Top Papers of the week(Feb 26- Mar 3)
1). Genie: Generative Interactive Environments ( webpage, paper )
![[paper] DeepMind Genie: Generative Interactive Environments](https://substackcdn.com/image/fetch/w_280,h_280,c_fill,f_webp,q_auto:good,fl_progressive:steep,g_auto/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2F051df237-fa87-44c6-b13b-236088326a50_1250x1388.png)
2). EMO: Emote Portrait Alive -- Generating Expressive Portrait Videos with Audio2Video Diffusion Model under Weak Conditions ( webpage, paper )
We proposed EMO, an expressive audio-driven portrait-video generation framework. Input a single reference image and the vocal audio, e.g. talking and singing, our method can generate vocal avatar videos with expressive facial expressions, and various head poses, meanwhile, we can generate videos with any duration depending on the length of input video.
3). The Era of 1-bit LLMs: All Large Language Models are in 1.58 Bits ( paper )
Recent research, such as BitNet, is paving the way for a new era of 1-bit Large Language Models (LLMs). In this work, we introduce a 1-bit LLM variant, namely BitNet b1.58, in which every single parameter (or weight) of the LLM is ternary {-1, 0, 1}. It matches the full-precision (i.e., FP16 or BF16) Transformer LLM with the same model size and training tokens in terms of both perplexity and end-task performance, while being significantly more cost-effective in terms of latency, memory, throughput, and energy consumption. More profoundly, the 1.58-bit LLM defines a new scaling law and recipe for training new generations of LLMs that are both high-performance and cost-effective. Furthermore, it enables a new computation paradigm and opens the door for designing specific hardware optimized for 1-bit LLMs.

4.) StarCoder 2 and The Stack v2: The Next Generation ( webpage, paper )
The BigCode project,1 an open-scientific collaboration focused on the responsible development of Large Language Models for Code (Code LLMs), introduces StarCoder2. In partnership with Software Heritage (SWH),2 we build The Stack v2 on top of the digital commons of their source code archive. Alongside the SWH repositories spanning 619 programming languages, we carefully select other high-quality data sources, such as GitHub pull requests, Kaggle notebooks, and code documentation. This results in a training set that is 4× larger than the first StarCoder dataset. We train StarCoder2 models with 3B, 7B, and 15B parameters on 3.3 to 4.3 trillion tokens and thoroughly evaluate them on a comprehensive set of Code LLM benchmarks.

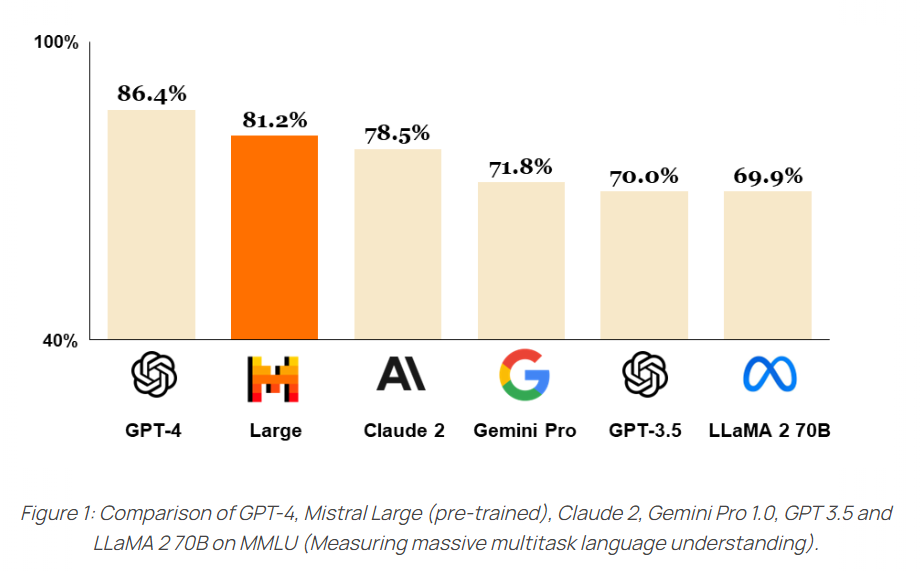
5.) Mistral Large ( webpage)
Mistral Large achieves strong results on commonly used benchmarks, making it the world's second-ranked model generally available through an API (next to GPT-4)
6.) Datasets for Large Language Models: A Comprehensive Survey (webpage, paper)
This paper embarks on an exploration into the Large Language Model (LLM) datasets, which play a crucial role in the remarkable advancements of LLMs. The datasets serve as the foundational infrastructure analogous to a root system that sustains and nurtures the development of LLMs.

7.) Beyond Language Models: Byte Models are Digital World Simulators ( webpage, paper )
Traditional deep learning often overlooks bytes, the basic units of the digital world, where all forms of information and operations are encoded and manipulated in binary format. Inspired by the success of next token prediction in natural language processing, we introduce bGPT, a model with next byte prediction to simulate the digital world.

8.) MegaScale: Scaling Large Language Model Training to More Than 10,000 GPUs( paper )
We present the design, implementation and engineering experience in building and deploying MegaScale, a production system for training large language models (LLMs) at the scale of more than 10,000 GPUs. Training LLMs at this scale brings unprecedented challenges to training efficiency and stability.

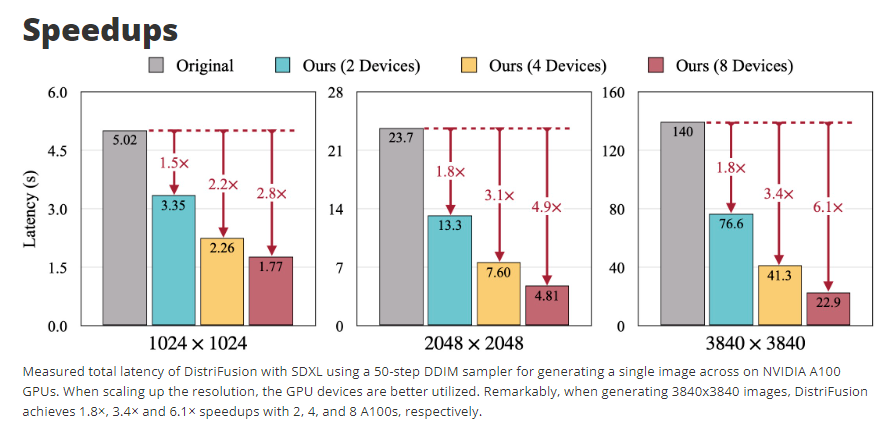
9.) DistriFusion: Distributed Parallel Inference for High-Resolution Diffusion Models ( webpage, paper, code )
Diffusion models have achieved great success in synthesizing high-quality images. However, generating high-resolution images with diffusion models is still challenging due to the enormous computational costs, resulting in a prohibitive latency for interactive applications. In this paper, we propose DistriFusion to tackle this problem by leveraging parallelism across multiple GPUs.
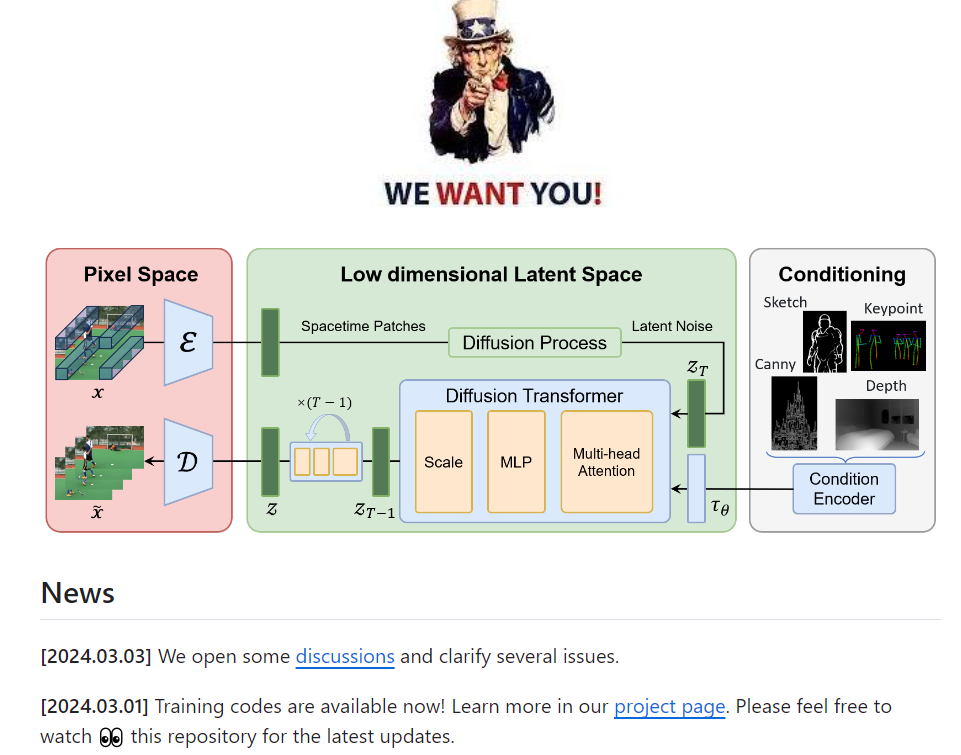
10.) Sora: A Review on Background, Technology, Limitations, and Opportunities of Large Vision Models ( paper )
Sora is a text-to-video generative AI model, released by OpenAI in February 2024. The model is trained to generate videos of realistic or imaginative scenes from text instructions and show potential in simulating the physical world. Based on public technical reports and reverse engineering, this paper presents a comprehensive review of the model's background, related technologies, applications, remaining challenges, and future directions of text-to-video AI models.

AIGC News of the week(Feb 26- Mar 3)
1.) The Foundation Model Development Cheatsheet ( link )

2.) sd-forge-layerdiffusion ( link )

3.) Deep-Reinforcement-Learning-Algorithms-with-Pytorch (link)

4.) face-to-sticker:Turn any face into a sticker ( link )

5.) Open-Sora-Plan( webpage, link )