



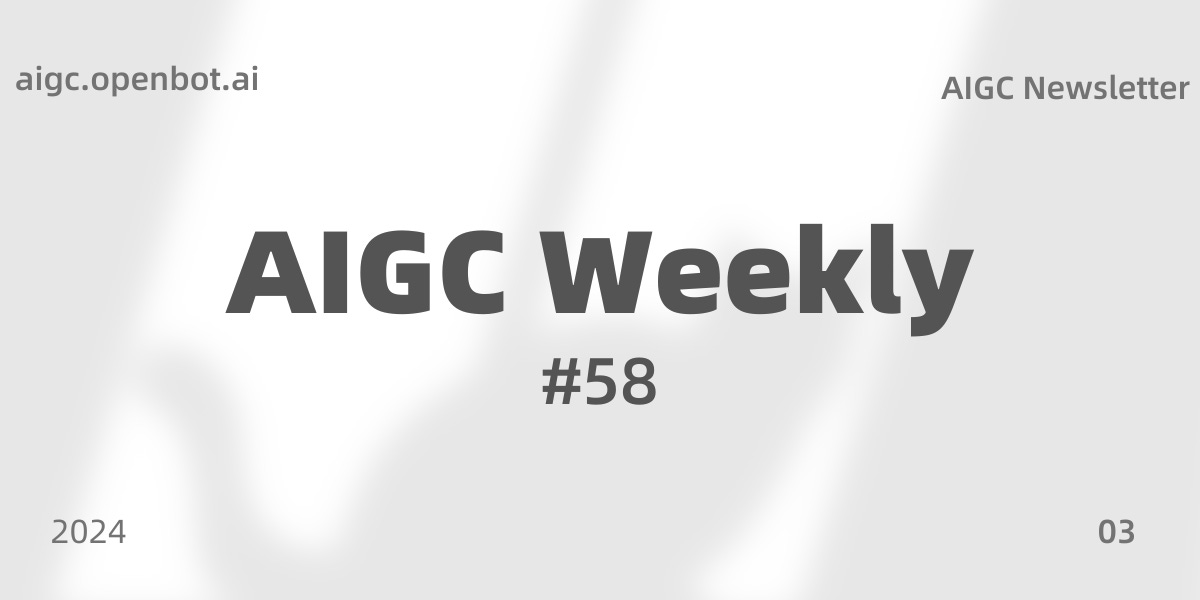
Top Papers of the week(Mar 4- Mar 10)
1.) The Claude 3 Model Family: Opus, Sonnet, Haiku ( webpage | paper )
We introduce Claude 3, a new family of large multimodal models – Claude 3 Opus, our most capable offering, Claude 3 Sonnet, which provides a combination of skills and speed, and Claude 3 Haiku, our fastest and least expensive model. All new models have vision capabilities that enable them to process and analyze image data.

2.) Scaling Rectified Flow Transformers for High-Resolution Image Synthesis ( paper )
Diffusion models create data from noise by inverting the forward paths of data towards noise and have emerged as a powerful generative modeling technique for high-dimensional, perceptual data such as images and videos. Rectified flow is a recent generative model formulation that connects data and noise in a straight line.

3.) Design2Code: How Far Are We From Automating Front-End Engineering? ( webpage | paper )
In this work, we formalize this as a Design2Code task and conduct comprehensive benchmarking. Specifically, we manually curate a benchmark of 484 diverse real-world webpages as test cases and develop a set of automatic evaluation metrics to assess how well current multimodal LLMs can generate the code implementations that directly render into the given reference webpages, given the screenshots as input.

4.) TripoSR: Fast 3D Object Reconstruction from a Single Image ( paper | model | code )
This technical report introduces TripoSR, a 3D reconstruction model leveraging transformer architecture for fast feed-forward 3D generation, producing 3D mesh from a single image in under 0.5 seconds. Building upon the LRM network architecture, TripoSR integrates substantial improvements in data processing, model design, and training techniques. Evaluations on public datasets show that TripoSR exhibits superior performance, both quantitatively and qualitatively, compared to other open-source alternatives. Released under the MIT license, TripoSR is intended to empower researchers, developers, and creatives with the latest advancements in 3D generative AI.

5.) ResAdapter: Domain Consistent Resolution Adapter for Diffusion Models ( webpage | paper )
Recent advancement in text-to-image models (e.g., Stable Diffusion) and corresponding personalized technologies (e.g., DreamBooth and LoRA) enables individuals to generate high-quality and imaginative images. However, they often suffer from limitations when generating images with resolutions outside of their trained domain. To overcome this limitation, we present the Resolution Adapter (ResAdapter), a domain-consistent adapter designed for diffusion models to generate images with unrestricted resolutions and aspect ratios. Unlike other multi-resolution generation methods that process images of static resolution with complex post-process operations, ResAdapter directly generates images with the dynamical resolution
6.) OOTDiffusion: Outfitting Fusion based Latent Diffusion for Controllable Virtual Try-on ( paper )
We present OOTDiffusion, a novel network architecture for realistic and controllable image-based virtual try-on (VTON). We leverage the power of pretrained latent diffusion models, designing an outfitting UNet to learn the garment detail features. Without a redundant warping process, the garment features are precisely aligned with the target human body via the proposed outfitting fusion in the self-attention layers of the denoising UNet. In order to further enhance the controllability, we introduce outfitting dropout to the training process, which enables us to adjust the strength of the garment features through classifier-free guidance.

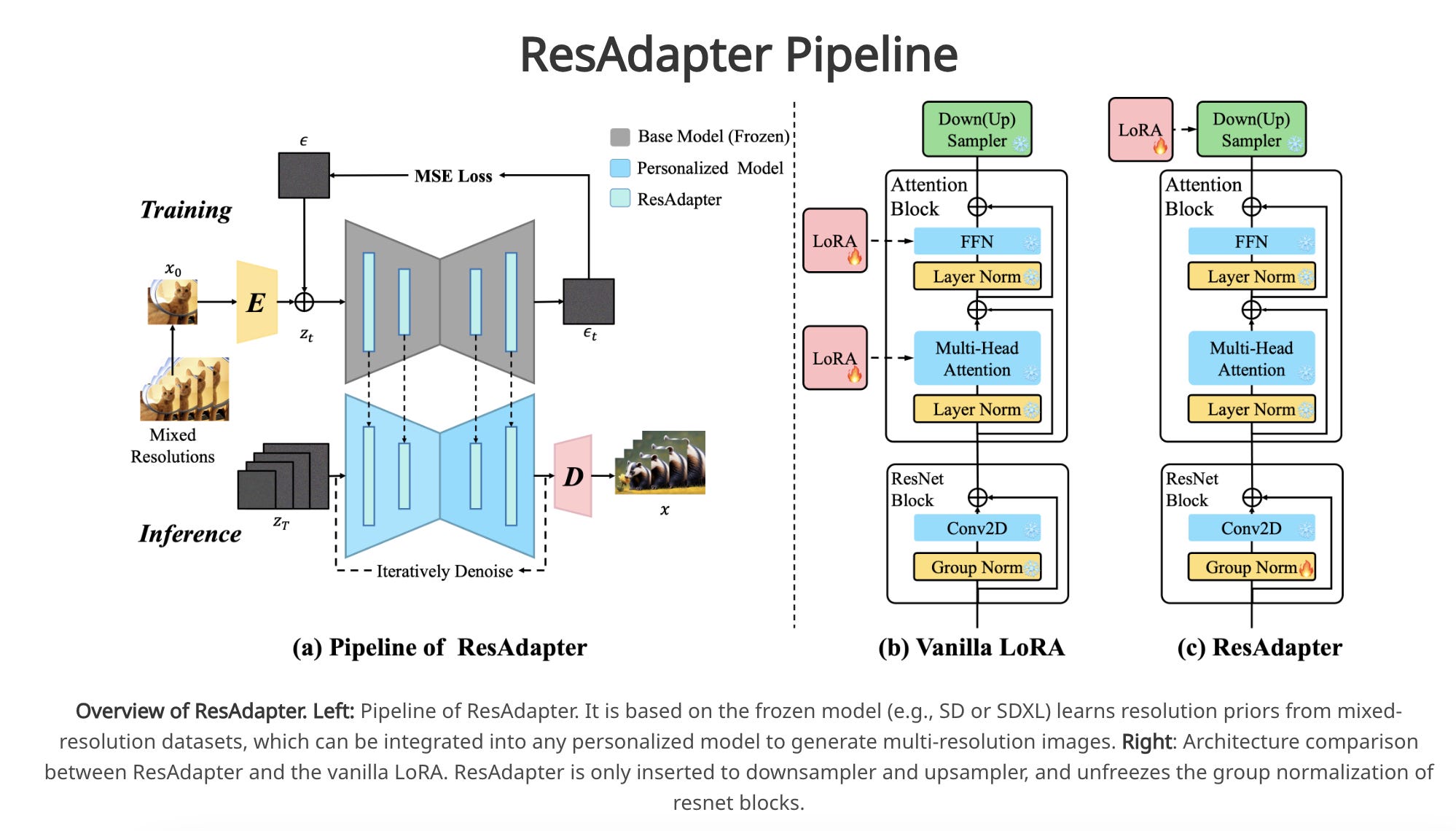
7.) Behavior Generation with Latent Actions (paper )
Generative modeling of complex behaviors from labeled datasets has been a longstanding problem in decision making. Unlike language or image generation, decision making requires modeling actions - continuous-valued vectors that are multimodal in their distribution, potentially drawn from uncurated sources, where generation errors can compound in sequential prediction. A recent class of models called Behavior Transformers (BeT) addresses this by discretizing actions using k-means clustering to capture different modes. However, k-means struggles to scale for high-dimensional action spaces or long sequences, and lacks gradient information, and thus BeT suffers in modeling long-range actions. In this work, we present Vector-Quantized Behavior Transformer (VQ-BeT), a versatile model for behavior generation that handles multimodal action prediction, conditional generation, and partial observations.
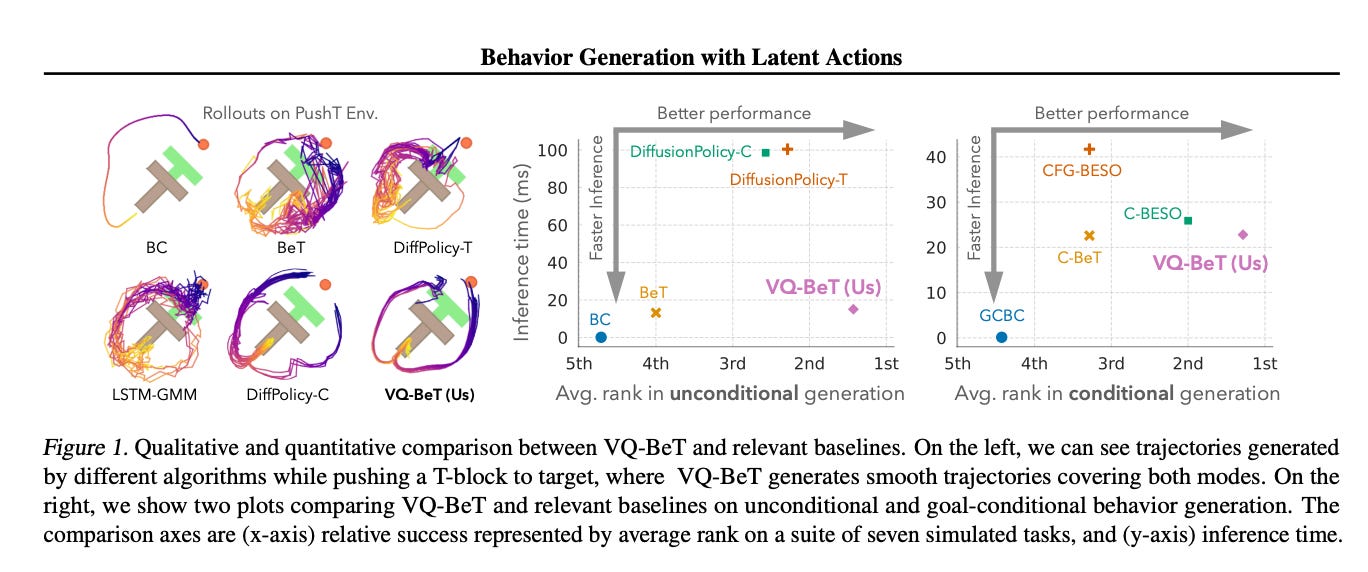
8.) LLMs in the Imaginarium: Tool Learning through Simulated Trial and Error ( paper )
Tools are essential for large language models (LLMs) to acquire up-to-date information and take consequential actions in external environments. Existing work on tool-augmented LLMs primarily focuses on the broad coverage of tools and the flexibility of adding new tools. However, a critical aspect that has surprisingly been understudied is simply how accurately an LLM uses tools for which it has been trained. We find that existing LLMs, including GPT-4 and open-source LLMs specifically fine-tuned for tool use, only reach a correctness rate in the range of 30% to 60%, far from reliable use in practice.
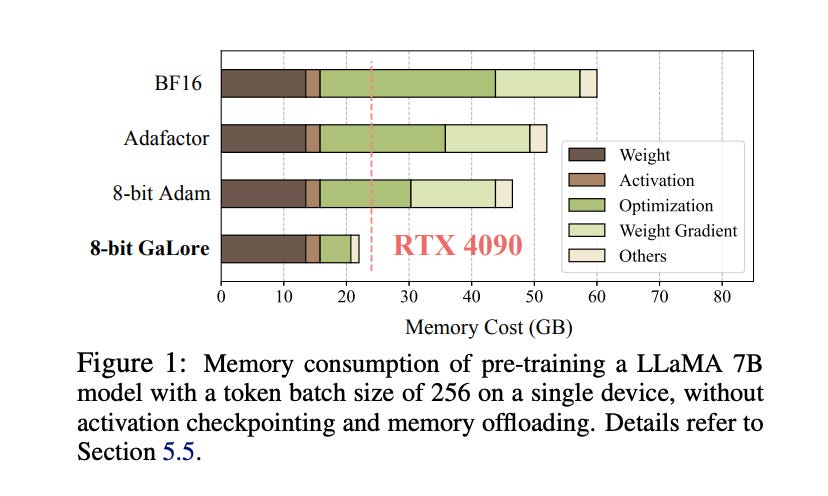
9.) GaLore: Memory-Efficient LLM Training by Gradient Low-Rank Projection ( paper | code )
Training Large Language Models (LLMs) presents significant memory challenges, predominantly due to the growing size of weights and optimizer states. Common memory-reduction approaches, such as low-rank adaptation (LoRA), add a trainable low-rank matrix to the frozen pre-trained weight in each layer, reducing trainable parameters and optimizer states. However, such approaches typically underperform training with full-rank weights in both pre-training and fine-tuning stages since they limit the parameter search to a low-rank subspace and alter the training dynamics, and further, may require full-rank warm start. In this work, we propose Gradient Low-Rank Projection (GaLore), a training strategy that allows full-parameter learning but is more memory-efficient than common low-rank adaptation methods such as LoRA.
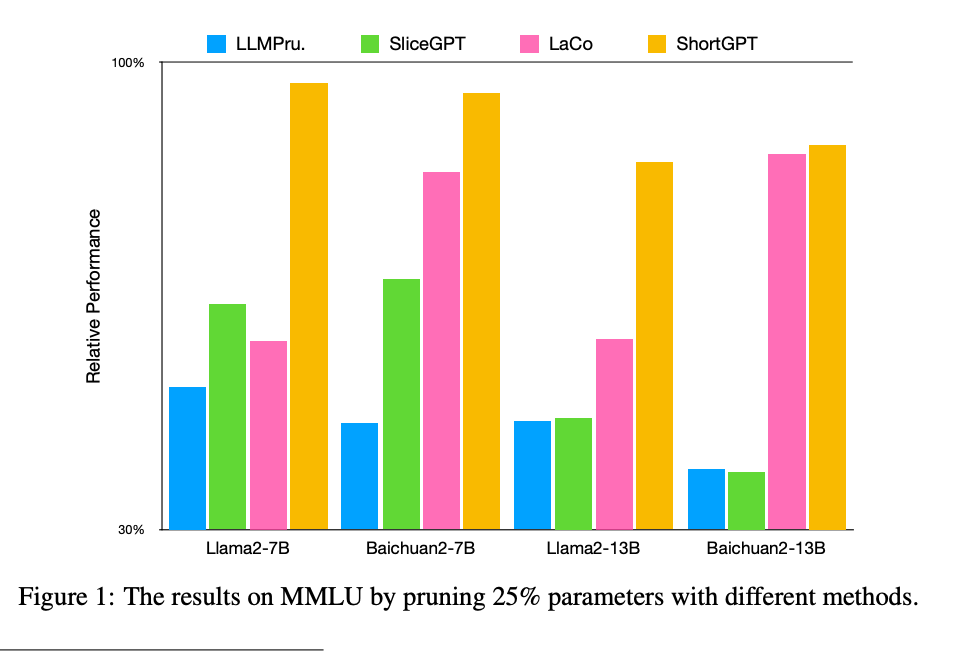
10.) ShortGPT: Layers in Large Language Models are More Redundant Than You Expect ( paper )
As Large Language Models (LLMs) continue to advance in performance, their size has escalated significantly, with current LLMs containing billions or even trillions of parameters. However, in this study, we discovered that many layers of LLMs exhibit high similarity, and some layers play a negligible role in network functionality. Based on this observation, we define a metric called Block Influence (BI) to gauge the significance of each layer in LLMs. We then propose a straightforward pruning approach: layer removal, in which we directly delete the redundant layers in LLMs based on their BI scores.
AIGC News of the week(Mar 4- Mar 10)
1.OpenAI and Elon Musk( link )

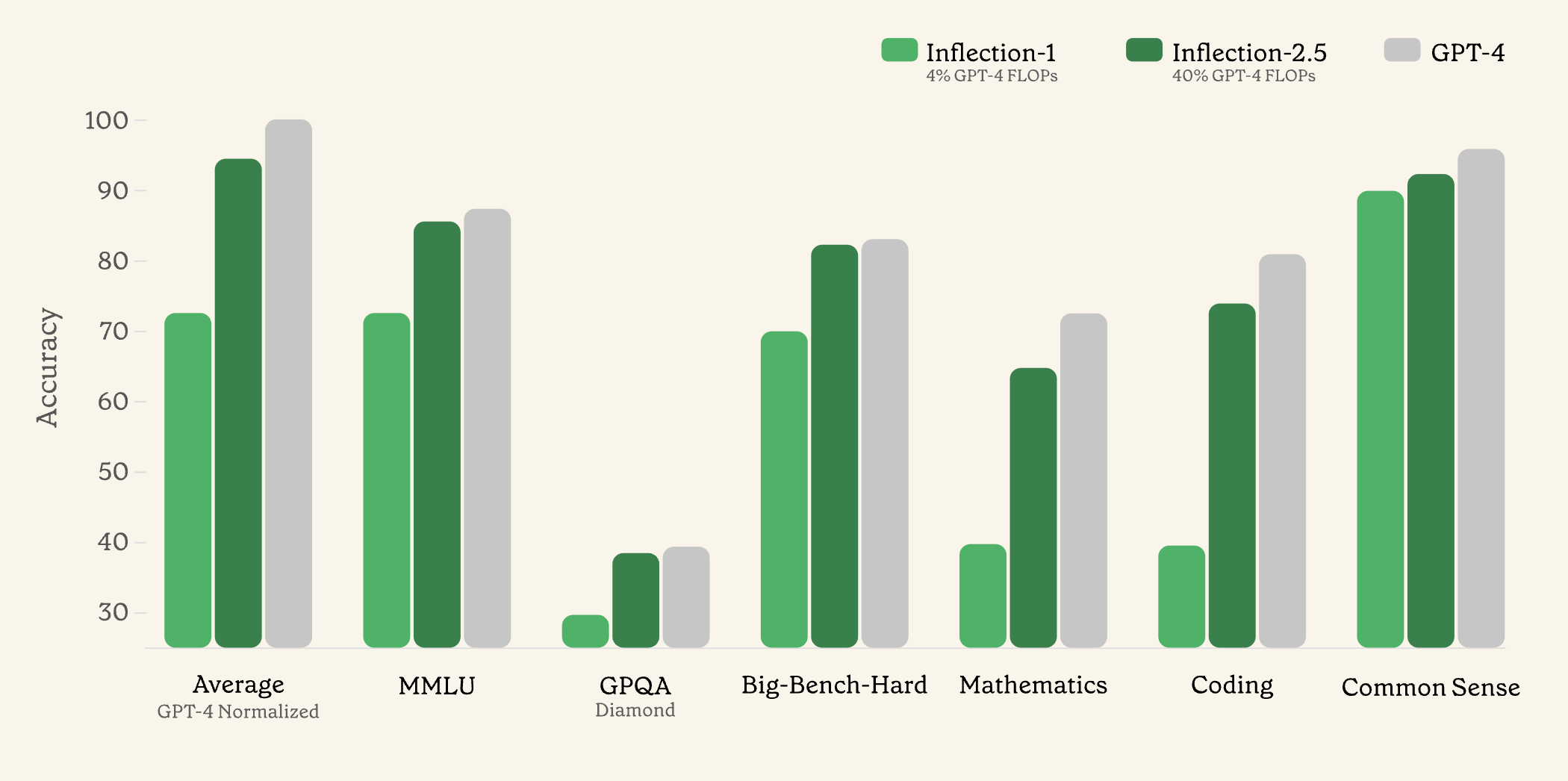
2.Inflection-2.5: meet the world's best personal AI ( link )
3.) In China, differing views on AI from the founder of a LLM company and an investor have sparked a major discussion

4.) MovieLLM: Enhancing Long Video Understanding with AI-Generated Movies ( link )

5.Paper-Piano( link )