Top Papers of the week(Mar 25- Mar 31)
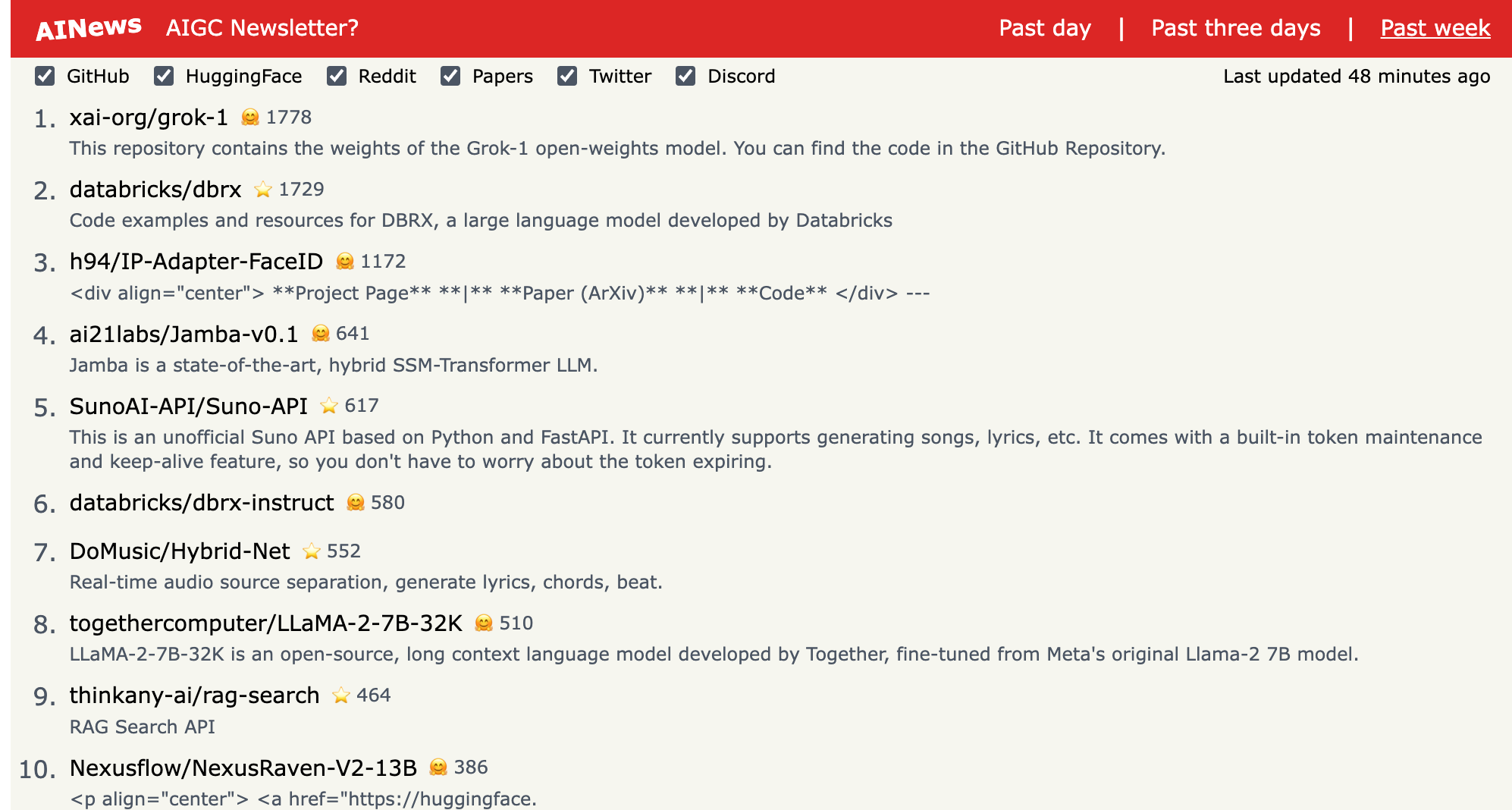
1.Introducing DBRX: A New State-of-the-Art Open LLM ( link )
Databricks has launched DBRX, an open large language model (LLM) that exceeds the capabilities of previous open models and closed APIs like GPT-3.5. DBRX excels in programming tasks, outperforming specialized models, and competes with Gemini 1.0 Pro in general tasks. It utilizes a fine-grained mixture-of-experts (MoE) architecture for efficiency, offering faster inference and a smaller size. Trained on 12 trillion tokens, DBRX demonstrates superior quality on benchmarks, particularly in programming and mathematics, and is competitive in long-context and RAG tasks. The model's training was facilitated by Databricks' suite of tools and is available for use via APIs, with weights accessible on Hugging Face.
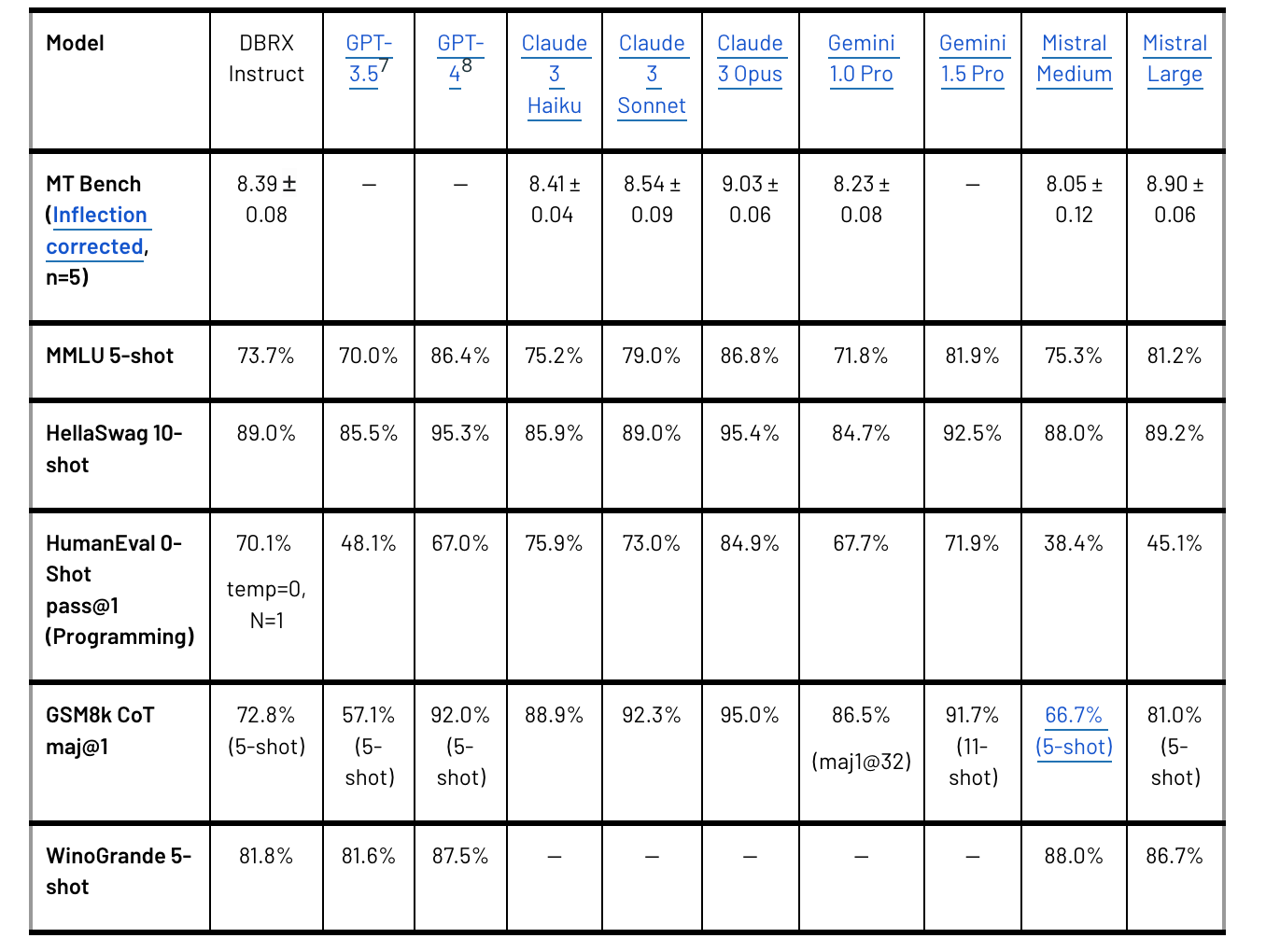
2.Announcing Grok-1.5 ( link )
Grok-1.5, the latest model from xAI, boasts enhanced reasoning skills and the ability to handle contexts up to 128,000 tokens. This significant expansion in context length, 16 times greater than its predecessor, allows Grok-1.5 to process longer documents and complex prompts while maintaining strong instruction-following capabilities. The model has shown impressive results in coding and math-related tasks, scoring 50.6% on the MATH benchmark, 90% on the GSM8K benchmark, and 74.1% on the HumanEval benchmark. These scores reflect its proficiency in grade school to high school level math problems and code generation. Grok-1.5 is built on a custom training framework that incorporates JAX, Rust, and Kubernetes, facilitating efficient prototyping and scaling. The model is set to be available on the 𝕏 platform for early testers and existing users, with a gradual rollout planned as feedback is collected for further improvements.
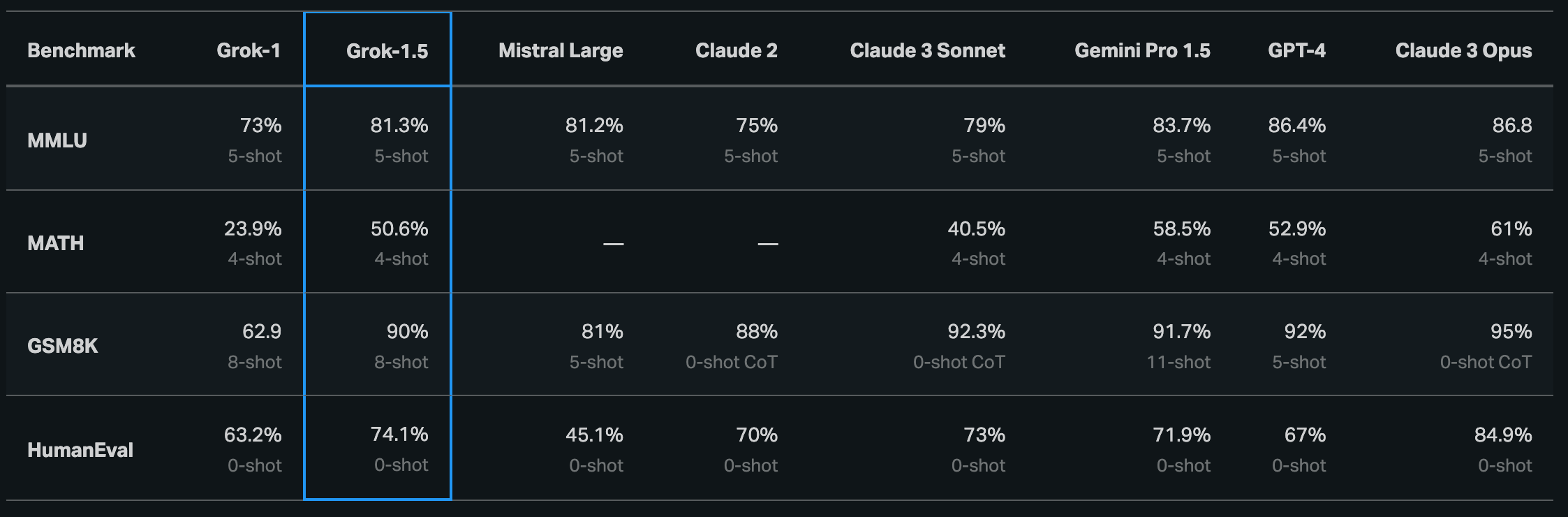
3.Long-form factuality in large language models ( paper | code )
The paper "Long-Form Factuality in Large Language Models" introduces a novel framework for assessing the factual accuracy of large language models (LLMs) in generating long-form content. It presents LongFact, a set of 2,280 prompts across 38 topics, and the Search-Augmented Factuality Evaluator (SAFE), which automates the fact-checking process by leveraging Google Search. The paper also proposes the F1@K metric, extending the F1 score to balance precision and recall in long-form responses. Empirical results show SAFE outperforms human annotators in accuracy and cost, and benchmarks reveal that larger models tend to have better long-form factuality. This work sets a new standard for evaluating and enhancing the reliability of LLMs in producing factually accurate long-form content.
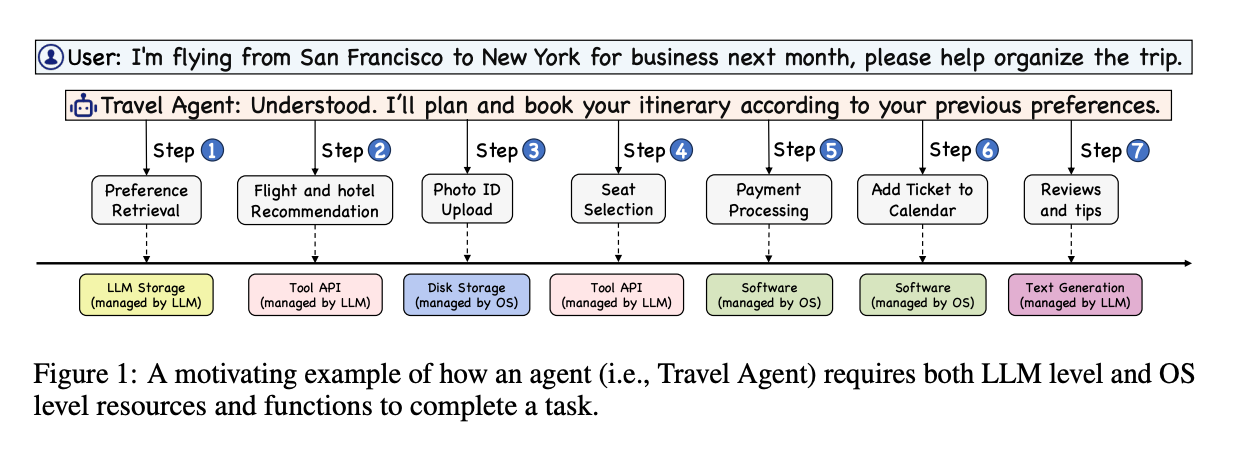
4.AIOS: LLM Agent Operating System ( paper | code )
The integration and deployment of large language model (LLM)-based intelligent agents have been fraught with challenges that compromise their efficiency and efficacy. Among these issues are sub-optimal scheduling and resource allocation of agent requests over the LLM, the difficulties in maintaining context during interactions between agent and LLM, and the complexities inherent in integrating heterogeneous agents with different capabilities and specializations. The rapid increase of agent quantity and complexity further exacerbates these issues, often leading to bottlenecks and sub-optimal utilization of resources. Inspired by these challenges, this paper presents AIOS, an LLM agent operating system, which embeds large language model into operating systems (OS) as the brain of the OS, enabling an operating system "with soul" -- an important step towards AGI.
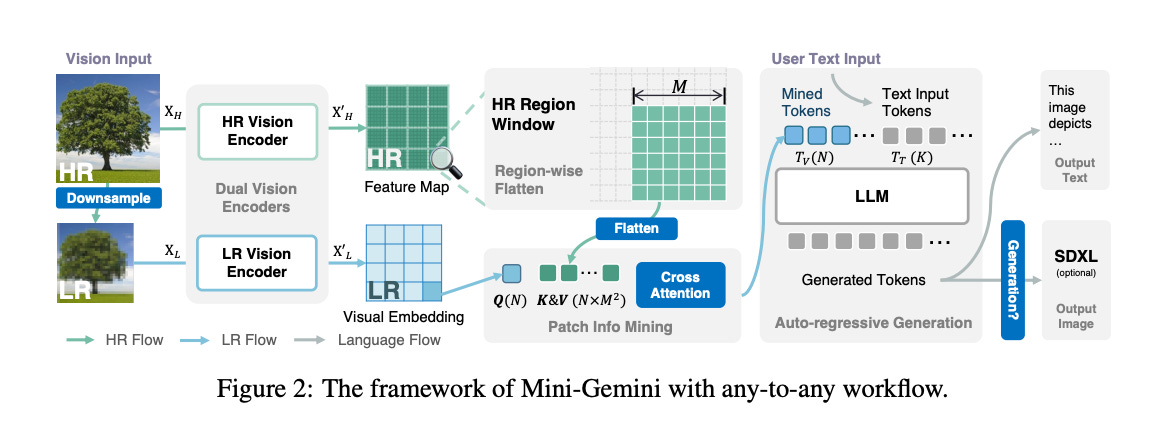
5.Mini-Gemini: Mining the Potential of Multi-modality Vision Language Models ( paper | code )
In this work, we introduce Mini-Gemini, a simple and effective framework enhancing multi-modality Vision Language Models (VLMs). Despite the advancements in VLMs facilitating basic visual dialog and reasoning, a performance gap persists compared to advanced models like GPT-4 and Gemini. We try to narrow the gap by mining the potential of VLMs for better performance and any-to-any workflow from three aspects, i.e., high-resolution visual tokens, high-quality data, and VLM-guided generation.
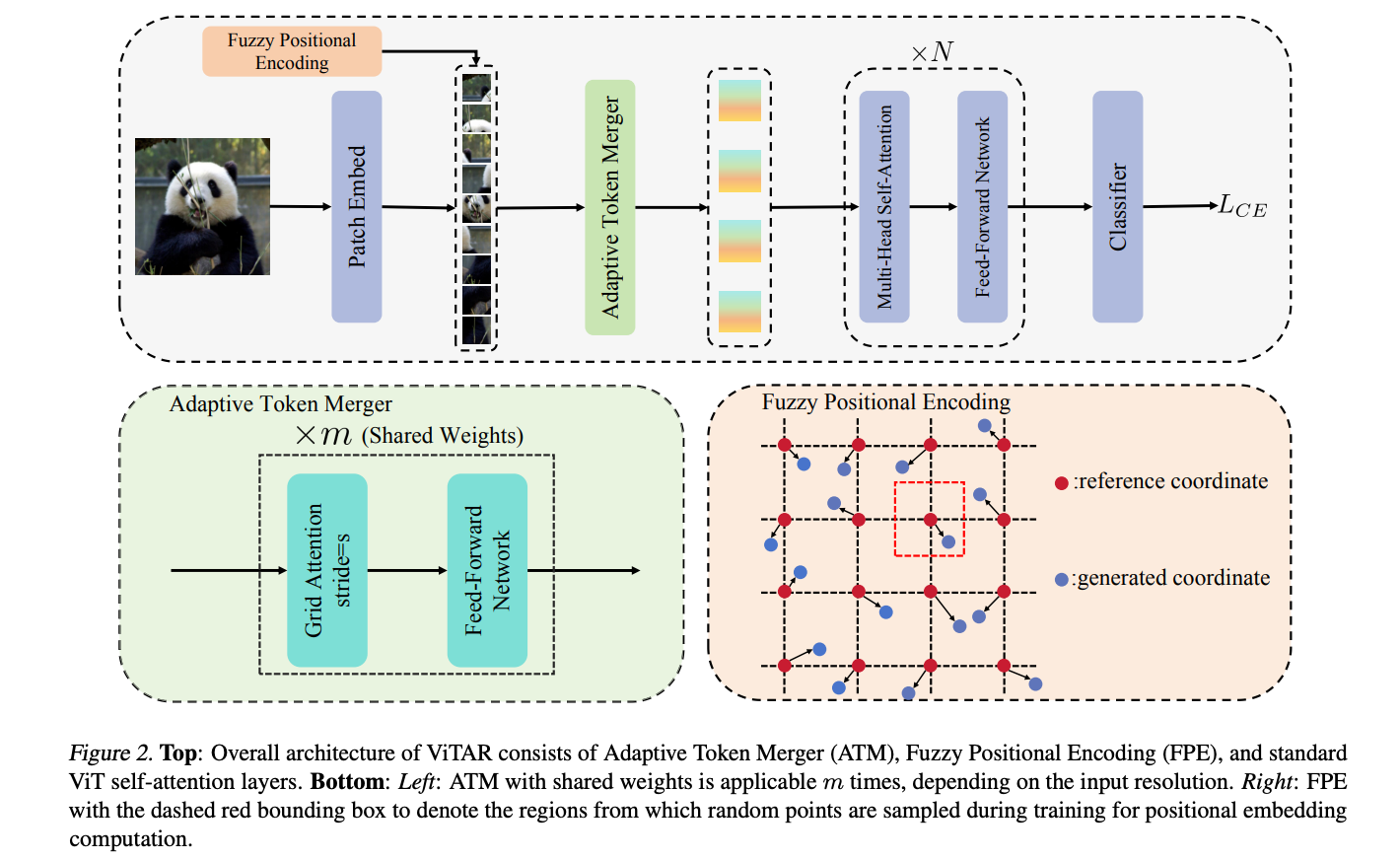
6.ViTAR: Vision Transformer with Any Resolution ( paper )
This paper tackles a significant challenge faced by Vision Transformers (ViTs): their constrained scalability across different image resolutions. Typically, ViTs experience a performance decline when processing resolutions different from those seen during training. Our work introduces two key innovations to address this issue. Firstly, we propose a novel module for dynamic resolution adjustment, designed with a single Transformer block, specifically to achieve highly efficient incremental token integration.
7.AniPortrait: Audio-Driven Synthesis of Photorealistic Portrait Animation ( paper | code )
In this study, we propose AniPortrait, a novel framework for generating high-quality animation driven by audio and a reference portrait image. Our methodology is divided into two stages. Initially, we extract 3D intermediate representations from audio and project them into a sequence of 2D facial landmarks.

8.StreamingT2V: Consistent, Dynamic, and Extendable Long Video Generation from Text ( paper )
Text-to-video diffusion models enable the generation of high-quality videos that follow text instructions, making it easy to create diverse and individual content. However, existing approaches mostly focus on high-quality short video generation (typically 16 or 24 frames), ending up with hard-cuts when naively extended to the case of long video synthesis. To overcome these limitations, we introduce StreamingT2V, an autoregressive approach for long video generation of 80, 240, 600, 1200 or more frames with smooth transitions.
9.TextCraftor: Your Text Encoder Can be Image Quality Controller ( paper )
Diffusion-based text-to-image generative models, e.g., Stable Diffusion, have revolutionized the field of content generation, enabling significant advancements in areas like image editing and video synthesis. Despite their formidable capabilities, these models are not without their limitations. It is still challenging to synthesize an image that aligns well with the input text, and multiple runs with carefully crafted prompts are required to achieve satisfactory results. To mitigate these limitations, numerous studies have endeavored to fine-tune the pre-trained diffusion models, i.e., UNet, utilizing various technologies. Yet, amidst these efforts, a pivotal question of text-to-image diffusion model training has remained largely unexplored: Is it possible and feasible to fine-tune the text encoder to improve the performance of text-to-image diffusion models? Our findings reveal that, instead of replacing the CLIP text encoder used in Stable Diffusion with other large language models, we can enhance it through our proposed fine-tuning approach, TextCraftor, leading to substantial improvements in quantitative benchmarks and human assessments.

10. LLM2LLM: Boosting LLMs with Novel Iterative Data Enhancement ( paper | code )
Pretrained large language models (LLMs) are currently state-of-the-art for solving the vast majority of natural language processing tasks. While many real-world applications still require fine-tuning to reach satisfactory levels of performance, many of them are in the low-data regime, making fine-tuning challenging. To address this, we propose LLM2LLM, a targeted and iterative data augmentation strategy that uses a teacher LLM to enhance a small seed dataset by augmenting additional data that can be used for fine-tuning on a specific task.

AIGC News of the week(Mar 25- Mar 31)
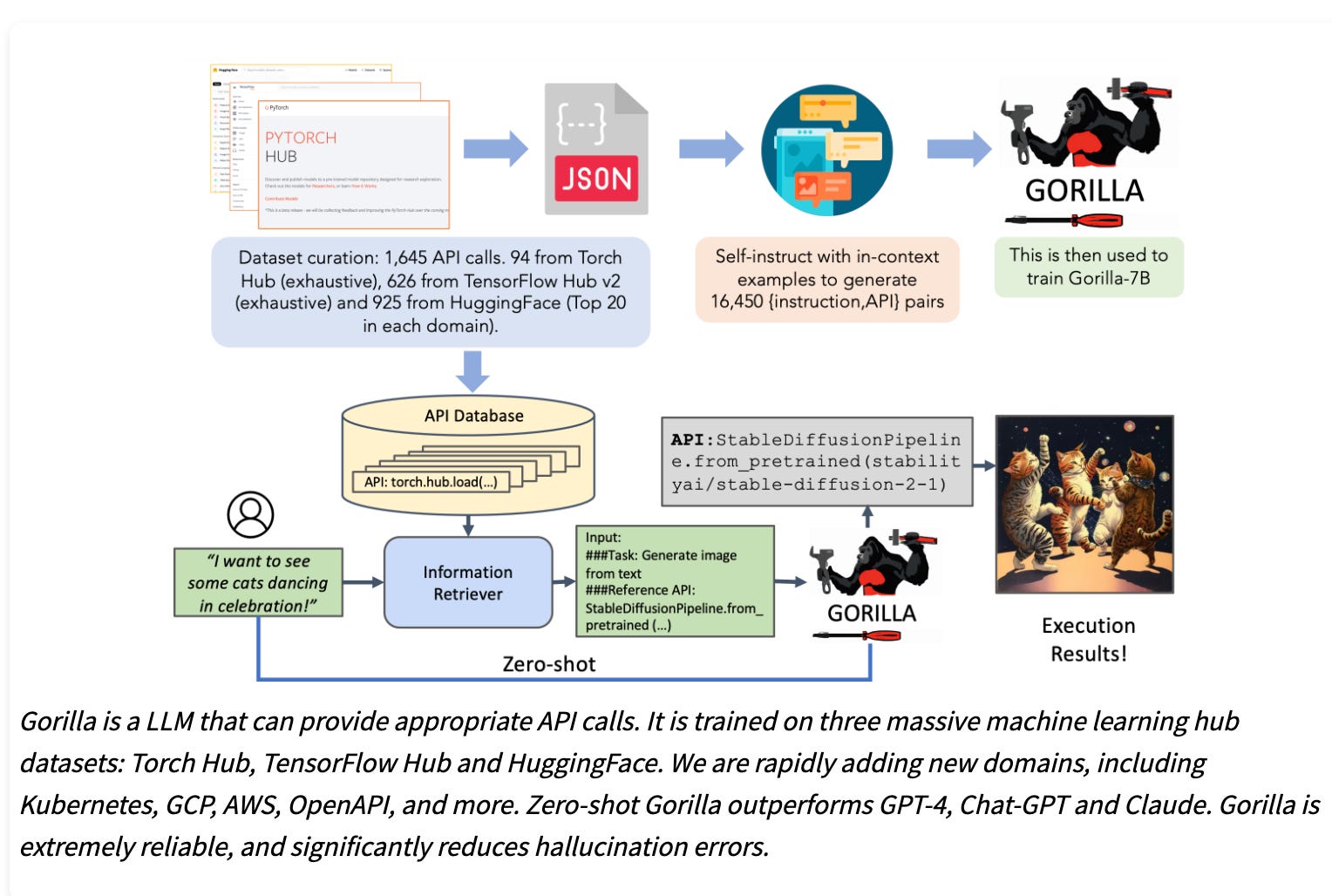
1.Gorilla: An API store for LLMs ( link )
2.Apple Set to Unveil AI Strategy at June 10 Developers Conference ( link )
3.Your AI Product Needs Evals ( link )
4.When Will the GenAI Bubble Burst? ( link )
5.llm-answer-engine:Build a Perplexity-Inspired Answer Engine ( link)

more AIGC News: AINews