



Top Papers of the week(Jan 22- Jan 28)
1). Depth Anything: Unleashing the Power of Large-Scale Unlabeled Data( paper | webpage)
"Depth Anything" is a robust monocular depth estimation model that leverages a vast dataset of unlabeled images to enhance generalization. By scaling up data coverage and employing data augmentation and semantic priors, it achieves impressive zero-shot performance across diverse datasets. Fine-tuning with metric depth further improves results, setting new benchmarks in depth estimation and demonstrating its potential as a versatile multi-task encoder.
2). WebVoyager: Building an End-to-End Web Agent with Large Multimodal Models( paper )
"WebVoyager" introduces an end-to-end web agent powered by large multimodal models, capable of autonomously completing user-given tasks on real-world websites. The agent integrates visual and textual information from screenshots and web elements, achieving a 55.7% task success rate, outperforming text-only and GPT-4 (All Tools) baselines. The paper also proposes an automated evaluation protocol using GPT-4V, demonstrating its potential for real-world web agent development.
3). CreativeSynth: Creative Blending and Synthesis of Visual Arts based on Multimodal Diffusion( paper )
"CreativeSynth" is a novel framework for artistic image generation and editing that integrates multimodal inputs, such as text and images, to create personalized digital art. It preserves the original artistic style and aesthetic while allowing for precise manipulation of image style, enabling applications like image variation, editing, style transfer, fusion, and multimodal blending. The framework leverages advanced mechanisms for aesthetic maintenance and semantic fusion, achieving high-fidelity and aesthetically coherent results.
4). MambaByte: Token-free Selective State Space Model ( paper )
"MambaByte" introduces a token-free language model that operates directly on raw bytes, addressing the limitations of subword tokenization. The model, based on the Mamba state space model, demonstrates computational efficiency and competitive performance with subword Transformers, advocating for end-to-end learning without tokenization.
5). Lumiere: A Space-Time Diffusion Model for Video Generation ( paper | webpage)
"Lumiere" introduces a text-to-video diffusion model that generates coherent, high-quality videos. It uses a Space-Time U-Net architecture to process videos in space and time, avoiding temporal super-resolution cascades. The model demonstrates state-of-the-art results in text-to-video generation and supports various video editing applications.
6). Large Language Models are Superpositions of All Characters: Attaining Arbitrary Role-play via Self-Alignment( paper | webpage )
"DITTO" introduces a self-alignment method for role-play in large language models (LLMs), enabling them to simulate characters without relying on proprietary models. It uses character knowledge from Wikidata and Wikipedia to generate role-play datasets, fine-tuning LLMs to improve their role-playing capabilities. The method achieves state-of-the-art performance, comparable to advanced proprietary chatbots, and provides insights into the role-play capabilities of LLMs.
7). Meta-Prompting: Enhancing Language Models with Task-Agnostic Scaffolding ( paper )
"Meta-Prompting" introduces a scaffolding technique to enhance language models (LMs) by transforming a single LM into a conductor that manages multiple expert instances. This approach guides the LM to break down complex tasks, assigns subtasks to specialized experts, and integrates their outputs. Meta-prompting significantly improves performance across various tasks, especially when combined with a Python interpreter, demonstrating its versatility and robustness.
8). Red Teaming Visual Language Models( paper )
This paper introduces RTVLM, a novel dataset for evaluating visual language models' resilience to red teaming attacks, focusing on faithfulness, privacy, safety, and fairness. It reveals vulnerabilities in current VLMs and proposes solutions for enhancing model security.
9). Medusa: Simple LLM Inference Acceleration Framework with Multiple Decoding Heads ( paper )
MEDUSA is a framework for accelerating LLM inference by adding multiple decoding heads to predict tokens in parallel, reducing decoding steps and improving speed without compromising quality. It offers two fine-tuning levels, MEDUSA-1 for lossless inference and MEDUSA-2 for enhanced prediction accuracy. Experiments show 2.3-3.6× speedup across various models and tasks.
10). Matryoshka Representation Learning( paper )
Matryoshka Representation Learning (MRL) introduces flexible representations that adapt to varying computational resources for downstream tasks. It enables adaptive deployment with up to 14× smaller embeddings for ImageNet-1K classification and 14× real-world speed-ups for large-scale retrieval, while maintaining accuracy and robustness. MRL is seamlessly extensible across modalities and web-scale datasets.
AIGC News of the week(Jan 22- Jan 28)
1). OpenAI: New embedding models and API updates ( link )
OpenAI is launching new embedding models, an updated GPT-4 Turbo preview, and a new GPT-3.5 Turbo model. They are also introducing lower pricing on GPT-3.5 Turbo and new API usage management tools. The new models include text-embedding-3-small and text-embedding-3-large, which offer improved performance and reduced pricing. The company is also updating its moderation model and providing new ways for developers to manage API keys and understand usage.
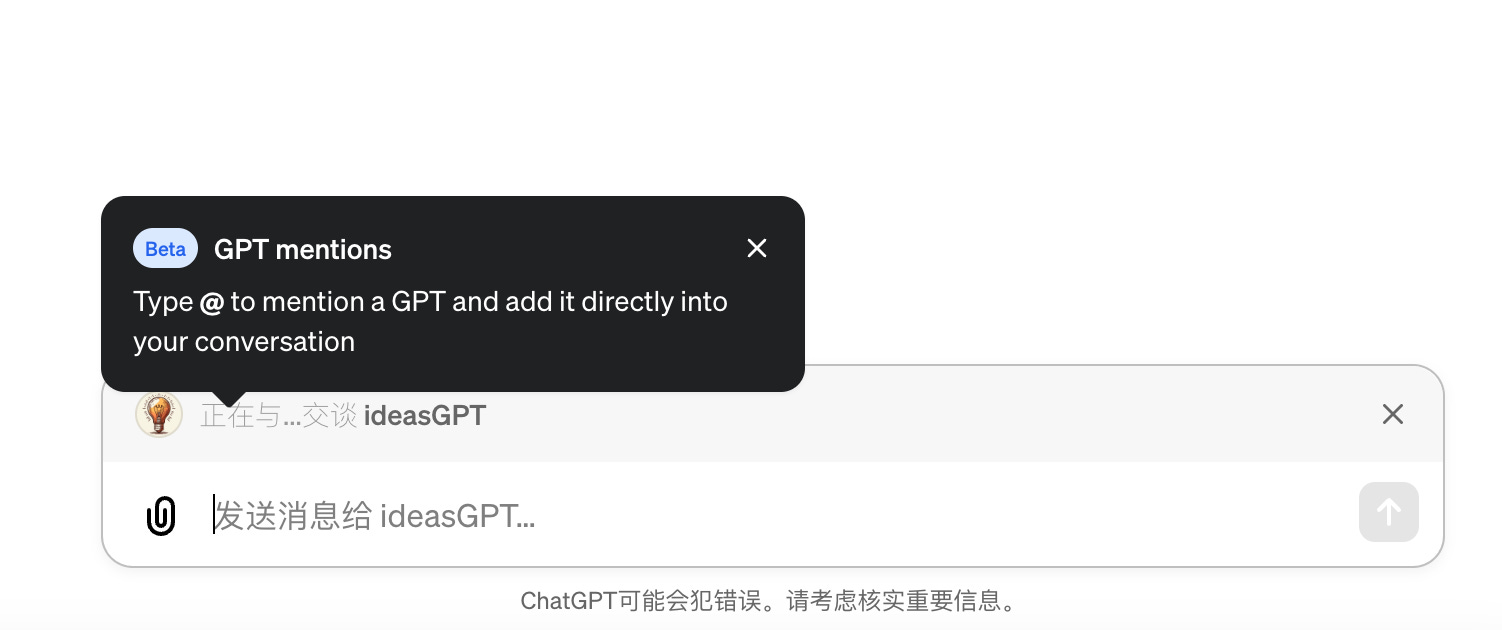
2). OpenAI introduces GPT mentions
OpenAI just quietly shipped a new ‘GPT mentions’ feature to ChatGPT, allowing users to seamlessly integrate custom bots into a conversation by tagging them in a Slack-type style.
3). Microsoft:The New Future of Work 2023 ( link )
The New Future of Work initiative by Microsoft Research aims to create solutions for a meaningful, productive, and equitable future of work. It began during the pandemic to understand remote work practices and has since shifted focus to supporting hybrid work transitions. The initiative is now entering a new chapter with artificial intelligence, particularly generative AI, which has the potential to transform work practices. The site features research published in peer-reviewed journals and resources to navigate the changing work environment. Microsoft has also funded academic projects on the use of Large Language Models (LLMs) in productivity scenarios and launched WorkLab to provide insights on connecting, creating, and unlocking ingenuity in the age of AI.
4). Apple aims to run AI models directly on iPhones, other devices( link )
5). Chrome is getting 3 new generative AI features ( link )