




Top Papers of the week(Feb 19- Feb 25)
1.) Gemma: Introducing new state-of-the-art open models ( webpage | dev | huggingface )

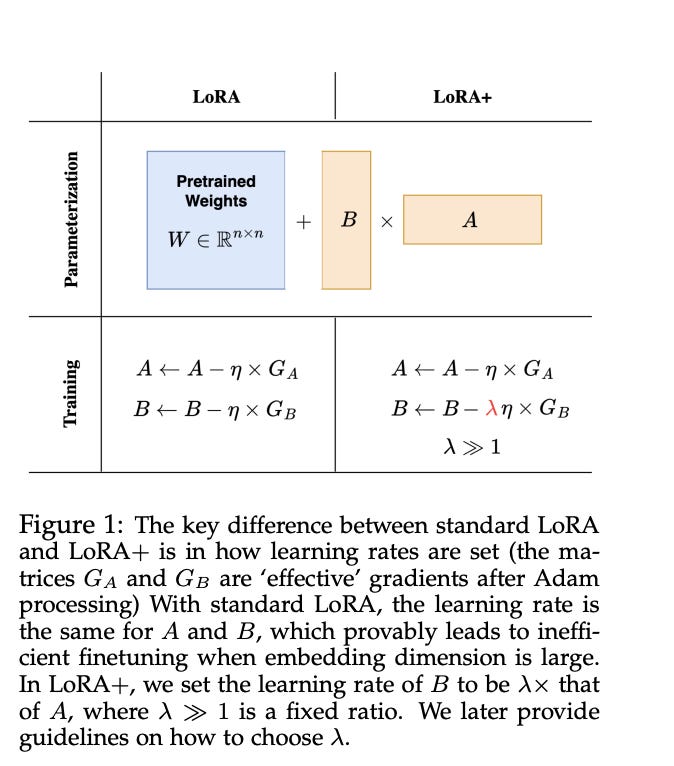
2.) LoRA+: Efficient Low Rank Adaptation of Large Models ( paper )
In our extensive experiments, LoRA+ improves performance (1-2 % improvements) and finetuning speed (up to ∼ 2X SpeedUp), at the same computational cost as LoRA.
3.) SDXL-Lightning: Progressive Adversarial Diffusion Distillation ( paper )
We propose a diffusion distillation method that achieves new state-of-the-art in one-step/few-step 1024px text-to-image generation based on SDXL. Our method combines progressive and adversarial distillation to achieve a balance between quality and mode coverage. In this paper, we discuss the theoretical analysis, discriminator design, model formulation, and training techniques. We open-source our distilled SDXL-Lightning models both as LoRA and full UNet weights.

4.) OpenCodeInterpreter: Integrating Code Generation with Execution and Refinement ( paper )
The introduction of large language models has significantly advanced code generation. However, open-source models often lack the execution capabilities and iterative refinement of advanced systems like the GPT-4 Code Interpreter. To address this, we introduce OpenCodeInterpreter, a family of open-source code systems designed for generating, executing, and iteratively refining code.
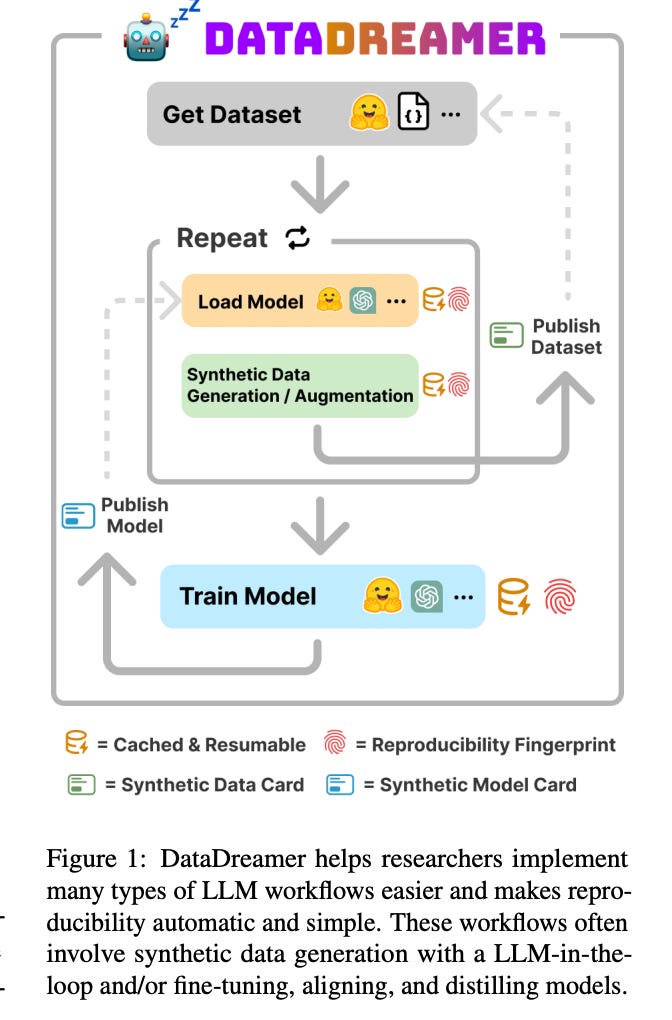
5.) DataDreamer: A Tool for Synthetic Data Generation and Reproducible LLM Workflows ( paper )
Large language models (LLMs) have become a dominant and important tool for NLP researchers in a wide range of tasks. Today, many researchers use LLMs in synthetic data generation, task evaluation, fine-tuning, distillation, and other model-in-the-loop research workflows.
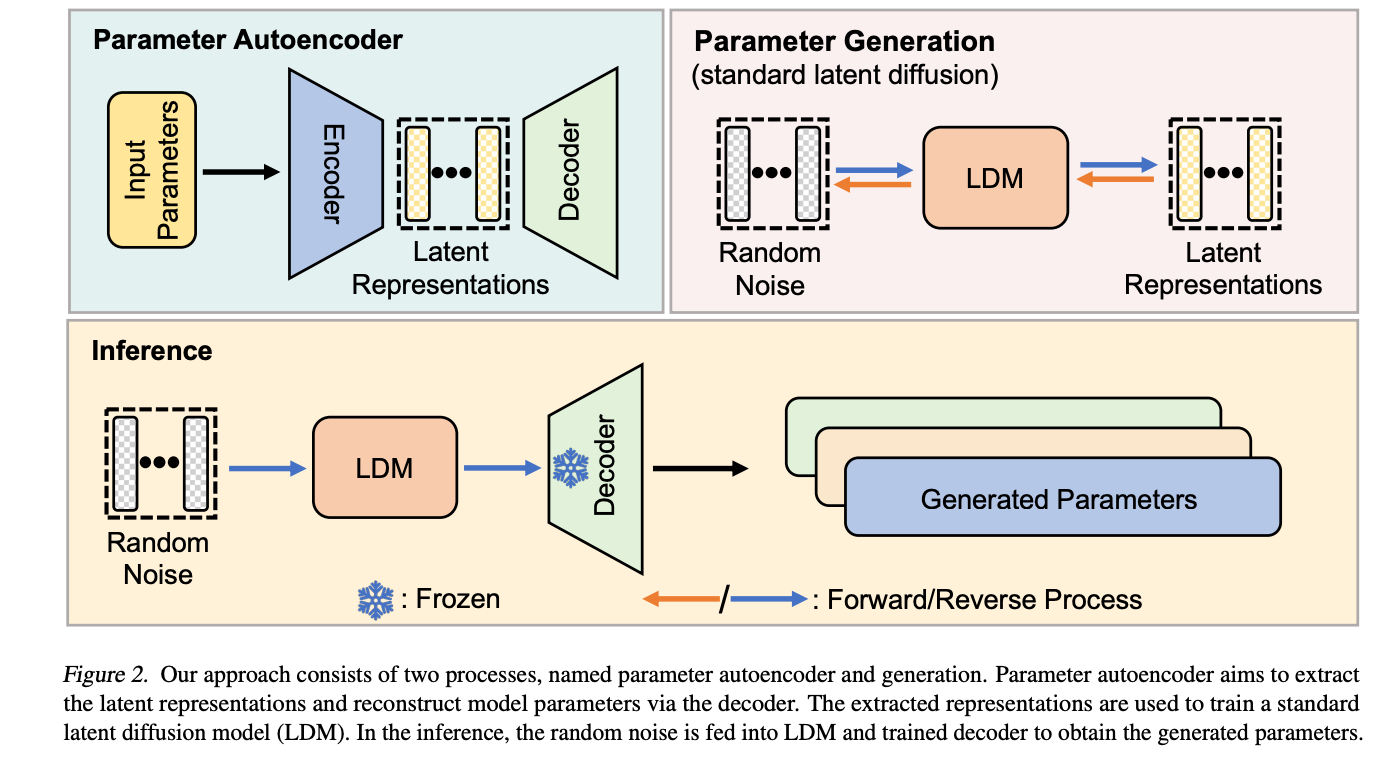
6.) Neural Network Diffusion (paper )
Diffusion models have achieved remarkable success in image and video generation. In this work, we demonstrate that diffusion models can also generate high-performing neural network parameters.
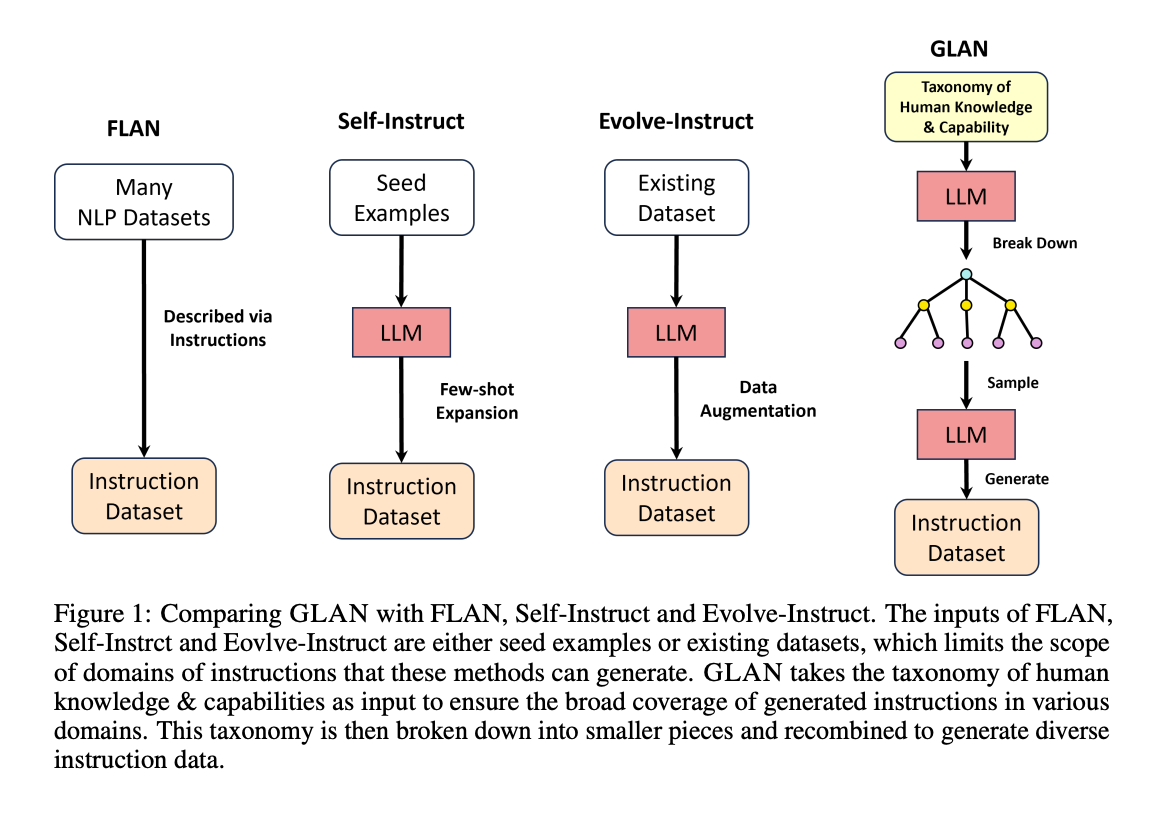
7.) Synthetic Data (Almost) from Scratch: Generalized Instruction Tuning for Language Models ( paper )
We introduce Generalized Instruction Tuning (called GLAN), a general and scalable method for instruction tuning of Large Language Models (LLMs).
8.) Large Language Models for Data Annotation: A Survey ( paper )
Data annotation is the labeling or tagging of raw data with relevant information, essential for improving the efficacy of machine learning models. The process, however, is labor-intensive and expensive. The emergence of advanced Large Language Models (LLMs), exemplified by GPT-4, presents an unprecedented opportunity to revolutionize and automate the intricate process of data annotation.
9.) When is Tree Search Useful for LLM Planning? It Depends on the Discriminator ( paper )
In this paper, we examine how large language models (LLMs) solve multi-step problems under a language agent framework with three components: a generator, a discriminator, and a planning method. We investigate the practical utility of two advanced planning methods, iterative correction and tree search.
AIGC News of the week(Feb 19- Feb 25)
1.) Google pauses AI image generation of people after diversity backlash ( link )
2.) Reddit Signs AI Content Licensing Deal Ahead of IPO ( link )
3.) Stable Diffusion 3 ( webpage )

4.) Give Feedback to GPTs ( link )
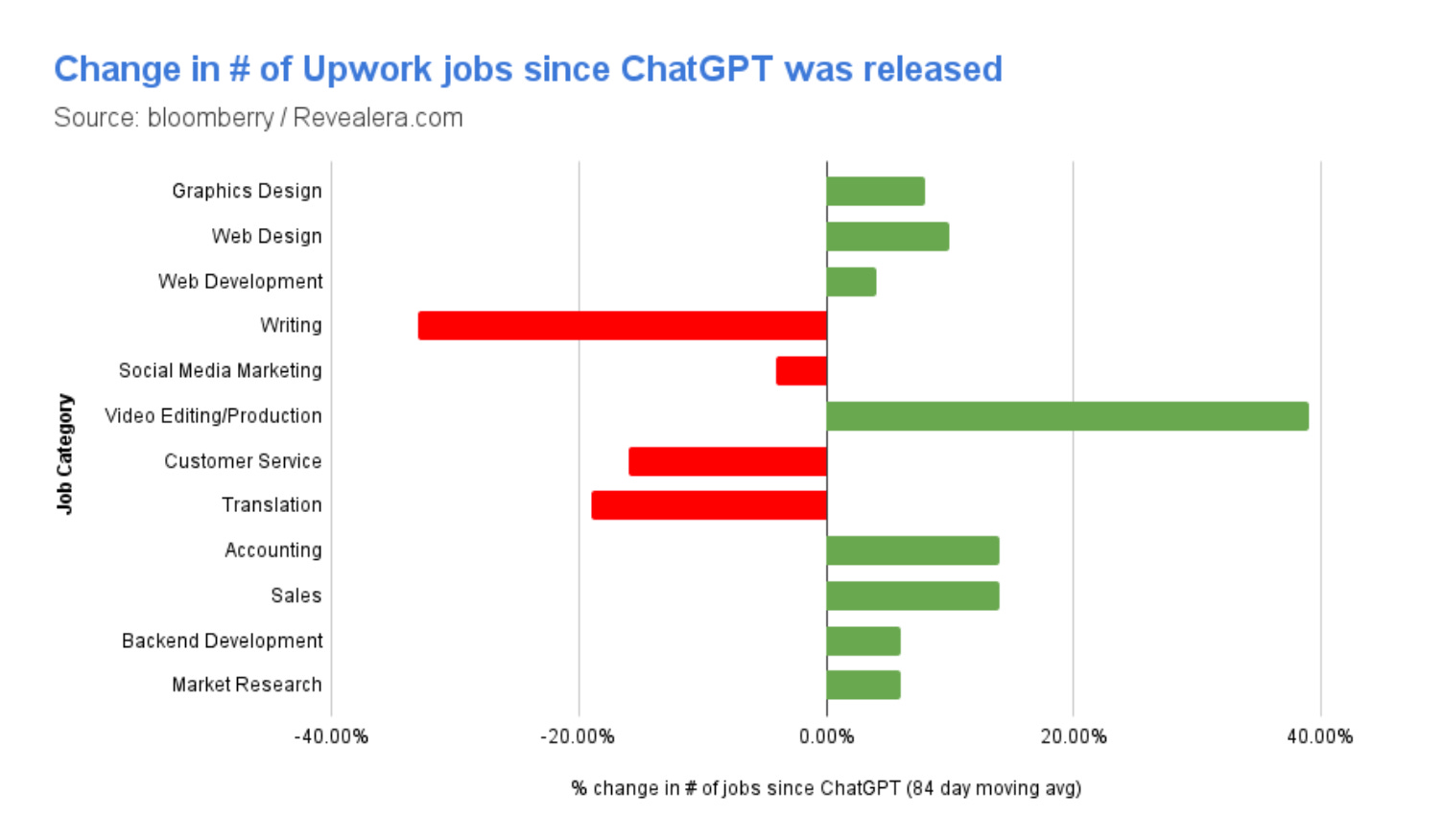
5.) I analyzed 5M freelancing jobs to see what jobs are being replaced by AI ( link )
6.) Andrej Karpathy:Let's build the GPT Tokenizer ( link)