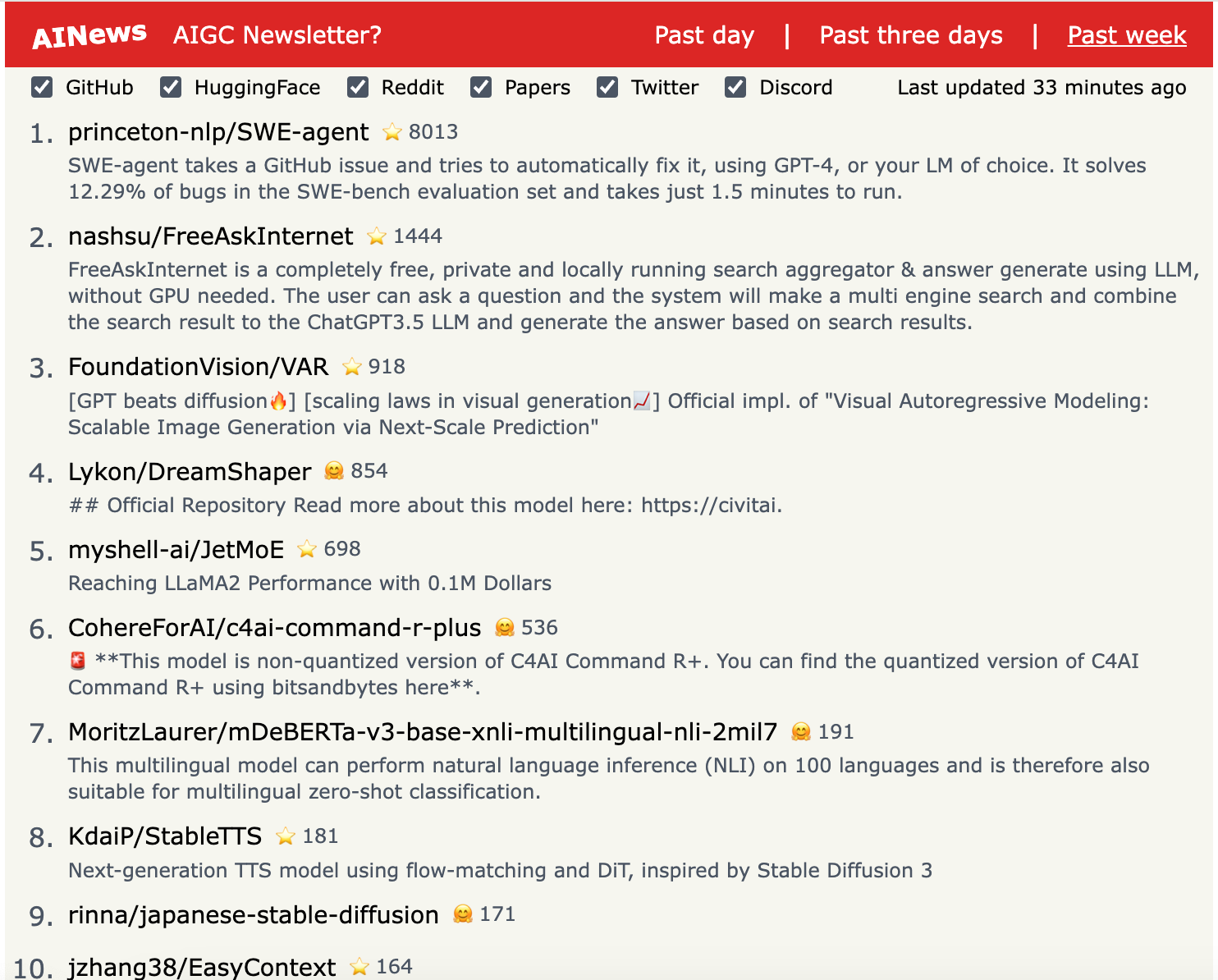
1.) Mixture-of-Depths: Dynamically allocating compute in transformer-based language models ( paper )
Transformer-based language models spread FLOPs uniformly across input sequences. In this work we demonstrate that transformers can instead learn to dynamically allocate FLOPs (or compute) to specific positions in a sequence, optimising the allocation along the sequence for different layers across the model depth. Our method enforces a total compute budget by capping the number of tokens (k) that can participate in the self-attention and MLP computations at a given layer.
2.) Video Interpolation with Diffusion Models( webpage | paper )
We present VIDIM, a generative model for video interpolation, which creates short videos given a start and end frame. In order to achieve high fidelity and generate motions unseen in the input data, VIDIM uses cascaded diffusion models to first generate the target video at low resolution, and then generate the high-resolution video conditioned on the low-resolution generated video.
3.) Many-shot jailbreaking ( webpage | paper )
We investigate a family of simple long-context attacks on large language models: prompting with hundreds of demonstrations of undesirable behavior. This is newly feasible with the larger context windows recently deployed by Anthropic, OpenAI and Google DeepMind. We find that in diverse, realistic circumstances, the effectiveness of this attack follows a power law, up to hundreds of shots. We demonstrate the success of this attack on the most widely used state-of-the-art closedweight models, and across various tasks. Our results suggest very long contexts present a rich new attack surface for LLMs

4.) AI and the Problem of Knowledge Collapse ( paper )
While artificial intelligence has the potential to process vast amounts of data, generate new insights, and unlock greater productivity, its widespread adoption may entail unforeseen consequences. We identify conditions under which AI, by reducing the cost of access to certain modes of knowledge, can paradoxically harm public understanding. While large language models are trained on vast amounts of diverse data, they naturally generate output towards the 'center' of the distribution. This is generally useful, but widespread reliance on recursive AI systems could lead to a process we define as "knowledge collapse", and argue this could harm innovation and the richness of human understanding and culture. However, unlike AI models that cannot choose what data they are trained on, humans may strategically seek out diverse forms of knowledge if they perceive them to be worthwhile.

5.) sDPO: Don't Use Your Data All at Once ( paper )
As development of large language models (LLM) progresses, aligning them with human preferences has become increasingly important. We propose stepwise DPO (sDPO), an extension of the recently popularized direct preference optimization (DPO) for alignment tuning. This approach involves dividing the available preference datasets and utilizing them in a stepwise manner, rather than employing it all at once. We demonstrate that this method facilitates the use of more precisely aligned reference models within the DPO training framework. Furthermore, sDPO trains the final model to be more performant, even outperforming other popular LLMs with more parameters.

6.) Bigger is not Always Better: Scaling Properties of Latent Diffusion Models ( paper )
We study the scaling properties of latent diffusion models (LDMs) with an emphasis on their sampling efficiency. While improved network architecture and inference algorithms have shown to effectively boost sampling efficiency of diffusion models, the role of model size -- a critical determinant of sampling efficiency -- has not been thoroughly examined.

7.) InstantStyle: Free Lunch towards Style-Preserving in Text-to-Image Generation( webpage | paper )
Tuning-free diffusion-based models have demonstrated sig- nificant potential in the realm of image personalization and customiza- tion. However, despite this notable progress, current models continue to grapple with several complex challenges in producing style-consistent image generation.

8.) PointInfinity: Resolution-Invariant Point Diffusion Models ( paper )
We present PointInfinity, an efficient family of point cloud diffusion models. Our core idea is to use a transformer-based architecture with a fixed-size, resolution-invariant latent representation. This enables efficient training with low-resolution point clouds, while allowing high-resolution point clouds to be generated during inference.

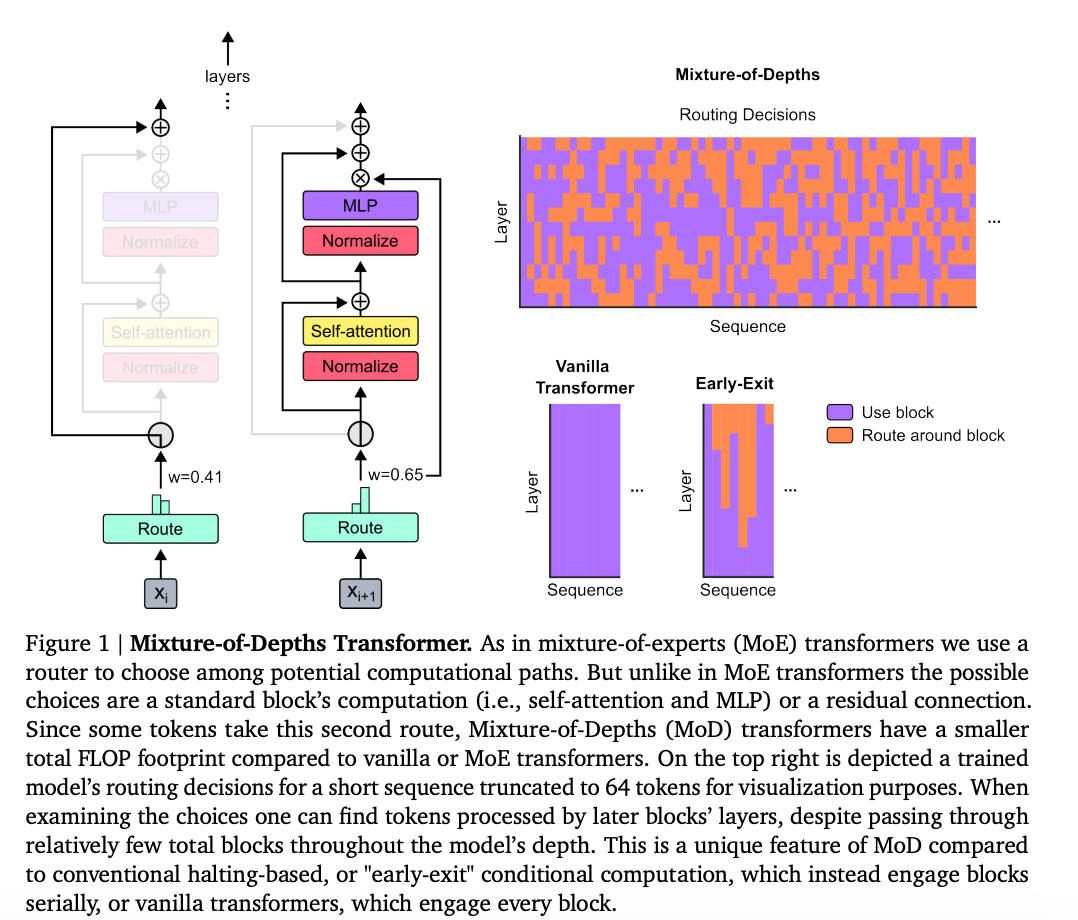
9.) RL for Consistency Models: Faster Reward Guided Text-to-Image Generation ( webpage | paper )
Reinforcement learning (RL) has improved guided image generation with diffusion models by directly optimizing rewards that capture image quality, aesthetics, and instruction following capabilities. However, the resulting generative policies inherit the same iterative sampling process of diffusion models that causes slow generation. To overcome this limitation, consistency models proposed learning a new class of generative models that directly map noise to data, resulting in a model that can generate an image in as few as one sampling iteration. In this work, to optimize text-to-image generative models for task specific rewards and enable fast training and inference, we propose a framework for fine-tuning consistency models via RL.
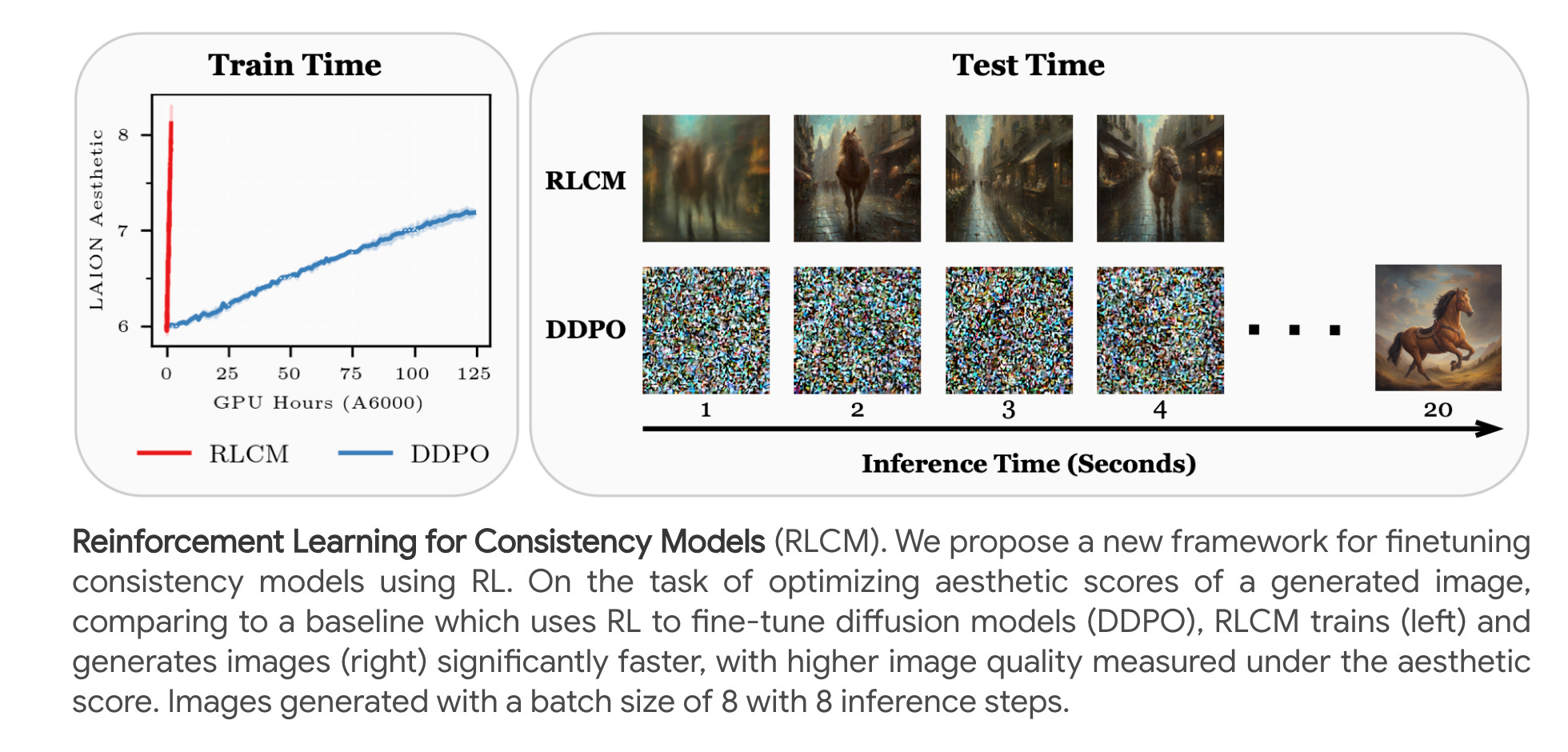
10.) Chinese Tiny LLM: Pretraining a Chinese-Centric Large Language Model ( paper | model)
In this study, we introduce CT-LLM, a 2B large language model (LLM) that illustrates a pivotal shift towards prioritizing the Chinese language in developing LLMs. Uniquely initiated from scratch, CT-LLM diverges from the conventional methodology by primarily incorporating Chinese textual data, utilizing an extensive corpus of 1,200 billion tokens, including 800 billion Chinese tokens, 300 billion English tokens, and 100 billion code tokens. This strategic composition facilitates the model's exceptional proficiency in understanding and processing Chinese, a capability further enhanced through alignment techniques.
AIGC News of the week(April 1 - April 7)
1.) SWE-agent: takes a GitHub issue and tries to automatically fix it, using GPT-4, or your LM of choice. It solves 12.29% of bugs in the SWE-bench evaluation set and takes just 1.5 minutes to run.( webpage | repo )
2.) llm-colosseum:Evaluate LLMs in real time with Street Fighter III ( repo )
3.) VAR:Official impl. of "Visual Autoregressive Modeling: Scalable Image Generation via Next-Scale Prediction" ( repo )
4.) ViTamin:Designing Scalable Vision Models in the Vision-language Era ( repo )
5.) AutoWebGLM: Bootstrap And Reinforce A Large Language Model-based Web Navigating Agent ( repo )
more AIGC News: AINews